- rationales:基本原理
- discourse:语篇
- anticlimax: 虎头蛇尾
- prevail: 流行
- hedging: 模糊的
- bjectivity: 客观的
1 Overview
1-1 Register
register 语域:写作、演讲风格,代表了语言正式的程度
5 Registers
- Static (frozen) 套话
- Formal (regulated)
- Consultative (professional/ academic) 商议的
- Casual (group)
- Personal (intimate)
1-2 Title
S.C.I:
- specific
- concise
- informative
HOW:
- Choose a topic: interesting
- Narrow down: specific
- Paraphrase: noun phrase
1-3 Nominalization 名词化
Why
- increase information density and facilitate efficiency and accuracy of communication.
- express abstract concepts (e.g., revolution, possibility) 描述抽象概念
- hide the agent behind an action
- improve flow of writing , maintain connections between ideas
- make writing more “written” and professional
How:
- a simple sentence
- nominalized subject
- second verb
- finisher idea
1-4 Personal Pronouns
并非完全不能用第一人称
Avoid first and second person pronouns to be impersonal and scientific
Use gender-fair language
- Use "he or she" or "a person" instead of "he"
1-5 Word Choice and Sentence Variety
1-5-1 Word choice
Abstract and concrete words
- Abstract: loyal, love
- Concrete: battle, horse
Generral and specific words
- general: tree
- specific: southern red oak
Denotation and connotation
指示词(客观)和内涵词(带感情色彩的词)
| denotation | connotation |
|---|---|
| primary or literal meaning | secondary or implied meanings |
| exact or surface | baggage or associations |
| tip of iceberg | impart the most meaning |
| e.g. "house" | e.g. "home" |
Figurative speech
生动性
employs figures of speech
- simile,明喻
- metaphor,隐喻
- personification,拟人
Choose appropriate vocabulary
- Avoid using unfamiliar synonyms 避免使用生僻的同义词,不要装逼
- Avoid slang 避免俚语
- Avoid wordiness 避免冗长
1-5-2 Sentence variety
四种基础句式:
- 简单句
- 并列句
- 复合句
- 并列复合句
2 Literature Review
- Information prominent citation:作者待在括号里
- Author prominent citation:作者是主语
- Weak author prominent citation:authors 是主语,一群作者待在括号里
2-1 Reviewing Literature
A literature review is a careful examination of a body of literature pointing toward the answer to your research question.
Include a critical analysis of various opinions from credible sources
2-2 Writing Literature Review
简单文献综述模型:
- 研究兴趣
- 研究话题
- 文献综述
- 研究论文
复杂文献综述模型:在简单模型的基础上增加
- 研究问题
- 研究项目
顺序:
- Chronological(时间) - Trace the development of the topic over time
- Thematic(主题) - Address different aspects of the topic in subsections
- Methodological(方法) - Compare the results & conclusions from different approaches
- Theoretical(理论) - Discuss various theories, models, and definitions of key concepts.
技巧:
- introduction to topic
- support from the literature
- mini summary
- introduction to next topic.
2-3 Avoiding Plagiarism(剽窃)
方法:
- Quoting(引用)
- Paraphrasing(转写)
- Summarizing(概括)
2-4 Reporting Verbs
| Function and strength | Example verbs |
|---|---|
| NEUTRAL: verbs used to say what the writer describes in factual terms, demonstrates, refers to, and discusses, and verbs used to explain his/her methodology. | describe, show, reveal, study, demonstrate, note, point out, indicate, report, observe, assume, take into consideration, examine, go on to say that, state, believe (unless this is a strong belief), mention, etc. |
| TENTATIVE: verbs used to say what the writer suggests or speculates on (without being absolutely certain). | suggest, speculate, intimate, hypothesize, moot, imply, propose, recommend, posit the view that, question the view that, postulate, etc. |
| STRONG: verbs used to say what the writer makes strong arguments and claims for. | argue, claim, emphasize, contend, maintain, assert, theorize, support the view that, deny, negate, refute, reject, challenge, strongly believe that, counter the view/argument that, etc. |
2-5 Tenses in Literature review
常用一般现在时、现在完成时
一般现在时:陈述事实或者真理的东西
只有在以下情况可以用一般过去时:
- 主句出现年份、时间(不是括号)
- 提到废弃研究
3 Methods and Results
“限制条件”预防了数据失效
3-1 The Structure of the Method Section
==Different titles of the method section==
- Materials and Methods
- Theory and Methods
- Theoretical Framework and Methods
The major elements in the method section
- The method section
- Methodology
- The rationales
- The fundamental reasons or principles of doing things
- Steps
- Materials
避免抄袭:
- 感谢作者
- 熟悉实验设计和实施
- 好好引用
3-2 The Structure of the Results Section
Major elements
- The statement showing where the results can be found
- The statement presenting the most important findings
- The statement commenting on the results
The order of the results
- Research questions
- Research methods
The language focuses
- Sequential markers
- Graphic descriptions
- Comparison and contrast
3-3 Sequential Markers
Importance of sequential markers
- Building up connections between ideas
- Ensuring that sentences and paragraphs flow together smoothly

3-4 Graphic Description
Description of Graphs
- Introduce the graphic information briefly and indicate the main trend. Normally it includes the place, time, content and purpose of the graph;
- Describe the relevant and most important or signi ficant data and make some comparison if necessary;
- Summarize the data/trends
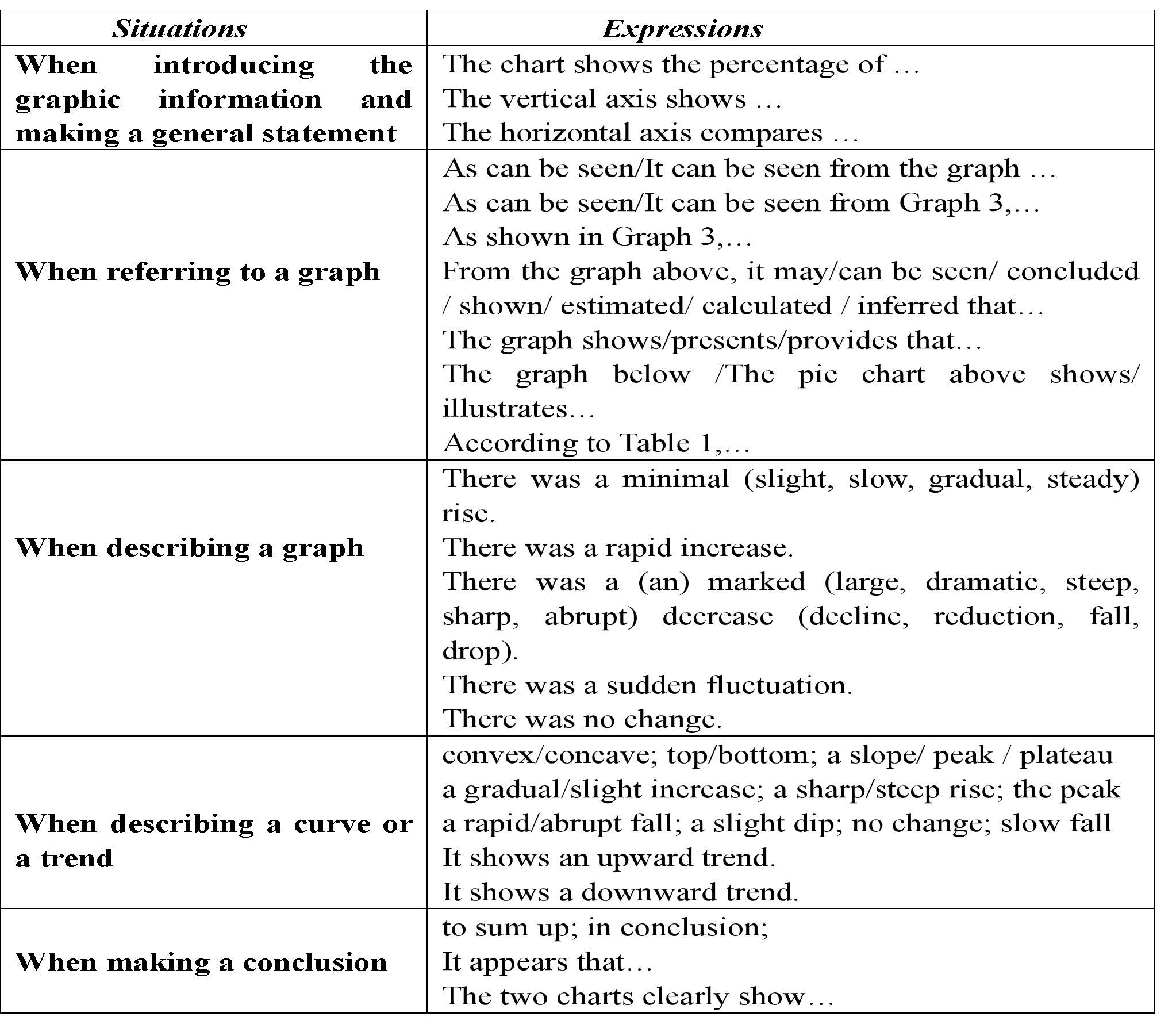
Expressions for highlighting significant data in a table/chart
- some adjectives such as “apparent”, “clear”, “interesting”, “obvious”, “revealing” and “significant”
3-5 Comparison and Contrast
- 比较:相同点
- 对比:不同点

Two major ways of organization:
- Block comparison or block contrast(分块对比)
- To examine one thing thoroughly and then examine the other
- Alternating comparison or alternating contrast(交替对比)
- To examine two things at the same time, discussing them point by point
Tips for making comparison or contrast
- Not all the information has to be compared or contrasted with each other.
- It is not necessary to lay equal emphasis on every change.
- The comparison/contrast should be supported by concrete and relevant facts or data.
4 Discussion & Conclusion
4-1 Structure of Discussion Section
7 elements the Discussion section typically contains:
- An overview ...
- A consideration ...
- Implications ...
- A careful examination ...
- Limitations ...
- Recommendations ...
- Implications ...
4-1-2 Strategies and steps to structure the Discussion
How to begin the Discussion
- Remind readers
- Refer back to the questions
- ==Refer back to papers==
- Briefly restate ... from your Results
How to compare my work with those of others
4-2 Structure of Conclusion Section
Key elements of Conclusions section:
- a very brief revisit of the most important findings ...
- a final judgment on the importance and significance of those findings ...
- an indication of the limitations ...
- suggestions for ...
- recommendations for ...
Typical issues in structuring the Conclusion
- Redundancy: repetition of
- Raising a Totally New Point: introducing less ...
- Overstatement (夸大): making immoderate...
- Anticlimax(虎头蛇尾):failure to ...
Discussion sections which also have a Conclusion may end:
- Tell your readers ... But you must ... If you repeated
- Suggest ways that
- Say if and / or why you ignored
- Admit ...
- Reiterate your reasons for ...
4-3 Language Focus 1: Cause and Effect
- Identifying causes and effects
- Drafting thesis statements for causes or effects
- Tips on planning causes and effects
- Distinguish direct and indirect causes and effects.
- Group different causes and effects
- Avoid mistaking coincidence (two unrelated things happening together) for cause or effect
- Avoid oversimplification
- 因为许多问题非常复杂
4-4 Language Focus 2: Paraphrasing
Why
- Plagiarism detection system
- A case of unintentional plagiarism
How
- Lexical(词汇)
- 同义词
- 改词性
- Syntactic(句法)
- 双重否定
- 主语换位
- 主被转换
- 语序转换
- Combined
4-5 Language Focus 3: Strong Restatement of the Research Objective
- Two features of a strong thesis statement
- It makes a claim that requires ...
- It makes a claim that offers ...
- Five kinds of weak thesis statements
- Statements that make no claim
- Statements that are obviously true or a statement of fact
- Statements that restate conventional wisdom
- Statements that offer personal conviction as the basis for the claim
- Statements that make an overly broad claim
5 Publication
5-1 Abstract
Essential elements:
- the background
- the problem
- the methods
- the results
- the implications
| Action | Tense |
|---|---|
| Giving background details | 一般现在时 |
| Describing the research activity | 一般过去时 或 现在完成时 |
| Describing the methods | 一般过去时(主动或被动) |
| Reporting results | 一般过去时 |
| Stating conclusions | 一般现在时 |
- 背景/目标:一般现在时
- 过程/方法:一般过去时
- 结果
The Types of abstracts
- Informative abstract
- Structured abstract
- 分段,每段开头为粗体的 Aim, Methods, Results, Research limitations/implications 或 Conclusion
5-2 Keywords
Definition of keywords:
- standout within the Abstract
- important words in the abstract
- emphasize the key information for readers
Purpose of keywords:
- increase the probability that a paper will be read and retrieved
- potentially improve citation counts and journal impacts
- know what words reflect the key information of the paper
- read more carefully when meeting these words in the paper
Categories:
- Discipline
- Topic
- Location
- Methods
- Data source
Number of keywords
- can’t be too few or many
- 3~5 in journals
- trade-off between the keywords to meet the limitation requirements for keywords
- choose the keywords from recent or often-cited titles close to their contribution
5-3 Reference
- IEEE:
[编号]. 作者名缩写. 作者姓, “文章题目,” 斜体期刊名称, 城市, 洲, 国家, 月日, 年, 页码 - MLA:
作者姓, 作者名. “文章题目.” 斜体期刊名称, vol. 期刊号, no. 发行号, 发行年份, pp. 页码
Functions
- used to avoid plagiarism
- tell editors and readers what sources have been cited in the paper
- help readers to use the materials to refer to when they write papers
Standard of a good reference:
- Authoritative
- Up-to-date
- Journal-targeted
5-4 Acknowledgement
Two main types of acknowledgements
- One is in a paper, and expresses the thanks to the organizations or projects or funds.
- The other is in a dissertation(大论文) as mentioned in the first part.
5 Submitting: writing the journal submission cover letter
Why a convincing cover letter?
- Highlighting the merit and significance
- Interesting the editor
What is included in the cover letter ?
- Follow the author guide.
- include essential information
- claim the originality of the paper
What should be avoided in the cover letter?
- Don't use too much jargon and acronyms.
- Don’t exaggerate.
- Don't make it lengthy.
- Don't try to be entertaining.
20 分钟做完客观题
-
empty introductory phrases:空的介绍性短语,客观
-
hedging language:模糊语,客观,避免过于绝对
-
trivial:琐碎的
-
current study
-
this study set out to tackle ...
-
The project undertaken
-
aimed to
-
show our gratitude
-
manuscript:稿子
-
Please find the attached manuscript
-
subject to:受...影响,屈服于
-
bring about:引起
-
syntax:句法
-
plunge:骤降
-
prevalent:普遍的
-
By contrast
-
proportion:比例
-
expenditure:开支
-
bead:珠子
-
reaffirm:重申
-
diffuse
-
quantitative/qualitative analysis
-
graduate student:研究生
Basic Research or otherwise called as pure or fundamental research, is one that focuses on advancing scientific knowledge for the complete understanding of a topic or certain natural phenomenon
基础研究是扩展科学知识
注意事项
改写句子不一定就是被动句,也可以加名词让句子复杂化
用 including 而不是 etc.
少用否定:not much(选择题里看见就排除)
句子不要太短
选项多于空的要考虑多选题
highlight adj.:不是结论本身的性质的形容词,只是强调、突出
有疑问的选项就尝试带进去理解,说不定是整个句子理解错了
conclusion 不能引用了
作文素材
形容词
- considerable:可观的
- numerous
- uncertain
- principal:主要的
动词
- obtain
- fluctuate:起伏
- encounter
- concur with:与...一致认为
- perform
- accord with:与... 一致
名词
-
consequence
-
administer/complete questionnaire
易错
名词化
- increase
- eliminate
- specificity
- specialization
- speciality
- sufficiency
- inequality
课程内容和要求
- 教材:《信息论与编码》,参考书:《信息论——基础理论与应用》
- 开卷考试,卷面占总成绩 60%,可以带计算器
简答题就简答,不要太多
信息度量和三大定理
主要计算题:信源编码和信道编码
的最大值就是信道容量
平均功率
平均交流功率就是方差,就是自相关函数的峰值
熵和信道容量要写单位
导数和积分表
- 给定方差情况下,高斯信源的信息率失真函数最大,即最难压缩;
- 给定方差情况下,噪声服从高斯分布时的信道容量最小
设函数求导比大小
高斯:
切比雪夫不等式:
第二章
Jensen 不等式(凹函数定义):
消息中平均每个符号携带的信息量有别于离散平均无记忆信源平均每个符号携带的信息量,后者是信息熵
若信源熵居然大于等概分布的信源熵,则一定是 信源空间不满足概率空间的完备集,譬如概率之和不为1
- bit
- bit/符号
- K 重扩展信源的熵:
- 平均符号熵:
- 互信息量:,没有负号!
- 平均互信息量 :
第三章
联合熵与条件熵的关系:
- 信源的冗余度:
第四章
平均码长是加权的,且 K 重扩展的平均码长单位为 码元/K个符号,往往要再除以 K
:乘公比错位相减
单义可译码:
- 等长码,且各消息对应码字不同
- 变长码,且不能用不同的多个码字拼出相同的一串序列,譬如
- 也可以直接算单义可译码和即时码的必要条件: , 为各码长,D 为符号种数
- 满足 Kraft 不等式只是表明这种码长分布可以构造单义可译码和即时码
- 即时码仅是单义可译码的一种排布,没有更严格的要求
最佳编码:具有最短的代码组平均长度或编码效率接近于 1 的信源编码
- 二元霍夫曼编码
:N 个信源符号的平均编码符号长度
- 编码效率:
先试扩展倍数小的,不够再加
第五章
信道矩阵:(给出信道特性)
对称离散信道: 信道矩阵的所有行由相同元素组成,所有列也由相同元素组成
二进制对称信道容量: bit/符号
离散准对称信道:
- 定义:信道矩阵可以按列分解为若干互不相交的子集,每个子集构成的矩阵都对应对称信道
- 设信源符号个数和信宿符号个数分别为 r 和 s, 当信源符号消息等概分布时,达到信道容量 C,且 比特/符号, 其中 是信道矩阵每一行的元素,n 表示子矩阵个数, 表示第k个子矩阵行元素之和,表示第k个子矩阵列元素之和。
译码准则:规定把 什么 y 判成 什么 x
- 先画香农线图
- 最小错误概率:对每个 ,取最大的 (其实也就是最大
- 列出发送码字到接收码字的转移概率矩阵
- 每列求和得到 ,每列除以它
- 每列取最大的
- 最大似然:对每个 ,取最大的
- 错误概率:先求正确概率
码率: 比特/码元,M 为码字种数
第六章
- 相对熵:
将随机变量 和 的变换关系记作 ,则有,其中 (是反的导数!f是Y到X!
若 ,则平均互信息量为 0
相对熵积分要复习一下
熵功率:达到指定熵所需的最小功率
6.3 需要仔细看(特别是6.3.2)
第八章
- :选一列取得最小失真度
- :取得最小失真度
- 二元离散信源的率失真函数:
- 等概离散信源的率失真函数:
- , 通常为 1
- 为失真矩阵中的非零元
是比特 / 信源符号, 是比特 / 秒
第十章
陪集首不能属于对应子群,且汉明重应最小
- 线性分组码的最小距离等于非零码字的最小重量
- 设C是 线性分组码,其纠错能力为t。如果用且只用不大于t个错误的全部错误图样作陪集首就能构成标准阵,那么就称这个码为完备码。
第十一章
有可能满足循环性但不是线性码!线性:两个码字相加也是码字
第一章 信息科学及其发展
1-1 通信系统的基本概念
信源:消息的提供者
- 可分为离散和连续
信道:传递消息的通道
- 可分为同轴电缆、光纤、波导等
- 也可分为 有/无干扰信道,离散/连续信道,单用户/多用户信道 等
信宿:信息的接收者
通信系统传输的是信号,信号是消息的载体,消息中的未知成分是信息
1-2 信息科学的有关概念
信息的特征:
- 未知性(不确定性)
- 由未知到知,等效为不确定性集合元素的减少
- 可以度量
1-3 信息理论的研究内容
- 狭义信息论:信息量、信道容量、熵、香农三定理
- 广义信息论:包含主观因素
微弱信号检测(最佳接收)
1-4 香农信息论梗概
围绕 有效性和可靠性
- 信息的度量
- 有效性:信源编码
- 香农第一、第三定理
- 可靠性:信道编码
- 香农第二定理
- 网络信息理论
- 保密信息理论
第二章 信息的度量
2-1 度量信息的基本思路
定义 2.1:若信源发出的消息是离散的、有限或无限可数的符号或数字,且一个符号代表一条完整的消息,则为单符号离散信源
定义 2.2: 若信源的输出是随机事件 X,其出现概率为 ,则它们所构成的集合称为 信源的概率空间 或 信源空间
信源空间的描述:
有
信源输出的事件的概率越小,信息量越大,即信息量是概率的减函数
自信息量 表示 发生所带来的信息量
定义 2.3 自信息量
信息量的单位:
- 以 2 为底:比特 bit
- 以 e 为底;奈特 nat
- 以 10 为底:哈特 Hart
自信息量和不确定度的关系
- 联系:
- 两者都是事件概率的函数,数值和量纲一致
- 区别:
- 不确定度是一个统计量,静态状态下也存在;
- 自信息量只有该随机事件发生时才给出,是动态的概念
2-2 信源熵和条件熵
定义 2.4 信源熵: 其中定义
- 信源熵只与信源符号概率分布有关,是一种先验熵
- 对给定概率分布的信源,信源熵是定值,代表信源每发出一个符号给出的平均信息量,其量纲为 信息量单位 / 信源符号
性质:
- 对称性:交换变量顺序不改变熵的值
- 确定性:若有一个事件必然发生,则熵为 0
- 非负性
- 可加性:对于统计独立的信源 X 和 Y,
- 强可加性对于任意两个信源 X 和 Y,(对数相乘,显然)
- 极值性:等概分布的信源的熵最大,
- 递增性:信源中一个符号划分为 m 个符号,且这 m 个符号的概率和等于原符号概率,则新信源的熵增加,
- 多元信源的熵可以表达为若干二元信源的熵的线性组合
- 严格上凸特性
Jensen 不等式(凹函数定义):
二进制熵函数 ,有
定义 2.5 条件自信息量:
条件概率仅由信道特性决定,看作信道给出的信息量。信源信宿对调也可得到条件自信息量
====
定义 2.6 条件熵:对于联合符号集 XY,在给定 Y 的条件下,用联合概率 对 X 集合的条件自信息量进行加权的统计平均值。
条件熵表示信道所给出的平均信息量
2-3 互信息量和平均互信息量
定义 2.7 互信息量:对两个离散随机事件集合 X 和 Y,事件 的出现给出关于事件 的信息量
- 信道没有干扰:
- 信道存在干扰: x的不确定度-收到y后对x尚存的不确定度=收到y对x所消除的不确定度 当 即互信息量 时,没有信息的流通
性质:
- 对称性:
- 值域为实数:可正可负可零,为负即后验概率小于先验概率,表示收到 y 后对信源是否发送 x 的正确概率小于 x 在信源集合中的概率
- 不大于其中任一事件的自信息量
- 互信息量描述信息流通特性的物理量,流通量的数值不可能大于被流通量的数值
条件互信息量 ,其中 即为条件互信息量
,助记:把 看作后缀,则简化为互信息量的公式
定义 2.8 平均互信息量:
- 为互信息量 的联合概率加权的统计平均值
- 在条件概率空间中的统计平均为
性质:
- 对称性:
- 与各种熵的关系:, 为共熵,或称联合熵
- 非负性,当且仅当 独立时取零
- 上界:
- 平均互信息量仅和信源概率分布 和信道传递概率 有关
- 给定信道传递概率 时, 是 的上凸函数
- 给定信源概率分布 时, 是 的下凸函数
最大平均互信息量:信道容量
平均互信息量的物理意义
- 平均互信息量为 信源熵减掉一个条件熵
- 表示以信源为参考,在接收端平均每收到一个符号所获得的信息量
- 条件熵 表示了干扰或噪声,又称疑义度
- 平均互信息量为 信源熵减掉一个条件熵
- 表示以信源为参考,在接收端平均每收到一个符号所获得的信息量
- 条件熵 唯一确定信道噪声和干扰所需的平均互信息量,又称噪声熵、散布度
信源空间题:TODO
- 先求各联合概率
- 再求
- 最后求题目要求的
定义 2.9 若对应于 x 有两种分布 ,则 称为这两种分布的相对熵,又称 熵差
定义 2.10 平均互信息量用相对熵定义:
平均条件互信息量:条件互信息量在概率空间 的统计平均
有:(去掉就超简单)
2-4 多维随机变量的熵
二维随机变量的共熵: (对数相乘)
多维随机变量的共熵,又称熵的链接准则:
熵的条件似乎可以直接“忽略”
多维信源的平均互信息量,又称信息链接准则:
定理 2.1 n 维随机变量的共熵不大于其各自熵之和,即 ,称为熵的界
当 同分布时,上界变为
常用:
定理 2.2 数据处理定理 若 (马氏链,有 ),则有数据处理不等式
当消息通过级联处理时,其输入和输出消息之间的平均互信息量,不会超过输入消息与中间消息之间的平均互信息量,也不会超过中间消息与输出消息之间平均互信息量;即 级联只会使得输入与输出间的平均互信息量变小
数据处理只是变换形态,不会创造新的信息
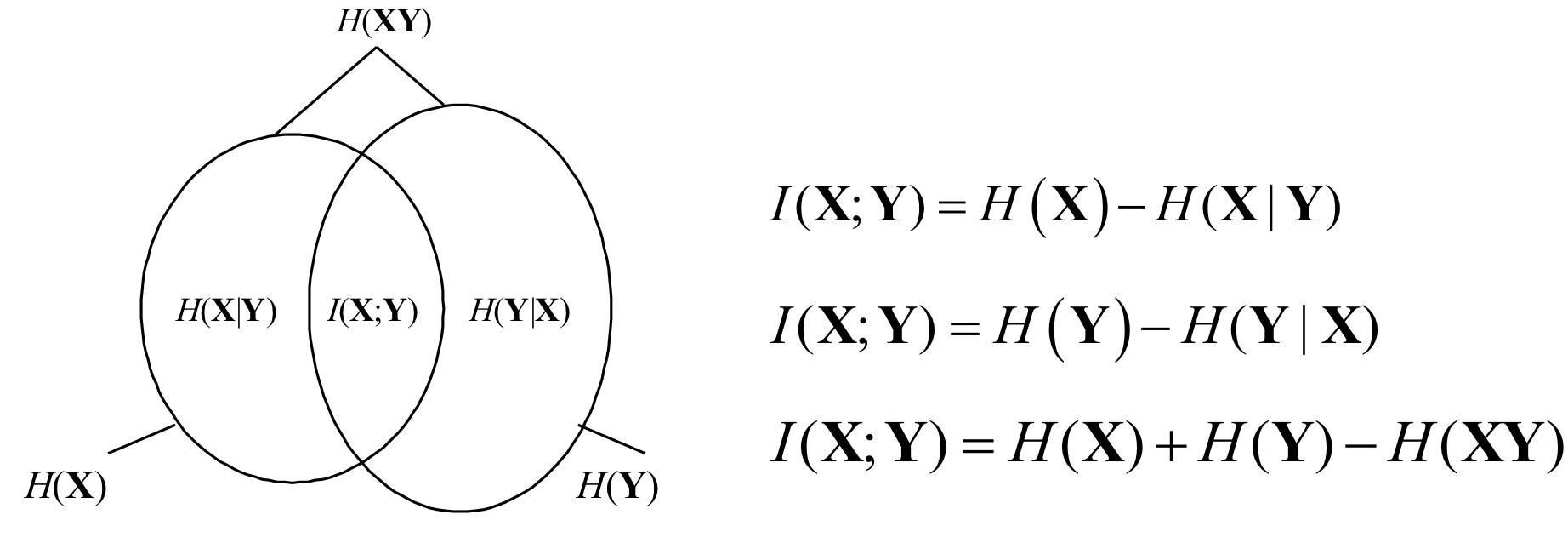
第三章 离散信源
3-1 离散信源的分类及其描述
根据时域:
- 单符号信源:信源每次只输出一个符号,可用随机变量描述信源输出的消息
- 符号序列信源:信源每次输出一个时域离散的符号序列,可用随机向量描述信源输出的消息
- 波形信源:信源每次输出时域连续的消息,可用随机过程描述信源输出的消息,采样后即为符号序列信源
根据时间和取值分布:
- 离散信源:在时间和取值上均离散,可用离散随机变量/随机向量/随机过程描述
- 连续信源:在时间或取值上连续,可用连续随机变量/随机向量/随机过程描述,采样后为信号、脉冲信号
根据平稳特性:
- 平稳:信源概率分布/密度不随时间改变
- 非平稳
根据记忆特性:
- 无记忆:信源在不同时刻发出的消息统计独立
- 有记忆(记忆长度有限的信源为马尔可夫信源)
信源编码:尽可能少的码元符号或尽可能低的数据速率来描述信源输出的消息
3-2 离散信源的熵
信息熵
定义 3.5 若信源发出 N 个不同符号 分别代表 N 种不同消息,各符号概率为 且相互统计独立,则为单符号离散无记忆信源
其信息熵为
定义 3.6 若信源发出的消息是由 K 个离散符号构成的符号序列,且各消息相互统计独立,则为发出符号序列消息的离散无记忆信源
K 重符号序列信源:每次发送都在 N 个符号里随机选 K 个(可重复)
定义 3.7 若单符号离散无记忆信源的信源空间为 ,对其 K 重扩展得到符号序列 ,则称扩展后的信源为离散无记忆信源 的 K 重扩展信源,扩展得到的符号序列记为
若 彼此统计独立,则定义 3.7 与 3.6 等价,也是发出符号序列消息的离散无记忆信源
发出符号序列消息的离散无记忆信源的熵为
定义 3.8 若信源发出的消息是由 K 个离散符号构成的符号序列,且各消息相互统计相关,则为发出符号序列消息的离散有记忆信源
有记忆信源的符号序列之间的关联程度可以用转移概率描述
符号间非独立(有关联)会使得信源输出的信息量减少
马尔可夫信源熵:是一般信源熵的特例
时间熵
时间熵 单位时间内发出的平均信息量 ,单位 b/s 或 bps
定义 3.9 若信源为具有 N 个单个符号消息的离散信源,第 i 个符号消息占用的时间为 秒,概率为 ,则称 的统计平均值为该信源符号消息的平均时间长度 或 平均长度,单位为秒/符号 秒/符号
若信源平均每秒发送 n 个符号,则 秒/符号
对于单符号离散无记忆信源:
K 重扩展的符号序列的时间熵
K 重扩展的离散无记忆信源的符号消息平均长度
仍有
若信源平均每秒发送 n 个 K 重符号序列消息,则 秒/符号, 有
若为有记忆信源,有 , 其时间熵小于无记忆信源的
消息之间的关联性体现在信源熵而非平均长度
3-3 信源的冗余度
3-3-1 最大信源熵
定理3.1 最大熵定理 设信源 X 中包含 M 个不同符号,其信源熵为 ,有 当且仅当 X 中各个符号的概率全相等时取等,此时得到最大熵 即熵的极值性,第二章证过
定理 3.2 两个集合 X、Y 的共熵 与这两个集合的信源熵 之间有 当且仅当两个集合相互独立时取等,此时取得最大熵
定理 3.3 对于初始信源 X 经过 K 重扩展的信源,若初始信源熵为 ,扩展后为 ,有 当且仅当 K 重符号序列消息的各个符号间相互独立时取等,此时取得最大熵
符号不等概或符号间有相关性都会损失信源熵
- 信源编码中要压缩冗余度来提高传输的有效性
- 信道编码中要注入冗余度来提高传输的可靠性
定义 3.10 设信源实际的熵为 H,该种信源可能的最大熵为 ,则信源的冗余度为 即信源在发出消息时无用信息量的百分比
3-4 信源符号序列分组定理
设离散无记忆信源的信源空间为
K 重扩展后,各符号序列为 ,这样的符号序列有 个。
当 K 足够大时,一个序列中任一符号 出现的次数都会趋近于 ,即扩展后很多序列的概率组成相同,是等概的
具有上述结构的序列称为 典型序列 ,其余的序列为 非典型序列
典型序列的自信息量也相等,为
自信息量的期望,即信息熵,为
当典型序列的概率之和很大时,就可以用典型序列来代表扩展信源(这正是数据压缩的本质)
信源符号序列分组定理说明上述分组是存在的,且可以估算其典型序列的数目
定理 3.4 信源符号序列分组定理 AEP(渐进均分特性) 设离散无记忆信源的信源符号为 ,各符号概率为 ,将该信源进行 K 重扩展得到 K 重符号序列 ,则任意给定 ,总有对应整数 ,使得 时,有 即信息熵与自信息量的差趋近于0
所谓渐近等分性:序列的越长,典型序列的总概率越接近于1,它的各个序列的出现概率越趋于相等
- 每个典型序列的概率
- 对于任意小的正数 ,当 K 足够大时,,可近似于
- 典型序列个数
- 对于任意小的正数 ,当 K 足够大时,,可近似于
- 典型序列占的比例
- 根据最大熵定理,一般有
- 随着 K 增大,典型序列占的比例逐渐趋于 0,典型序列出现概率高不等于典型序列种类多
表示 里的元素个数
信源符号序列分组定理表明,对于 K 重扩展信源,只考虑少量典型符号序列对信源特性带来的损失可以忽略,这给出了信源压缩编码的理论依据
3-5 平稳离散信源及其性质
平稳:概率分布不随时间变化
大部分实际信源在较短的一段时间都可以看作平稳信源
定义 3.10 若一个离散信源发出的符号序列 其出现概率与另一符号序列 的出现概率相等,则为平稳离散信源
- 改变其符号序列的起始位置,其概率和条件概率均不变,即平稳离散信源对应的随机过程是严平稳的
平稳离散信源的极限熵
有记忆离散信源每发一个符号所提供的平均信息量为
称 为平均符号熵, 为平稳离散有记忆信源的极限熵,又称熵率
平稳离散信源熵的性质
定理 3.5 若信源 X 是平稳离散信源,则有 即 是 X 中起始时刻随机变量 的熵与各阶条件熵之和。也即熵的链接准则。
定理 3.6 平稳离散信源的条件熵随 K 的增加是非递增的,即
特别的,由于平稳性,,故
推论 1:给定 K 时,平稳离散信源的条件熵小于等于平均符号熵,即
推论 2:平稳离散信源的平均符号熵随 K 的增加是非递增的,即
定理 3.7 极限熵的第二种形式 对于平稳离散信源,令 ,若 ,则 的极限值存在且有
- 一般离散平稳有记忆信源每发一个符号所提供的平均信息量等于极限熵
- 较难计算,但当 K 不是很大时,其平均符号熵 或条件熵 就非常接近于 ,可用作极限熵的近似值
第四章 离散信源的信源编码
4-1 信源编码的模型
信源编码
- 含义:将信源产生的消息变换为数字序列的过程
- 主要任务:把消息信号数字化为由信道基本符号构成的代码组(码字),并压缩冗余度,提高编码效率
编码是否会损失信源消息的信息量:
- 不损失信息量:无失真信源编码 -> 香农第一定理
- 会损失信息量:限失真信源编码 -> 香农第三定理
- 选择合适的信道基本符号(码元),使映射后的代码适应信道
- 用编码将信源发出的消息转换为代码组,即码字,其长度称为码长
- 编码应使消息集合与代码组集合中的元素一一对应
称上述一一映射的信源编码器为正规编码器,编出来的码为非奇异码
可以把信源和正规编码器合称等效信源,编码器的输入为初始信源
正规编码器的一一对应确保了编码不损失信息量,因此等效信源的熵必定等于初始信源的熵
研究信源编码时将信道编译码看作信道的一部分
- 若码字长度相等,称为等长码,反之为变长码
- 若信源符号与编码码字一一对应,称为非奇异码,反之为奇异码
- 若每个码元所占时间相同,称为同价码,反之为非同价码(例如莫尔斯电码)
- N 重扩展码:针对 N 重扩展信源编码得到的码字序列集合
- 若任意一串码字序列只能唯一的译为对应的信源符号序列,称为单义可译码,反之称为非单义可译码
- 不但要求信源符号与编码码字一一对应,即为非奇异码,还要求任意长的信源符号序列对应的码字序列一一对应,即任意 N 重扩展码均为非奇异码
- 非单义可译码会发生译码错误,导致失真
4-2 信息传输速率和编码效率
4-2-1 信息传输率
定义4.1 对于信源编码器的输出序列,其每个码元所包含的信息量称为 信源编码器的信息传输率,简称 码率 R
- R 的单位为 bit/码元
- 若每个码元时间为 t 秒,则可以定义信息传输速率
等长码:
- 单符号离散信源:设信源熵为 ,对其等长编码,每码字 b 个码元,则其信息传输率为
- K 重扩展信源:设信源熵为 ,对其等长编码,每码字 B 个码元,则其信息传输率为
变长码:
- 先求其代码组的平均长度
- 单符号离散信源:设信源有 N 个单符号消息 ,变长码编码器输出的代码组长度对应为 ,其出现概率分别为 ,则该变长码的平均长度为 ,信息传输率为 bit/码元
- K 重扩展信源:设信源有 N 个 K 重扩展的符号序列消息 ,变长码编码器输出的代码组长度对应为 ,其出现概率分别为 ,则该变长码的平均长度为 ,信息传输率为 bit/码元
4-2-2 编码效率
信道容量:信道的极限传输能力(平均互信息量的最大值)。根据平均互信息量的定义,在不失真传输的条件下,信道容量等于信源熵的最大值,
对于含有 D 个元素的信道基本符号集合,等效信源的最大熵等于 bit/码元,因此 bit/码元
定义 4.3 信源编码器输出代码组的信息传输率与信道容量之比,称为信源编码器的编码效率,即
- R = C 时,信源编码能充分利用信道
- R > C 时,信源编码输出信息的速率超过了信道传输能力,必然失真
- R < C 时,未充分利用信道
编码效率:
要提高编码效率可以减小代码组的平均长度
通常称具有最短的代码组平均长度或编码效率接近于 1 的信源编码为最佳信源编码,亦简称为最佳编码
要达到最佳编码,通常需遵循下面两个原则:
- 对信源中出现概率大的消息(或符号),尽可能用短的代码组(码字)来表示,简称短码;反之用长码
- 不使用间隔即可区分码字
- 要求单义可译性
原则一可以描述为:
定理4.1 设信源有 N 个消息分别为 ,出现概率分别为 ,信源编码器输出的 N 个代码组分别为 ,对应长度分别为 ,若信源消息的概率分布满足 ,而信源编码器输出的代码组长度满足 ,则该代码组的平均长度为最短。
最佳编码应满足 ,即可满足单义可译
4-3 单义可译定理
定义 4.4 对任何一个有限长度的信源消息序列,如果编码得到的码字序列不与其他任何信源消息序列所对应的码字序列相同,则称这样的码为单义可译码。
即时码:译码时不需要考察后续码元,一定为单义可译码
定理 4.2 设 是码 S 中的任一码字,码 S 为即时码的充要条件是:对于任意的 m<k ,任意码字 都不是码字 的前缀。
等长码都是即时码
即时码 ⊆ 单义可译码 ⊆ 非奇异码 ⊆ 所有码
定理 4.3 单义可译定理 即时码存在定理 设信源消息集合为 ,信道基本符号的种类为 D,码字集合为 ,对应的码长集合为 ,则存在即时码的充分必要条件是:D、N 和码长应满足如下不等式: 上式称为 Kraft 不等式。
任何一个结构为 的即时码一定满足 Kraft 不等式;而满足 Kraft 不等式的 又至少可构成一种结构为 的即时码
定理 4.4 平均码长界定定理 若一个离散无记忆信源 X,具有熵 ,对其编码用 D 种基本符号,则总可以找到一种无失真信源编码,构成单义可译码,使其平均码长满足
平均码长界定定理的物理意义:
- 下界证明是充要性证明,因此单义可译前提下平均码长的下界值为
- 也可以从信息传输率的角度理解下界,即 ,信息传输率不能超过信道容量,否则无法实现单义可译,从而造成译码错误
- 由于上界证明仅仅是充分性证明,因此平均码长大于定理中的上界也可能是单义可译码
- 给定信源空间 的离散信源,其熵 是确定值,如果信道基本符号数 D 也给定,则 也就定了。为此,需要改变信源本身统计特性,例如进行扩展
- 扩展后,可能使得每个消息的长度 ,这样平均长度也应减小
4-4 无失真信源编码定理
二进制编码和无记忆信源条件下香农第一定理:
- 对于二进制编码,D=2。根据平均码长界定定理有
- 类似地,对初始信源进行 K 重扩展,有
- 对于无记忆信源, 成立,因此
- 当 ,有
- 上式即是二进制编码和无记忆信源条件下香农第一定理的数学表示式
定理 4.5 香农第一定理 无失真信源编码定理 变长码信源编码定理: 设离散无记忆信源 X 包含 N 个符号 ,信源发出 K 重符号序列, 则此信源可发出 个不同的符号序列消息,其中第 j 个符号序列消息的出现概率为 , 其信源编码后所得的 D 进制代码组长度为 ,代码组的平均长度为 , 总可以找到一种编码构成单义可译码,使得 满足 当K趋于无限大时,
定理指出
- 要做到无失真的信源编码,每个信源符号平均所需要最少的 D 进制码元数,就是信源的熵值(熵定义中的log底数为D),或记为
- 扩展信源可以减少平均码元数,但有极限
- 此外,减少平均码元数是以增加编码的复杂性(存储复杂度)为代价的
- 从编码效率角度理解,不等式取到下界时,编码效率为 100%,可见无失真信源编码的实质就是对离散信源进行适当的变换,使变换后新的符号序列信源尽可能为等概率分布,以使新信源的每个码符号平均所含的信息量达到最大,进而使信息传输率R达到信道容量C,实现信源和信道理想的统计匹配
4-5-1 香农编码方法
- 先将信源消息的概率按 降序排列,然后计算 ,即 为前 i–1 个概率的累加
- 再把 变为二进制小数,取小数点后的 位数作为第 i 消息的码字,其中 满足
二进制小数:将小数部分一直乘 2,积的整数部分顺序取出
特点:
- 先得到码长,再得到码字
- 码字集合唯一
- 并非一定最优
4-5-2 费诺编码方法
又称子集分解法
- 将信源消息符号按其出现的概率大小依次排列
- 将依次排列的信源符号按概率值分为两大组,使两个组的概率之和接近相同,并对各组赋予一个二进制码元“0”和“1”
- 将每一大组的信源符号进一步再分成两个组,使分解后的两个组的概率之和接近于相同,并又赋予两个组一个二进制符号“0”和“1”
- 如此重复,直至每个组只剩下一个信源符号为止
特点:
- 先得到码字,再得到码长
- 码字集合唯一
4-5-3 霍夫曼编码
本科数字通信笔记第四页,这里使用 as low as possible 或者 as high as possible 都可以
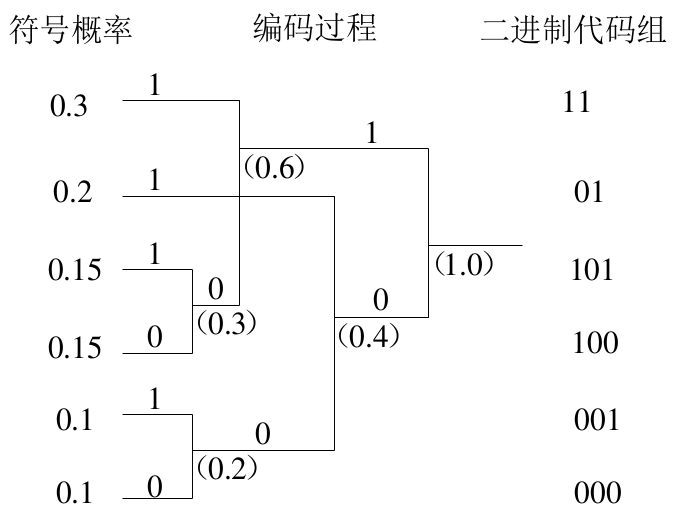
特点:
-
码字集合不唯一
-
二元霍夫曼编码是最佳编码
-
r 元霍夫曼编码可能需要扩展原信源,使得霍夫曼最后一步的信源有 r 个符号,故需扩展到 个信源符号
4-5-4 Lempel-Ziv 编码
与本科数字通信所学不一样
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| 子列 | a | b | aa | aab | aaba |
| 编码 | 0a | 0b | 1a | 3b | 4a |
未出现过的子列用 0 开头
特点:
- 独立于信源的统计特性,是一种变长到定长的编码方案
- 利用了已编码信息来进行当前的编码,是等长码,编码的过程就是建立码地址和将待编码消息序列分段的过程,所有的码段内容都是不同的
- 对于长的消息序列,压缩比较明显
- 地址会不断变长,可以用相对地址解决
- 将编码结果表示为3部分内容:<相对地址,可利用的已编码信息长度,本次编码新增加字符>,称之为编码包
- 可利用的只要是已经编码过的信息就行,不需要是一整个包什么的
- 第一部分:利用的已编码信息在当前信息之前多少 位,是按序列数的,不是按包
- 第二部分:利用的已编码信息长度
- 两个相当于是 数组首地址(相对) 和 数组长度
- 如果下一个要编码的刚好是上一个已编码符号 x 的 n次重复,则写为 <1,n x>
4-5-5 等长码的信源编码定理
设等长码的信源的消息符号集合为,进行 K 重扩展后,符号序列消息的总数为 ;设信道有 D 种基本符号,每个码字有 B 个码元,故最多有 种码字,要满足单义可译性,应满足 ,即 或
但实际可以只对典型序列编码,即 典型序列个数
定理 4.6 设 K 重扩展的符号序列消息集合中,对于任意小的 ,当 时,只要 K 足够大,译码错误概率 就可以任意小。若 ,则当 时, 可以任意地接近于 1
等长码的信源编码定理的物理意义: 或 时,更有效的信源编码存在
对于等长码,K需要非常大(上千)才能获得低译码错误概率和高编码效率
传输所造成的错误会产生所谓“扩展效应”,简称为译码的错误扩展。例如,传输过程1-bit的错误可能导致信宿端多个消息的译码错误。这需要信道编码来保证传输正确
第五章 离散信源及其信道编码
5-1 信道的分类及其描述
(1) 信道按输入/输出符号空间的性质来划分,根据幅度和时间上的取值是离散或连续,分为四类:
- 离散信道:输入和输出的随机序列取值均为离散的信道,也称为数字信道
- 连续信道:输入和输出的随机序列取值均为连续的信道
- 半离散或半连续信道:输入序列是离散型但相应输出序列是连续的信道,或者相反
- 波形信道:输入和输出都是时间上连续的随机信号,也称为模拟信道
(2)按信道的输入消息集合和输出消息集合的个数来划分:
- 两端信道:信道的输入消息集合只有一个X集合,同时信道的输出消息集合也只有一个Y集合,又称为单向单路信道
- 多端信道:信道的输入端和输出端中,至少有一端具有一个以上的消息集合,又称为多用户信道
(3) 信道按输入/输出信号间的关系是否确定来划分,
- 无扰信道:信道输入/输出之间是一种确定的关系,这是一种理想化的信道,信道上不存在噪声及干扰。可以作为衡量其他信道特性的参考
- 有扰信道:信道输入/输出之间是一种统计依存的关系,信道上存在干扰和(或)噪声。实际的通信信道几乎都是有扰信道
(4) 信道按其输入/输出之间关系的记忆性来划分,
- 无记忆信道:在某一时刻信道的输出消息仅与当时的信道输入消息有关,而与前面时刻的信道输入或输出消息无关。信道的统计特性可以用信道传输概率的集合{P(y|x)}来描述
- 有记忆信道:在任意时刻信道的输出消息不仅与当时的信道输入消息有关,还与以前时刻的信道输入和(或)输出消息有关。实际信道一般都是有记忆的
(5)信道按其统计特性来划分,
- 恒参信道:信道的统计特性不随时间变化,又称为平稳信道
- 变参信道:信道的统计特性随时间变化
5-2 无扰离散信道的传输特性
定义 5.1 单位时间内所传输的信息量,称为消息在信道中的信息传输速率,简称为信息率 R
- 量纲为比特/码元或比特/符号、比特/符号序列等时,用 R 表示
- 量纲为 bit/s 或 bps,用 表示
平均互信息量 代表收到 Y 后获得关于 X 的平均信息量,因此实质上就是量纲为比特/码元(或比特/符号、比特/符号序列等)的信息传输速率,即 bit/码元;如果改变其时间单位,则有 bit/s
- 无扰离散信道下信息传输速率等于信源熵,即 bit/码元; bit/s
信道容量: 消息在不失真传输的条件下,信道所允许的最大信息传输速率称为信道容量,即 bit/码元;当单位为bit/s(bps)时,C 变换为 bit/s
信道容量和信道中传输的消息数目 N 的关系: 对无扰信道,信道传输的信息量就是信源发出的信息量,根据最大信息熵定理,所有信源符合等概率的时候信源熵最大,因此信道容量 bit / 码元; bit / s
定义5.3 基本符号时间等长的信道称为均匀编码信道,这种等长的基本符号称为码元。
- 损失熵:
- 噪声熵:
无噪无损信道:输入与输出符号一对一
- 损失熵 和 噪声熵 均为 0,
- 信道容量 bit/码元
无噪有损信道:输入与输出符号多对一
- 损失熵 ,噪声熵 ,
- 信道容量 bit/码元
有噪无损信道:输入与输出符号一对多
- 损失熵 ,噪声熵 ,
- 信道容量 bit/码元
5-3 有扰离散信道的传输特性
信道矩阵:(给出信道特性)
为信道传输概率
对称离散信道: 信道矩阵的所有行由相同元素组成,所有列也由相同元素组成
强对称离散信道(均匀信道):信道矩阵为方阵
- 总错误概率为p,均匀分给r-1个输出符号
- 信道矩阵各列之和也等于1
二进制对称信道(BSC):其中为交叉传输概率
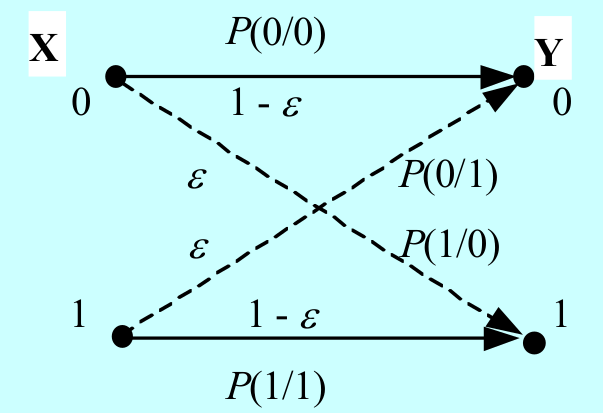
准对称离散信道
- 信道矩阵的列可以分解为若干互不相交的子集,每个子集构成的矩阵都对应对称信道
二进制删除信道:
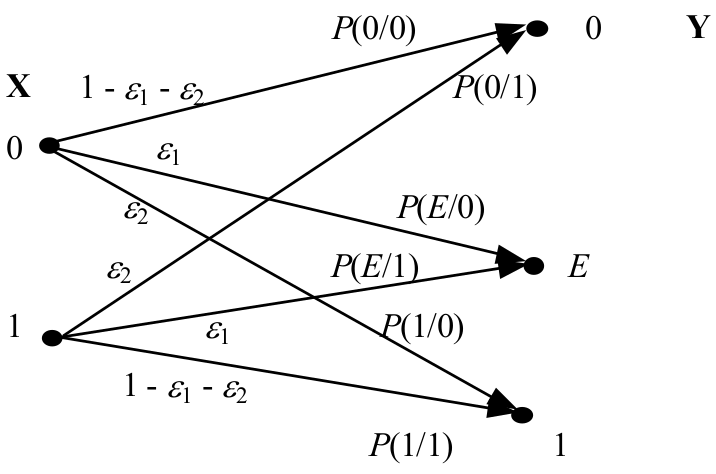
5-3-4 有扰离散信道的信道容量
有扰离散信道的信道容量是指在不失真传输的条件下,信道所允许的最大信息传输速率(平均互信息量):
- 信道容量 C 是信道的最大传输能力,是信道自身的特性
- 能使平均互信息量达到信道容量C的信源称为匹配信源
- 是 和 的函数
- 只与具体信源有关; 只与信道特性有关,与具体信源无关,因此
几种特殊信道的信道容量
定理 5.1 对于信源符号个数和信宿符号个数分别为 r 和 s 的离散对称信道, 当信源符号消息等概分布时,达到信道容量 C ,且 比特/符号, 其中 是信道矩阵每一行的元素
二进制对称信道容量:
定理 5.2 对于信源符号个数和信宿符号个数分别为 r 和 s 的离散准对称信道, 当信源符号消息等概分布时,达到信道容量 C,且 比特/符号, 其中 是信道矩阵每一行的元素,n 表示子矩阵个数, 表示第k个子矩阵行元素之和,表示第k个子矩阵列元素之和。
二进制删除信道容量:
一般离散信道:
凸问题一定能用拉格朗日解,否则不一定
定义 表示接收到 之后获得关于 的信息量(某个符号与信宿之间的平均互信息量)
定理 5.2:输入概率分布达到信道容量的充要条件为
- 概率不为 0 的信源符号和 Y 的平均互信息量都等于信道容量
- 达到信道容量的最优输入分布不唯一
信道容量的通解
对信道矩阵每行列一个方程:
若信道矩阵为方阵且可逆, 则可以求出 ; 继续求出 C 和 : 最后根据 得到最优输入概率分布
通常为负
K 重扩展信源的信道
对于信源 的 重扩展信源 , 对应的 重扩展信宿 , 且 ,
- 当信道无记忆时, 即信道传输概率满足 ,则有
- 当信源无记忆时, 即满足 ,则有
- 当信源和信道都无记忆时,则有
- 当且仅当信源无记忆且各个 达到最佳概率分布时取等
- 对于时不变信道,即各个 经过相同信道时,
并联信道
串联信道
信道矩阵为各个子信道的信道矩阵的乘积
两个 BSC 串联后仍是 BSC
级联将使信道容量C下降,且随着 的增大变得非常明显
5-4 译码准则
定义 5.6 在一般的信息传输系统中,信宿收到的消息不一定与信源发出的消息相同, 而信宿需要知道此时信源发出的是哪一个信源消息, 故需要把信宿收到的消息 根据某种规则判决为对应于信源符号消息集合中的某一个, 例如 ,这个判决的过程称为接收译码,简称译码,译码时所用的规则称为译码准则。
- 任何译码准则所遵循的基本要求都是要使信宿得到的判决结果中错误最少
- 译码准则就是一种能满足 的函数关系,它使得译码结果中的错误概率达到最小
5-4-1 常用的译码准则
例:
最小错误概率准则 即 最大后验概率准则
对于所有的 i ,若 ,且 ,则
可以通过求所有的 ,对每个 取最大的后验概率,算出正确传输概率
也可以直接从信源的概率分布和条件概率来求采用最小错误概率准则时的接收错误概率:
最大似然译码准则
是信道传输概率,也称为最大似然函数
- 信源符号等概分布
- 只要选取 使得 最大,则 最大
- 此时错误概率为
-
- 不论发送哪个符号,收到 的概率都相等
- 此时只要选取 最大即可
5-5 有扰离散信道的信道编码定理
5-5-1 编码方法与平均错误译码概率
信息传输速率(码率): 比特/码元
5-5-2 汉明距与编码原则
略
在同样的信道条件下,所能达到的 ,与所选择许用码组的 有关
- 许用码组:有对应信源符号的信宿符号
二元对称无记忆信道的最大似然译码
假设发送码字 经过信道后变为 ,则信道传输概率为 p为单个符号传输错误概率,通常小于0.5 因此, 越小, 越大,等价于最小距离译码
- 发射的信源等概时,最小错误概率译码退化为最大似然译码;
- 二元对称无记忆信道下,最大似然译码退化为最小距离译码。
编码原则
任意许用码字间的最小汉明距尽量大
5-5-3 有扰离散信道的信道编码定理
定理 5.3 抗干扰信道编码定理 香农第二定理: 设信道有 D 个输入符号,s 个输出符号,信道容量为 C,被传消息的码长为 N,信息传输速率为 R, 则当 R< C 时,只要码长 N 足够长,总可以在输入集合中,找到 M 个码字( , 为任意小的正数),分别代表M个等可能性的消息,组成一种信道编码, 选择相应的译码规则,使信宿端译码后的最小平均错误译码概率 达到任意小
定理 5.4香农第二定理逆定理 设信道有 D 个输入符号、s 个输入符号,信道容量为 C; 令 ε 为任意小的正数,若选择许用码组个数 (即R > C), 则无论码长 N 多大,也不可能找到一种编码,使 任意小。
5-6 信道编码定理的应用
第六章 连续消息和连续信道
6-1 连续消息的信息度量
- 将连续型信源变换成离散型信源,用离散信源的分析方法进行分析
- 再将量化单位无限缩小,在极限情况下分析离散情况得到的结果
样值量化——连续信源变为离散信源
- 时间抽样
- 量化幅度
- 每个样值的自信息量以及信源熵都可用离散信源理论计算,所得离散信源的熵可近似作为此连续信源的熵
量化级无限增大 ——离散信源还原成连续信源
- 量化幅度与原幅度间的差异会引起量化噪声
- 可以使用非线性压扩和减小量化单位减少量化噪声
- 当量化单位无限缩小时,离散信源就能还原为连续信源
- 设样值的熵为 ,它实际上就是量化后得到的单符号离散信源的信息熵
- 设量化前样值的幅度为 ,对应的概率密度值为 ;若量化后的样值幅度为 ,对应的概率密度值为 ,则在区间 ,其概率为
- 量化后共有 个取值, 则离散信源的信息熵
- 当 趋于 0 , 得到连续信源的熵的计算公式 第一项由且仅由 决定, 为确定值, 称为相对熵, 用 表示; 第二项当 时它趋于无限大, 称为绝对熵, 用 表示:
相对熵:
- 相对熵的形式与离散信源熵的形式相近,另外当考虑信息传输问题时,由于互信息量等于两个熵相减,所以绝对熵可以抵消,只剩下相对熵
- 相对熵能够很好地量度连续信源的信息特性,在后面的讨论中,如无特别说明,一般所说的信源熵都是指相对熵
绝对熵:
- 之所以称为绝对熵,是因为 时它趋于无限大,且连续信源的各种熵都有这一项
输出随机序列的连续信源
- 联合相对熵为 比特 / 样值序列
输出随机信号的波形信源
- 采样后转换为无穷维随机序列
- 比特/样值序列
- 比特/秒(更常用)
- 对于带宽为 ,时长为 的信号, 等价于计算长度为 的随机序列信源的相对熵
6-1-2 几种连续信源的相对熵
均匀分布:
- 相对熵: 比特/样值
- 时,相对熵为负
N维区域体积内均匀分布的连续信源: N维连续信源输出随机向量 的各个分量分别在 区域内均匀分布,
- 该信源的相对熵为 比特/样值序列 等于 维区域体积的对数, 也等于各分量相对熵之和 (与离散无记忆信源一致)
- 推广到带宽为 , 时长为 的波形信源, 如果每个样值 在 区间服从均匀分布, 相对熵为 比特/样值序列
- 单位时间内的相对熵为 比特/秒
高斯分布连续信源:
- 相对熵: 奈特 / 样值
- 当均值为 0 时,即不计高斯连续信源X中的直流部分时, 奈特 / 样值,P 为平均功率
- 对于协方差矩阵为 C 的高斯向量 x: 奈特 / 样值;
- 当 x 的各元素独立时,有
指数分布:
- 相对熵为: 奈特/样值
6-1-3 条件熵
离散信源条件熵 其中任意两事件 的联合概率为 连续信源经取样、量化后的样值共有 个取值, 则条件熵为
相对条件熵: 绝对条件熵: 当 时绝对条件熵趋于无限大
- 对于输出随机序列的连续信源, 相对条件熵为
6-1-4 连续消息熵的性质
- , 以及 ,当且仅当x和y相互独立时取等
- 可加性:x和y 独立时
- 强可加性:
- 相对熵可以是正值或0,也可以是负值,取决于概率密度函数
- 相对熵是 的凹函数
- 相对熵存在最大值,但是与离散信源不同,对信源不同限制条件下的最大熵不相同
- 连续信源输出的随机变量(随机向量)通过确定的一一对应变换后,相对熵会发生变化
- 将随机变量 和 的变换关系记作 , 则有 其中 若 X、Y 为矩阵,则
6-1-5 最大相对熵定理
定理 6.1 设 是在 区间具有某种分布的概率密度函数,其约束条件为 ; 为不同于 的其他分布,但约束条件和 相同,也为 。 则有 区间 在极限情况 时, 上式仍然成立。
定理 6.2 峰值功率受限条件下信源的最大熵定理 若某信源输出信号的峰值功率受限,即信号的取值被限定在某一有限范围内, 则在限定的范围内,当输出信号幅度的概率密度函数是均匀分布时该信源达到最大熵值。
设 ,则峰值功率为 ,该信源的最大相对熵为
如果将对应的分布称为最佳分布并用 表示,则有
定理 6.3 平均功率受限条件下信源的最大熵定理 若某信源输出信号的平均功率被限定,则当其输出信号的概率密度函数 是高斯分布时, 信源达到最大熵值;对于 N 维连续信源来说,若N维随机矢量的协方差矩阵被限定, 则 N 维连续信源为 N 维高斯分布时达到最大熵值。
平均交流功率:方差
定理6.4 均值受限条件下信源的最大熵定理 若某连续信源 X 输出非负信号的均值被限定,则其输出信号幅度为指数分布时, 连续信源 X 达到最大熵值。
6-1-6 熵功率和熵功率不等式
熵功率
熵功率是给定零均值高斯分布的相对熵 ,反推出平均功率:
可以采用 衡量连续信源的冗余度
熵功率不等式
两个零均值统计独立的连续随机变量 X 和 Z,平均功率分别为 和 , 则随机变量 的平均功率
,当 X 和 Z 为独立高斯随机变量时等号成立
6-2 连续消息在信道上的传输问题
- 连续消息的平均互信息量 比特 /样值
- 连续消息序列的平均互信息量 比特 /样值
- 波形信号的平均互信息量 比特/样值序列
- 比特/秒
- 对于带宽为B,时长为T的信号,等价于计算长度N=2BT的连续消息序列的平均互信息量
连续消息平均互信息量性质:
- 非负性
- 对称性
- 上凸函数
- 数据处理定理:若 形成马氏链,则
- 一一对应的变换不改变平均互信息量关系
- 和 的关系
- 如果多维连续信源无记忆, 则
- 如果多维连续信道无记忆, 则
- 如果信源和信道均无记忆, 则
单符号加性信道的平均互信息量:
多维加性信道的平均互信息量:
对于多维加性信道, 信道无记忆等价于噪声分量独立
加性波形信道的平均互信息量
6-3 香农信道容量公式
6-3-1 加性信道的信道容量
加性噪声:
连续加性信道的信道容量
-
单符号信道
-
多维信道
-
波形信道
-
单符号高斯加性信道:
- 奈特 /样值
-
单符号非高斯加性信道
- 奈特 /样值
- 同等噪声功率情况下高斯噪声是最坏情况噪声(使得信道容量最小)
-
多维无记忆高斯加性信道
注水原则:应当向 噪声功率较小分量度 分配 较多的输入信号功率;若噪声各分量等功率,则输入信号等功率分配最优
- 多维有记忆高斯加性信道
6-3-2 带限AWGN信道的信道容量
WGN采样点为服从独立同分布的高斯随机变量
WGN各样值方差均为 (即自相关函数)
(AWGN信道中)当输入信号的样值服从零均值独立高斯分布,且每个样值的功率相等时(即输入信号具有高斯白噪声特性)
带限AWGN信道的信道容量为
单位时间的信道容量(Shannon 公式):
Shannon公式成立的条件
- 输入信号平均功率为 (为AWGN时达到信道容量)
- 带宽为 的带限信道
- 噪声为AWGN,功率谱密度为
有色加性高斯噪声信道的信道容量
6-3-3 香农公式的意义
- 信道容量与所传输信号的有效带宽成正比,信号的有效带宽越宽,信道容量越大
- 信道容量与信道上的信号噪声比有关,信噪比越大,信道容量也越大,但其制约规律呈对数关系
- 信道容量 C、有效带宽 B 和信噪比 S/N 可以相互起补偿作用,即可以互换
- 当信噪比小于1时,信道的信道容量并不等于0,这说明此时信道仍具有传输消息的能力。也就是说,信噪比小于1时仍能进行可靠的通信
- 信号有效带宽无限时,信道容量
- 香农公式是在噪声为AWGN情况推得的,对那些不是白色高斯噪声的信道干扰而言,其信道容量应该大于按香农公式计算的结果
第八章 信息率失真理论及其应用
8-1 失真函数和平均失真度
8-1-1 失真函数
定义 8.1 对于图示系统, 对应于每一对 , 定义一个非负实值函数 表示信源发出符号 而经信道传输后再现成信道输出符号集合中的 所引起的误差或失真, 称之为 和 之间的失真函数。
.png)
失真函数的值可人为规定,一般定义为 时(即 )取 0
失真矩阵
输入符号集 中有 种不同的符号 ; 输出符号集 中有 种不同的符号 ; 失真函数 共有 个具体值, 按 和 的对应关系, 排列 成一个 阶矩阵: 称为信道 的失真矩阵。
汉明失真矩阵(只有主对角线为 0):
把 分类讨论并写出来,再写失真矩阵
8-1-2 平均失真度
定义 8.2:称随机变量 和 的联合概率 对失真函数 进行加权的统计平均值为该通信系统的平均失真度 。
就是加权的失真度
N次扩展信源的情况
将定义8.1进行扩展, 可得 次扩展的信源和信宿符号序列 与 之间的失真函数为
对应的失真矩阵为
平均失真度 为
对无记忆信源和信道有
式中
离散无记忆信源X的N次扩展信源通过无记忆信道传输后的平均失真度是未扩展情况的N倍:
类比扩展信源的信息熵和平均互信息量
8-2 信息率失真函数
8-2-1 保真度准则
定义 8.3 保真度准则 信道每传送一个符号所引起的平均失真,不能超过某一给定的限定值D,即要求 ,称这种对于失真的限制条件为保真度准则。
保真度准则指出,给定的失真限定值D是平均失真度 的上限值
平均失真度取决于如下几个因素
- 信源的统计特性,即
- 信道统计特性,即
- 失真函数,即
8-2-2 失真许可的试验信道
定义 8.4 凡是能满足保真度准则 的信道,称之为D失真许可的试验信道
所有的 D 失真许可的试验信道构成的集合表示为:
感兴趣的是 在同样的保真度准则下,能使信道的信息传输率尽可能小 的试验信道
8-2-3 信息率失真函数
定义 8.5:用给定的失真 为自变量来描述的信息传输速率, 称为信息率失真函数,用 表示
- 信息传输速率 本质上是描述信源输出的信息速率
- 一方面, ,是 的函数,另一方面,信道上的信息传输速率 ,因此,又可以用平均互信息量 来表示
- 是 的凸函数, 故总可以在 集合中找到某 一试验信道, 使 达到最小值 , 故有
信息率失真函数的物理意义
- 信息率失真函数是在 的前提下,信宿必须获得的平均信息量的最小值,是信源必须输出的最小信息率
- 信息传输速率本质上是描述信源特性的,因此R(D)也仅用于描述信源
- 若信源消息经无失真编码后的信息传输速率为R,则在保真度准则下信源编码输出的信息率就是R(D),且
R(D) 与 C
- 信道容量仅与信道有关,是信道的最大传输能力
- 信息率失真函数仅与信源有关,是在给定失真度下,信源至少要给信宿的信息率
N次扩展的信息率失真函数
8-2-4 信息率失真函数的性质
D必须在给定的信源X的概率分布P(X)、信宿Y的概率分布P(Y)和给定的失真函数 条件下所得的平均失真度 D 的最小值 和最大值 之间适当选择
可以求得平均失真度 的最小值, 为
的最小值 就是允许的平均失真度 的最小值, 即
-
当失真矩阵中每行至少有一个零元素时,
-
若某一行没有零元素,则可以让该行所有元素减去该行最小值,这样就有了零元素(毕竟失真度可以自定义)
-
因此,总是可以认为
-
如果失真矩阵每一列至多有一个0,则 对应的试验信道疑义熵 ,即,收到Y以后对X不存在不确定性
-
如果失真矩阵的列有大于1个0,则 对应的试验信道疑义熵 ,即,收到Y以后对X存在不确定性
和
- 是在保真度准则 下平均互信息量 最小值
- 是非负数, 因此 最小值是 0
- 定义最大允许失真度 为使 的最小平均失真度 (平均失真度超过 仍然等于 0 )
- 等价于 , 此时信道的输入随机变量 和 输出随机变量 之间一定统计独立, 即有
R(D)为减函数,D越大,所需要的信息量越少,所以R也越小,直到为0。 就是 R 即便为 0 也满足 D 的要求的那个点
R(D) 函数的凸性
(下凸)
定理 8.1 在定义域内是凸函数, 即对任意 有
R(D)函数的单调递减性
定理 8.2 信息率失真函数R(D)在定义域内是严格单调递减的。
使得平均互信息量最小的试验信道一定在试验集合的边界取到
8-3 信息率失真函数R(D)的计算
8-3-1 几种特殊离散信源的信息率失真函数
Fano不等式 ,式中 是输入符号种数,
扰码器:让输出变为近似等概分布,必须在压缩编码之后(因为等概的时候压缩的概率很低)
8-3-2 离散信源R(D)的参量表述
8-3-3 连续信源的信息率失真函数
连续信源的失真函数一般为
将离散情况中的求和运算改为积分运算
平均失真度:
信息率失真函数:
高斯信源的信息率失真函数
概率密度函数 平方误差失真 利用参量表述结果可得
一般信源的信息率失真函数
均值为 0 , 方差为 的连续信源 , 相对熵为 , 平方 误差失真下的信息率失真函数满足
- 当X为高斯信源时,取到等号
- 在平方误差失真下,相同方差的信源要达到同样平均失真,高斯信源具有最大信息率失真函数,即高斯信源最难压缩
8-4 保真度准则下的信源编码定理
定理 8.3 限失真信源编码定理 或 Shannon第三定理 设 是某离散无记忆信源的信息率失真函数, 并且选定有限的失真函数 。 对于任意允许的平均失真度和任意小的正数 , 以及任意足够长的码字长度 , 则一定存在一种信源编码, 其码字个数为 而编码后码的平均失真度 若码字数为 则一定有
实际上就是
- 也可以将定理8.3作如下的叙述:
- 若R(D)为离散无记忆信源的信息率失真函数,D为允许的失真度,则只要实际的信息率R满足 ,就存在一种编码方法,使其译码的平均失真度 ; 反之,若R < R(D),则无论怎样的编码方法,都不能使
- R(D)是保真度准则下,信源信息率压缩的下限值。无失真信源编码信息率压缩的下限值是信源熵H(X),而
- 若给定信源 ,其信息熵 ,规定了失真函数,选定了允许的失真度 ,即可求得信息率失真函数
- 根据Shannon第三定理,必然存在一种压缩编码方法,使其平均失真度不大于 ,且其输出信息率由 下降到,只要
联合信源信道编码定理(信源信道编码分离定理): 设离散无记忆信道的容量为 比特/秒,离散无记忆信源熵为 比特/秒,则当 时, 则总存在一种编码方案使得译码错误概率任意小;反之,如果 , 则不存在使得译码错误概率任意小的编码方案。
第九章 差错控制的基本概念
9-1-2 差错控制系统
差错控制系统根据它们的纠、检错能力;对信道的要求及适应性;编、译码器的复杂性;编、译码的实时性等性能指标可以分为如下4类
- 自动请求重传系统
- 前向纠错系统
- 信息重复查询系统
- 混合纠错系统
自动请求重传系统 ARQ
- 通信系统在接收端检测到传输错误并自动告知发送方,请求发送方重发,称为自动请求重发,简称反馈重传
前向纠错(FEC)系统
门限:误码率开始比未编码的差错性能更好的最小
定义9.1 对于给定的误比特率, 编码增益 是指 通过编码所能实现的 的减少量, 即: 其中 和 分别表示末编码及编码 后所需要的 。
信息重复查询系统( IRQ )
- 是指接收端将收到的消息原封不动地转发回发送端,在发送端与原发送消息相比较的系统。如果发现错误,则发送端再进行重发,直至正确为止
- 原理和设备都较简单,但需要有双向信道,因为相当于每一消息都至少传送了两次,所以传输效率较低
混合纠错系统(HEC)
- HEC系统将反馈重传技术与前向纠错技术相结合
- 当出现少量错码并在接收端能够纠正时,即用前向纠错方法纠正之;当错码较多超过其纠正能力但尚能检测时,就进行自动反馈重传
- 混合纠错结合了ARQ和FEC两者的优点
9-2 纠错编码的基本概念及其本质
9-2-1 纠错编码的分类
分组码
码长为n = k + r,其中 k是信息元个数, r是监督(校验)元个数,监督元只与本组信息元有关。 通常将分组码写成码(n , k),或称为(n , k)码
卷积码
个信息位编码为 位,校验位不仅与本组的信息位有关,还与前 m 段的信息位有关。
称为卷积码的码长, 为信息元个数,m为存储级数。通常将卷积码写成码,或称为码
定义 设发码 或 , 收码 R: 或 , 则定义信道的错误图 样为 或 , 其中 由定义可知 这里的+是二进制加法(异或)
定义 9.5 在错误图样中,若“1”集中于某个长度b内,则称该种错误为长度为b的突发错误, 其中b称为突发错误长度,该图样称为突发错误图样。
定义 9.6 分组码是对每段 位长的信息组, 以一定规则增 加 个监督(校验)元, 组成长为 的序列 称这个序列为码字或码组、码矢。在二进制的情况下, 位长的信息组共 个,通过编码器后,码字还是 个,称这 个码字的集合为 分组码。
- 长序列的可能排列共有 种, 其中只有 个 重构成 了 分组码, 称它们为许用码组(对应了), 其余的 个 重为禁用码组
定义 9.7 卷积码是对每段 长的信息组以一定的规则增加 个监督(校验) 元, 组成长为 的码段; 个校验元不仅与本段的信息元有关, 且与前 段的信息元有关; 编码约束长度 , 它表示 个信息元从输入编码器到离开时, 在码序列中影响的码元数目。
定义 9.8 将信息位在码字中所占的比例称为编码效率,也称为码字效率,通常也用R表示。
重复码
重复码是k =1的分组码 (n, 1), 它的(n –1)个校验元是信息元的重复
重复码的译码采用大数判决方法,也称为大数准则,或最大似然准则、最小距离准则
- 若n是奇数,可以实现完全的译码,称为完备译码
- 若n是偶数,则会出现1、0个数相等的情况,将导致译码失败,称为不完备译码,但由于检出了错,可作删除处理或结合ARQ进行译码
重复码特点
- d = n,随着n的增大,纠错检错能力越来越强,但R = 1/n随之下降,编码效率越来越低
- 检错能力大于或等于纠错能力
汉明距越大,纠错检错能力越强
奇偶校验码
若添加的校验位使得每个码字中1的个数为偶数,则为偶校验,反之为奇校验
奇偶校验码特点
- d = 2,能检所有奇数个错
- R = (n –1)/n,编码效率很高。随着n的增大,编码效率趋近于1,但d /n 则趋近于0,即抗干扰能力下降
9-3 纠错编码方法的性能评价
编码性能优劣可以用最小码距 的大小来表征
定理 9.1 任一 分组码,若要在码字内:
- 检测 个随机错误,则要求
- 纠正 个随机错误,则要求
- 检测 个并纠正 个随机错误,则要求
第十章 线性分组码
10-1 近世代数的基础知识
10-1-1 整数的有关概念
- 最大公约数(a, b)的性质:任意正整数a, b,必存在整数A, B,使
- 同余:
- 剩余类:余数相同的数
10-1-2 群的基本概念
定义 10.4 设G是非空集合,并在G内定义了一种代数运算, 若满足如下四个条件,则称G为一个群:
- 封闭性。 对任意,,恒有。
- 结合率成立。对任意,,,恒有 。
- 若 G 中有一元素e,对任意的 ,满足 ,则 e 称为单位元或恒元。
- 若对于任意 ,G 中存在有另一元素 ,使 ,则 称为 a 的逆元。
- 若群G的二元运算满足交换率,即若 ,,有 ,则称群 G 为交换群,亦称为 Abel 群
- 群中元素的个数,称为群的阶。根据元素个数是否有限,可以分为有限阶群和无限阶群
定理 10.1 群具有如下性质:
- 群 G 中恒元是唯一的;
- 任一个群元素的逆元是唯一的。
定义 10.5 若群G的非空子集H对于G中定义的代数运算也构成群, 则称H是G的子群
定义 10.6 设G的子群 , 但 , 将它与 中的元依次相加, 得 , 称 为 的一个陪集 (Coset), 称为该陪集的陪集首。
- H的陪集可能有许多个,因此可以将H进行陪集展开。G的每一元仅在子群H的一个陪集中
10-1-3 环的基本概念
定义 10.7 非空集合 R 中, 若定义了两种代数运算加和乘, 且满足
- 集合R在加法运算下构成 Abel 群;
- 乘法有封闭性, 即对任何 , 有 ;
- 乘法分配率及结合率成立, 即对任何 和 有 则称 是一个环。若环 对乘法满足交换率, 即对任何 元素 和 , 恒有 , 则称此环为交换环或 环。
性质:对于任何 ,
- 环中可以有零因子:即两个非零元素相乘得到0
- 有零因子环中乘法消去律不成立
- 无零因子环中乘法消去律成立
- 有单位元且每个非零元素有逆元、非可换的环,称为除环
10-1-4 域的基本概念
定义 10.8 非空元素集合F, 若在F中定义了加和乘两种运算, 且满足
- F关于加法构成Abel 群, 其加法恒元记为 0 ;
- F中非零元素全体对乘法构成Abel 群, 乘法恒元记为 1 ;
- 加法和乘法间有如下分配律:,则称 是一个域
域是一个可换的、有单位元的、非零元素有逆元的环。
定理 10.2 域具有如下的基本性质:
- 域中一定无零因子, 即: 若 , 则
- 任何 , 有
- 若 且 , 则 ;
- 若 且 , 则 。
3种典型的有限域:
- 二元域 : 集合 在模2加法和模2乘法下, 是 两个元素的域
- 元域 :令 为素数,集合 在模 加法和模 乘法下是阶为 的域, 称为素域GF
- 扩域GF : 将素域 扩展成有 个元素的域, 即得 的 次扩域 。扩域GF 可用一个多 项式 来描述
特征:最小的正整数 使得 即
- 素数域 的特征是
- 有限域的特征是素数
- 是 的子域,有 是 的幂
定理 10.13 有限域的阶必为其特征之幂
域元素 a 的阶:最小的正整数 使得
-
- 元素 和 在GF 乘法下形成群, 称为循环群
- 若 , 则
- 若 , 令 是 的阶, 则 能被 除 尽。如果 的阶是 , 则称 是本原的, 为本原元素,简称本原元。本原元素的各次幂生成GF 的所有非零元素
- 若 的特征为 , 且 , 则
10-1-5 二元域的运算
系数取自 GF(2) 的 n 次多项式:例如序列 10011:
- 可以按普通方法加减乘除
- 满足交换律、结合律、分配律
- 可做长除法
既约多项式
定义 10.9 若GF(2)上的m次多项式不能被GF(2)上的任何次数小于 m 但大于零的多项式除尽, 就称它是GF(2)上的既约多项式(约到头的多项式)
例如 是4次既约多项式
- 对任意m≥1,存在有m次既约多项式
- 能被分解因式的,都不是既约多项式
- GF(2)上的任意m次既约多项式,除尽
本原多项式
定义 10.10 若 m 次既约多项式 p(x) 除尽的 的最小正整数 n满足 , 称p(x)为本原多项式
- 本原多项式一定是既约的,因为它是用既约多项式来定义的,但既约多项式不一定是本原的
- 对于给定的m,可能有不止一个m次本原多项式。
10-2 线性分组码的编码
10-2-1 有关概念
定义 10.12 码长为n,有 个码字的分组码,当且仅当其 个码字构成域 GF(2) 上所有n重矢量空间的一个k维子空间时,称该分组码为(n, k)线性分组码
- n重二进制码元组成的集合 称为二进制的矢量空间
- 矢量空间 的一个子集 S 如果满足以下两个条件,则称其为 的一个子空间
- 全0矢量在S中
- S中任意两个矢量的和也在S中(即满足封闭性)
- 假设 和 是 二进制分组码中的两个码字(或码矢量), 当且仅当 也是一个码矢量时, 这个码才是线性的; 特别地,当 时,
- 二元分组码是线性的充要条件是两个码字的模2和也是码字;或者说线性分组码的子集以外的矢量不能由该子集内的码字相加产生
分组码的线性只与选用的码字有关,而与消息序列怎样映射到码字无关
称满足 映射为码字 的关系为线性分组码的特殊关系
- 只要全0的消息序列映射为全0的码字,都能满足特殊关系
定理 10.5 线性分组码的最小距离等于非零码字的最小重量
10-3-1 伴随式译码
令 是线性码 中重量为 的码矢数目, 是二 进制对称信道 (BSC) 的转移概率, 若在 上 只用 来检错, 用 表示末检出错误的概率, 即错误图样恰 好为码字的概率。对于任意重量 , 这种情况的概率 为 而重量为 的码矢数目为 , 考虑到全部 的 , 故有
10-3-2 标准阵
定义 10.14 把 个可能的接收矢量划分成 个不相交的子集,使每个子集只含有一个码矢,这个阵列称为标准阵
落在一个子集里的接收矢量就判给同一个码字

一行是一个陪集
- 应该要把重量较小的码字作为陪集首(第一列),这样能译为离接收码字最接近的码字
- 令 表示重量为 的陪集首的数目, 称 为陪集首的重量分布, 当且仅当错误图样不是陪集首时才出现译码错误, 故对于转移概率为 的二进制对称信道 而言, 采用标准阵译码方法所产生的译码错误概率为
- 一个陪集的所有 个码字有同样的伴随式,不同陪集的伴随式互不相同
10-3-3 伴随式译码的一般步骤及性能
定理 10.7 按照标准阵将接收码字译为它与它所在陪集的陪集首的模2和的译码算法是最小距离译码算法
10-4 线性分组码举例
定义 10.15 距离为 3 的线性分组码 为汉明码, 其中 为任何不小于 2 的整数。 汉明码能够纠正 1 个错误, 它的码长 , 消息序 列的长度 , 一致校验部分的位数 , 故其编码效率为
定义 10.16 设C是 线性分组码,其纠错能力为t。如果用且只用不大于t个错误的全部错误图样作陪集首就能构成标准阵,那么就称这个码为完备码。
第十一章 循环码
11-1 循环码的描述
11-1-1 循环码的定义
定义 11.1 一个(n, k)线性分组码C,若它一个码矢的每一循环移位都是C的一个码字,则C是一个循环码
定理 11.1 设循环码的码多项式为 , 循环移位 次后 的码多项式为 , 则 是 除多项式 所得之余式。
定理 11.2 循环码C中,次数最低的非零码多项式是惟一的。
定理 11.3 令 是 循环码 C中最低次数的非零码多项式, 则常数项 必为 1 。
定理 11.4 令 是一个 循环码 C中次数最低的非零码多项式, 一个次数等于或小于 次 的二元多项式, 当且仅当它是 的倍式时才是码多项式。
定理 11. 4 说明,一个次数等于或小于 次的二元多项式是码多项式的充要条件为它是 的倍式。
定理 11.5 循环码的生成多项式 是 的因式
定理 11.6 若 是一个 次多项式且是 的因式,则 生成一个 循环码。
任何一个码字都是
11-1-3 生成矩阵和一致校验矩阵
若待编码的消息用行矩阵表示为 则非系统循环码的编码输出为 由 可得非系统形式的一致校验矩阵
系统码
系统形式的循环码生成矩阵,由非系统形式的生成矩阵通过行变换而获得
对所有的 , 用生成多项式 除 ,有 其中 是余式,表示为 因此 是 的倍式,即码多项式。系统形式的生成多项式为
11-2 循环码的编码和译码
11-2-1 循环码的编码
系统循环码: 定理 设循环码的生成多项式为, 待编码的消息多项式为 和 的次数分别是 和 , 则 为码多项式, 用此方法编得的码字为系统循环码。
11-2-2 循环码的译码和错误检测
伴随多项式
定理 11.8 令 是接收多项式 的伴随多项式, 则用生成多项式 除 所得之余式 , 就是 循环移位一次 的伴随式。
推论 用生成多项式 除 所得的余式 , 是 的第 次循环移位 的伴随式。
英文技术写作
Unit 1 Definition of technical writing
Introduction
- Definition
- Technical writing: a form of written document providing technical information that help readers to solve complex problems
- Main features
- Reader-centeredness
- Clear organization and page design
- Readable style and effective visuals
- Purposes
- inform
- instruct
- persuade
How to meet the needs of specific audiences
- Who will use your document?
- Why they will use it?
- How they will use it?
| Who will use the documents? | At what level of technicality? | How much do these readers need? |
|---|---|---|
| Experts | Highly technical | Just the facts & figures |
| Informed persons | Semitechnical | Facts & figures explained |
| Laypersons(外行) | Nontechnical | Facts & figures explained in simplest terms |
Ethical issues
Ethics(伦理学): Moral beliefs and values
- Rules or principles
- Behaviors
How is ethics related to technical writing
- Reporting and analyzing data honestly
- Balancing between production and safety
- Avoiding burying bad news in paragraphs
Process for writing technical documents
The five steps are not linear
- Planning
- Analyze your audience
- Analyzing your purpose
- Generate ideas about your subject
- Research additional information
- Organize and outline your document
- Select a design or a delivery method
- page layout
- typography
- use of color
- Devise a schedule and a budget
- Drafting
- Revising
- Editing
- grammar
- punctuation
- style
- usage
- diction
- mechanics
- Proofreading
Writing style and tone
- Clarity
- Use active voice whenever possible(主动句)
- Avoid overstuffed sentences(避免长难句)
- Conciseness
- Clear writing
- Compressed writing
- Fluency
- Appropriate tone
Unit 2 Technical document design
Design Principles
- To make a good impression on readers.
- To help readers understand the structure and hierarchy of the information.
- To help readers find the information they need.
- To help readers understand the information.
- To help readers remember the information.
- Proximity(行距)
- Alignment
- Repetition
- Contrast
Designing Visual Information
Types of visuals
- Table
- Numerical tables
- Prose tables(文字表格)
- Graph
- Bar graphs
- Line graphs
- Chart
- Graphic illustration
How to choose the right visuals
- What is the purpose for using this visual?
- Convey facts and figures -> Table
- Draw conclusions -> Graph
- Who is my audience for these visuals?
- Expert audiences
- General audiences
Designing Documents
- Shaping the page
- Provide page numbers, headers and footers
- Use a grid
- Use white space to create areas of emphasis
- Make lists for easy reading
- Styling the words and letters
- Select an appropriate typeface: Serif(衬线), Sans serif(无衬线,Sans 是 without 的法语)
- Use full caps sparingly
- Adding emphasis
- Indention
- Lines
- Boldface
- small or large type sizes
- color
- Using headings for access and orientation
Unit 3 Correspondence
Presenting yourself effectively in correspondence
Steps of the writing process:
- Prewriting / Planning
- purposes
- audience
- tone and content
- communication channel
- Writing / Drafting
- organize content logically
- choose a method of organization
- Rewriting
- revising
- editing
- proofreading
Principles of effective communication:
- Use the appropriate level of formality
- Communicate correctly
- Project the "You Attitude" = looking at the situation from the reader's point of view
- Communicate honestly
- Seeking the goodwill of readers
Writing messages
Text messaging:
- the delivery of exchange of brief written messages via mobile phones or networks.
Characteristics:
- simple messages
- people on the move,
- near-instant, brief written exchanges
Benefits of text messages:
- Increased speed of communication
- Improved communication efficiency
- Less intrusive communication channel
- Low cost
- Multitasking
- Decreased intimidation(恐吓)
- Easy documentation
Potential Problems:
- Reduced professionalism
- Security issues
- Employee misuse and distraction
- Lost productivity
How to avoid:
- Decide whether text messages are suitable for the writing situation.
- Consider the length and formality of the text messages.
- Clearly and briefly explain the context of your message
- Summarize decisions.
- Document important information.
- Plan for handling emotions effectively.
How to write text messages effectively:
- the appropriate software or tool to use
- the contact list
- messaging policies of the employer
Ready to write
- no format
- informal tone
- a limit on the number of characters
- abbreviations and shortened spellings
Writing emails
- short, informal
- longer, formal
- attachment
Advantages
- quick and efficient
- useful when people are in different time zones or have different working schedules
- convenient attaching
- paper-free and cost effective
- easy documentation
Parts and Format of Email
- Heading section
- “To”
- “From”
- “Subject”
- Salutation
- Introductory paragraph
- Body text
- Conclusion
- Complimentary closing
- Signature block: contact information of the writer
Tips of writing emails
- Find out your organization's email policies first.
- Recognize your audience.
- Identify yourself by name, affiliation, or title.
- Provide an effective Subject line.
- Keep your email messages brief and each paragraph short.
- Organize your e-mail message.
- Proofread your email message
- Be careful when sending attachment
- Be courteous and professional.
Writing memos
Memos are used within organizations for
- routine correspondence
- short reports
- proposals
- other internal documents
Key points included:
- identification lines: TO, FROM, DATE, SUBJECT
- introduction: one or two clear introductory sentences about the topic and the purpose
- discussion: developing the content specifically making the text reader-friendly
- conclusion: concluding the memo with "thanks" and/or directive action.
- audience recognition: in-house audience(内部受众) -> acronyms and internal abbreviations(首字母缩写和缩写)
- appropriate memo style and tone: one page long with simple words, short sentences, specific detail, and highlighting techniques, informal and friendly tone
A template for memos:
- Introduction: A lead-in or overview stating why you are writing and what you writing about.
- Discussion: Detailed development, made accessible through highlighting techniques, explaining exactly what you want to say.
- Conclusion: State what is next, when this will occur, and why the date is important.
Unit 5 Instuctions
Designing and writing instructions
- audience recognition: level of readers' knowledge
- Don't assume anything
- spell it out clearly and thoroughtly
- language style
- imperative mood + active voice + present tense
- clarity
- short, simple steps in proper sequence
- use first, next, finally
- use numbers
- planning ahead
design instructions based on
- audience
- purpose
- subject
S-S-S: short-simple-sincere
Misleading TC:
- false implications
- exaggerations
- legalistic constructions
- euphemisms(委婉)
ethics in TC:
- 4 standards: rights, justice, utility and care
proposal
- background
- problem
- proposal
presentation
clear and sturctured
no thank for time in intro
no pause after each main point
chair and host dont ask
leave a clear summary
signposting
not organized depend on title(头衔)
tone: approvable formality
不能指代不明,譬如只写 one of
- BC: blind copy
- CC: courtesy copy
得分要点:
- 重要信息点是否全面(time,date,location, etc.)
- Purpose (e.g., I’m writing to inform…)4
- Opening (address, Greetings)2
- Closure (e.g., Yours, Sincerely, etc.)2
- Politeness (e.g., Please feel free /don’t hesitate to contact me if you have any questions,I’d appreciated it if you reply soon/should eliminate impolite words...)
- Language (correctness, appropriateness)
格式:
- 开头靠左 Dear xxx:
- 没有首行缩进,段间空行即可
- 目的 I'm writing to
- Firstly, secondly, ...
- 末尾 Don't hesitate... Thank you.
- 结尾靠左 Sincerely 换行 xxx
instruction
4 elements:
- title
- intro
- step-by-step instructions
- conclusion
glossary(术语表):
- defines unfamiliar terminology(术语)
typically limited in its subject
closely connected with process description
noun string should be avoided in the title
得分要点:
- 步骤以时间顺序排列
- Number the steps (以数字标注每一步骤)
- imperative mood(使用祈使句)
- 每一步骤包含一个信息点
- Language (correctness, appropriateness)
user manual
大写用于 warning 或 danger(即 signal words),但要用就全部大写
resume
also called functional resume
- generous margins
- clear style
- balance
- clear organization
individual fields of competence
all / every 慎用
得分要点:
- Identification lines
- Career objective: precise and specific
- Summary of qualifications: list, parallel phrases
- Employment (job title, name of the company, location, time period, job duties, etc.)
- Education: reverse chronological presentation
- Professional skills: quantify
memo
diagonal communication: 不同部门上级对下级
moderately formal tones
delivered at company's in-house mail procedure
"purpose is to do sth."
往往有两份
action items / steps: placed in recommendation
得分要点:
- Subject line should be specific
- Discussion:有条理;easy on your eyes
- Recommendation:polite
- Language:appropriate and grammatically correc
生词
- excerpt:摘录
- intonation:语调
- confrontation:对抗
- rehearse:排练
- catalyst:催化剂
- forge:伪造
- credibility:可信度
- proceeding:会议论文集
- prelude:前奏
- customary:习惯的
- diagonal:对角的
- netiquette:网络礼仪
- tailor:缝制
- impromptu:即兴的
- gerund:动名词
- internship:实习
- prominent:凸出的
cover letter
这一页为应试笔记,全是陈明灌输的狗屎毫无价值
典型题目:
- 2.5.5
- 4.4.1
- 6.4.2
- 7.LT.4,7.LT.6
第五章切入点很可能不是 而是
第七章有大问题!
6,7,8没怎么看
两个随机变量和的概率密度函数是它们各自概率密度函数的卷积,是它们联合概率密度函数的二次积分(分布函数)的导数
第一-三章
离散时间随机过程在 n 个时刻的取值一定是一个 n 维随机变量
看到正态多想想算均值和方差(前提是目标也是正态)
离散熵和连续熵定义不一样(狗屁,就是一样的)
随机过程是一个无穷维的随机向量
均方相等>处处相等>分布相等
独立一定不相关,不相关不一定独立;独立不一定正交
随机过程不能定义为样本函数的集合(因为随机过程是变函不是集合)(狗屎)
熵有负号
Poisson分布:
- 概率质量函数:
- 概率生成函数:
指数分布:
- 概率分布函数:
- 概率密度函数:
- 概率特征函数:
一个多维随机变量的所有边界概率密度函数,不能推出其联合概率密度函数
第六章
随机过程在某个时间点/区间上的均方导数/积分是一个随机变量,其描述的一族样本函数在该时间点/区间上的导数/积分随机变量在均方意义上的收敛。
表示均方求导
均方收敛表示大部分样本函数收敛,但是有一小撮可以不收敛
第八章
统计推断:已知两个边界事件的联合概率函数,然后根据可观察到的一个边界事件的取值,推断另一个不可直接观察的边界事件的取值
若实随机信号的功率谱密度在 (直流)点不为零,且其支集包含于零点的一个邻域内,则为带限随机信号。
将带限随机信号输入一个线性系统,其输出只与该线性系统的传递函数在带限内的取值有关。
Hilbort 变换将信号的正频率部分相移负90度,负频率相移90度,去除直流部分。也就是通过 的线性时不变系统。
宽平稳高斯通过线性系统后变为严平稳。
功率谱密度所定义的带宽没有真实频谱意义
第十-十二章
- 非因果:
- 因果:
-
- 的分子和分母均为 形式,
- 的分子和分母均为 形式,
-
- 为 形式,
- 为 形式,
-
最小错误概率就是最大后验概率 <= 最大似然检测的错误概率
第十三-十五章
题中给的离去率是每个窗口的,故总的要乘
稳态方程:项取箭头的起点,若起点为本身,则为负
非齐次 Poisson 过程是 Markov 过程,Poisson 过程是齐次 Markov 过程
生灭过程的Q矩阵是三对角的(就是只有主对角线和旁边两条次对角线非零)
排队过程都是连续时间 Markov 过程
第一章 概率空间和随机变量
1-1 概率空间
1-1-1 样本空间
N 维样本空间:N 个一维样本空间的笛卡尔乘积。例如空间坐标分布(x,y,z)就是一个 3 维样本空间
多维和无穷维样本空间也称为乘积样本空间
此外,对于所有满足 的正整数 ,称集合 中任意 M 个集合的笛卡尔乘积为M 维边界样本空间
1-1-2 Borel 事件集
Borel 事件集
空、全、补、并 设 由样本空间 的一些事件组成的集合,如果事件集 A 满足下面的三个性质:
- 若 ,则
- 若有 ,则
则称事件集 为定义于样本空间 上的 Borel 事件集。
也就是闭合:空集、全集、补集、并集都在事件集中
Borel 事件集所满足的上述三个性质规定了事件间应满足的基本逻辑事实: 第 1 条性质规定必然事件 S 和不可能事件 必须作为考察的对象,第 2 条性 质规定了一个事件的反面也构成一个事件,第 3 条性质规定了任意多个事件的 并也构成一个事件。规定事件集满足如上所述的三个 Borel 条件,是为了保证 所有需要考虑的事件在逻辑上具有相容性。
1-1-3 事件的概率
概率是事件频率稳定性的模型
事件的频率定义为,在若干次试验中某个事件出现的次数占试验总次数的比例。设有事件 A,其频率 F(A) 定义为
在不同时间或地点,针对同一种非确知系统做多次试验,当试验的次数 T 超过一定规模时,则不论 T 是多少,也不论观察哪一个事件 A,事件 A 的频率 F(A) 总是与一个固定的常数相差不远,或者说在该常数左右作微小波动,这种现象称为事件的频率稳定性。
概率是频率所遵循的绝对规律,频率是在概率这个绝对规律之 上,叠加一些小扰动之后的具体表现。
- 概率九事:非确知系统、试验、样本点、样本空间、事件、Borel 事件集、事件的频率、频率稳定性、概率。
- 概率三要:样本空间、Borel 事件集、概率集函数。三要是概率概念的略说,九事是详说。
- “随机”不是前一瞬间的条件固定,下一瞬间的结果可以有多种;而是前一瞬间的条件没有办法完全观察或测量到,于是就无法预测下一瞬间的试验结果。随机与非随机不是系统固有的属性,而是观察者根据自己的观察能力对系统所做的分类。
- 事件的频率稳定性是系统内部微观机制稳定性的一种体现。
- 事件的概率是事件频率的稳定值。
- 概率的作用有两个:一是预测非确知系统事件未来的发生频率,二是根据可观察的边界事件,推断不可观察的边界事件。
1-1-4 边界
乘积样本空间的事件称为联合事件,一个联合事件在其边界样本空间上的投影称为边界事件。
似乎就是说投影到低维度上。。
单满映射就是双射,也就是一一映射。
概率集函数:设 为 定义于样本空间 上的 Borel 事件集,则映射 为概率集函数
概率空间:由“样本空间 S、Borel 事件集 A、概率集函数 P”这三者组成的一个集合,记为
S 生成 A,P 度量 A
1-2 事件间的关系
1-3 随机变量
1-3-1 标准概率空间
最常见的标准样本空间有以下几类:
- 实数空间: ,其中 为可数无穷;
- 复数空间:,其中 同上;
- 实(复)函数空间:,其中的 是不可数无穷, 的定义如下 其中 是某个不可数的一维指标集合,如一维闭区间。此时, 表示的是由定义于区间 上的实函数或复函数组成的集合。
非标准概率空间的标准化
假设 是上面所说的三类标准样本空间, 是某个概率空间 的 样本空间。若存在 到 上的单射 ,则 与 之间就建立了一个单满映射(也即双射),于是就可以用标准样本空间的子集 来代替 。
若 非空,则可以将事件 的概率定义为零。譬如抛硬币 ,且定义 的概率为零。
若有一个函数 ,则显然这个函数对应着如下的无穷维向量:, 有时候将此向量表示为 或者 。此时,函数的定义域就是该无穷维向量的维数指标集,而函数在定义域内每个元素上的取值就是该向量在该维数上的取值。
若有一个函数 ,其中 是某个不可数的一维指标集,则这个函数对应着如下的不可数无穷维向量:。此时,函数的定义域就是该不可数无穷维向量的维数指标集,而函数在定义域内每个元素上的取值就是该向量在该维数上的取值。
随机变量
随机变量本质上是变量。
随机变量实际上是传统变量的“升级版”,它在“兼容”传统变量所有属性的同时,还增加了取值概率属性。
随机变量按照其维数可以分为有限维和无限维两种。有限维随机变量又可以分为一维随机变量和多维随机变量两种,无限维随机变量又可以分为可数无限维随机变量与不可数无限维随机变量两种。
多维随机变量有时候也被称为随机向量,如果多维随机向量以矩阵的形式呈现,也称为随机矩阵。
因为一个无限维的向量可以看作一个函数,所以一个无限维的变量就称为一个变函,一个无限维的随机变量也称为随机变函。
如果一个随机变函变化范围内的所有函数具有相同的定义域,且此定义域是时间指标集,则称该随机变函为随机过程。或者说,一个无穷维随机变量的维数指标如果具有时间的物理意义,该无穷维随机变量也被为随机过程。
随机变量变化的样本空间如果是实数空间,则称为实随机变量;随机变量变化的样本空间如果是复数空间,则称为复随机变量。从维数的角度来观察,对任意 ,n 维复随机变量在本质上就是一个 2n 维的实随机变量。
第二章 一维随机变量
2-1 一维随机变量的定义
当考虑变量 的取值频率时,其就成了一个一维随机变量 。
2-2 概率密度函数
概率分布函数:
性质:
- 单调递增
- 右连续,即
概率密度函数定义为概率分布函数的广义导数:
性质:
2-3 数字特征
- 均值:
- 均方:
- 方差:
- 阶原点矩:
- 阶鿇对原点矩:
- 阶中心矩:
- 阶绝对中心矩:
2-3-3 熵
- 事件的信息量:
- 一维随机变量的熵:
常见分布
对数分布:
Cauchy分布:
- 概率密度函数:
- 概率特征函数:
Laplace分布:
- 概率密度函数:
- 概率特征函数:
Poisson分布:
- 概率质量函数:
- 概率生成函数:
- 均值:
- 方差:
指数分布:
- 概率分布函数:
- 概率密度函数:
- 概率特征函数:
概率质量函数和生成函数只能描述离散,而分布函数、密度函数和特征函数可以描述离散和连续
- 概率质量函数:,实际上是离散的概率密度函数
- 概率生成函数:,概率质量函数的 z 变换
- 概率分布函数:,离散和连续都有
- 概率密度函数:,pdf
- 概率特征函数:,概率密度函数的 负Fourier 变换
第三章 多维随机变量
联合概率分布函数中令某个分量趋于无穷大,就得到边界概率分布函数
- 概率密度函数:,有
- 联合概率密度函数:为联合概率分布函数的 n 阶导数
- 联合概率分布函数:
- 边界概率密度函数:
3-3 数字特征
-
均值:
-
均方:
-
方差:
-
相关矩:
-
协方差:
-
相关系数:
-
联合原点矩:
-
联合中心矩:
-
相关性:协方差不恒为 0
-
独立性:边界密度函数之积等于联合密度函数
3-4 多维随机变量分量间的关系
- 条件概率密度函数:
- 条件期望:
复随机变量
一维复随机变量:
- 均值:
- 方差:
第四章 离散时间随机过程
若概率空间 的样本空间 由定义在自然数集 之上的函数组成,此时 中的样本点是定义域离散的函数,称为 样本函数,可以记为 ;而在 中变化的变函,即随机变函,记为
样本函数个数:似乎对应于事件的种类,譬如随机发送全0或全1的发送端,其接收端的信号就只有两个样本函数。每次试验就会生成一个样本函数,所以只有多次试验完全一致时,它们才共用一个样本函数。
样本点可以理解为一个命运,即横轴为时间,纵轴为取值的曲线;样本函数则为一系列命运的模板
4-2 概率函数族
联合概率质量函数 称为离散时间随机过程 的 维概率质量函数, 是状态空间的样本点,称 为 的概率质量函数族。
称为 维概率生成函数, 称为 维概率密度函数,
4-3 矩函数
- 均值函数:,A 为 X 中的随机变量
- 方差函数:
- 自相关函数:
- 自协方差函数:
- 自相关系数函数:
4-4 常见离散时间随机过程
独立过程
Poisson 过程是独立增量过程
和过程
为 的和过程
生成函数:
概率质量函数(独立增量):
二阶矩过程
如果离散时间随机过程 对于每个 n,一维随机变量 的方差都存在,则为离散时间二阶矩过程。
严平稳与宽平稳过程
严平稳过程:若对于任意正整数 K 和任意采样时刻 ,随机过程 的 K 维概率分布函数对任意整数 n 满足: 则为严平稳过程。
宽平稳随机过程:若离散时间随机过程 的均值函数 为常数,且自相关函数 只和时移 有关,即 可以表示为 n 的函数 ,则为宽平稳随机过程。
若随机过程 和 都是宽平稳离散时间随机过程,且互相关函数 只和时移 n 有关,即 ,则称 和 为联合宽平稳离散时间过程。
,A、B 为两个随机变量
高斯过程的二维概率密度函数:
第五章 连续时间随机过程
随机过程不是集合
m 维概率分布函数:
联合概率质量函数中,两个过程中的随机变量取值是统一的
第六章 二阶矩过程的数学分析
6-1 离散时间随机过程的均方收敛
概率分布意义上相等:概率分布函数恒等:
概率意义上相等(几乎处处相等):事件发生概率相等:
均方意义上相等:X 与 Y 的二阶矩存在且满足 (即均方收敛)
Loève准则: 均方收敛 当且仅当 序列 的自相关函数 满足 ,C 为常数。
若 均方收敛至 ,则
6-2 连续时间随机过程的均方连续
对于设有定义于时间指标集 上的连续时间随机过程 是 或某个区间 ,若对 ,当 时有 则称随机过程 在 点均方连续; 若对 内任意一点 都在 点连续,则称 在 上均方连续。
性质:若 为宽平稳过程,则 在 上均方连续,当且仅当 在 点连续。
6-3 连续时间随机过程的均方导数
设有定义于连续时间指标集 上的随机过程 ,若有
则称 在 点均方可导,并称 为 在 点的均方导数, 有时也记为 或 。若对任意 都均方可导,则称 在 上 均方可导。
也即:
在 点的 阶均方导数可以递归地定义为
6-3 连续时间随机过程的均方积分
可积的证明,可以先算出 的积分为 ,然后再证明 的导数为 ,以及 即可
第七章 随机变量的变换
7-2 有限维随机变量间的变换
定理7.2.1:设一维随机变量 X 的概率密度函数为 , 是单调可微函数,则 Y 的概率密度函数为
定理7.2.4:同维变换时,若 ,则有
定理7.2.6:若 有一阶偏导数,则有 其中, 为 的 N 个实根, 为下列 Jacobi 矩阵:
若 无解,则
第八章 离散时间信号分析
维纳—辛钦定理:若离散时间过程 宽平稳,其自相关函数为 且满足 ,则
- , 为系统冲激响应
白噪声:功率谱密度 为常数
实~~宽平稳~~过程的功率谱密度是偶函数
输入与输出的功率谱传输特性
可以全程用 z 变换代替,其中
自回归(AR)模型
定义:,W 为白噪声序列
- 传递函数:
第九章 连续时间信号分析
维纳—辛钦定理:若连续时间过程 宽平稳,且其自相关函数 满足 ,则
传递函数计算举例:
卷积:
Poisson 随机电报过程
是宽平稳过程
设信号平均传输速率为
- 自相关函数为
- 功率谱密度为
3dB 带宽
使功率谱密度大于 的频率范围
等效带宽
第十章 信号检测
信号的统计推断又称为统计信号处理,是指根据观察数据与待推断数据之间的先验统计关联信息 (如联合概率密度函数、条件概率密度函数等),由观察数据的情况来推断另一个阈值关联的数据情况。
所谓假设检验,就是在已知 不可直接观察的随机现象的样本空间 和 可直接观察的随机现象的样本空间 的联合概率函数的条件下,根据当前观察到的 的取值,来推断到底是 中哪一个假设导致了目前的观察值。
信号检测是假设检验的一种,当观察空间和待检验空间都是信号时,这种假设检验就是信号检测。
10-2 常见判决准则
Bayes 判决准则
如果输入 “假设” 为 , 设 为将 判定为 的代价, 所谓 Bayes 䖺堆则就是观测空间的一个判决分割 , 这种判决分割使下列风险收敛达到最小, 即
为在判决分割 下将 判决为 的概率
定理 (二择一 Bayes 检测) 只有两个 “假设” 的 Bayes 检测, 代价满足 。设两个 “假设” 分别为 , 观测空间 , 设观察向量为 , 记 则 的 Bayes 判决区域为 的判决区域为 。这里 被称为似然比, 被称为门限似然比。
第十一章 信号参数估计
估(ū)计:连续(ù);假设检验(àn):离散(àn)
信号估计按照其待估计的对象可以分为“信号参数估计”与“信号波形估计”这两类。
参数估计:有限维;波形估计:无限维
11-2 常见估计准则
11-2-2 最大后验概率估计
最大后验概率估计就是用 使后验概率质量函数 或后验概率密度函数 达到最大值的 作为 的估计值,写成数学表达式就是
一般来说,假设后验概率函数的所有一阶偏导数存在,则最大后验概率估计 是下列线性方程组的解:
11-2-3 最大似然估计
设观测值为 ,待估参数为 ,最大似然估计就是用使条件概率密度函数 (即 )达到最大值的 作为 的估计值,写成数学表达式就是
该条件概率密度 又称为似然函数。假设似然函数的所有一阶偏导数存在,则最大似然估计 是下列线性方程组的解:
似然函数可以写为
11-2-3 最大均方误差估计
定理:使均方误差达到最小的估计字具有如下表达式: 且最小均方误差估计是无偏估计,即
11-3-3 参数估计举例
信号的频率估计
若传输信号具有形式: 式中,幅度 A 和相位 为常数; 是待估参量。假设 是 上的均匀分布,此问题的似然函数为
若 , 则
第十二章 信号波形估计
12-2-2 离散时间信号的 Wiener 滤波
最佳滤波器的系统函数为
这样决定的 ,使最小误差为
因果问题的求解
例:设 ,其中 是自相关函数为 的一阶过程; 是均值为零、自相关函数为 的白噪声,且 相互独立。 下面确定非因果和因果离散线性滤波器,使输入 的输出 的均方误差达到最小, 即 达到最小。
解:显然白噪声 的自相关函数的 变换为 ,而 的 变换为 另外,此时 。因此可知非因果滤波器的系统函数为 式中 因此,冲激响应为 下面来求因果解。第一步,有 因此 第二步,有 因此 第三步,有
第十三章 离散时间 Markov 链
常返状态是经过无穷多步后仍要返回的状态,而瞬过状态是经过足够大的步数后,就不会再返回来的状态(也就是有概率再也回不来的)
离散时间 Markov 过程是具有一阶记忆特性的离散时间随机过程,而 离散时间 Markov 链则是状态离散的 Markov 过程。设 为一个离散时间 Markov 链,则转移概率质量函数满足 (这是 Markov 链的充要条件)
齐次连续时间 Markov 链的状态停留时间是指数分布的随机变量
嵌入 Markov 链是离散的
13-1-2 状态方程
记 为 Markov 过程 在时刻 n 出现状态 i 的概率,称为 的状态概率。 称 为 Markov 过程 的状态过程矢量。显然 。
记 表示在时刻 m 时状态为 i 的条件下,到时刻 n 状态为 j 的条件概率,称为 Markov 链 的转移概率。称矩阵 为从时刻 到时刻 的状态转移矩阵。显然矩阵的每一个元素都非负且每行的和为 1 ,即 显然,由全概率公式知 若 ,则由 和 知
13-1-3 齐次与平稳 Markov 链
齐次 Markov 链
若有 对任意 成立,即转移概率 只和时间间隔 有关,与起点时刻 无关,则为齐次 Markov 链。
平稳 Markov 链
当齐次 Markov 链的状态概率矢量 为常矢量时,为严平稳 Markov 链,有
13-2 平稳 Markov 链的状态分类
若存在 ,使 ,则称状态 j 是从状态 i 可达的,记作 , 两个互相可达的状态 i 和 j 称为互达的,记作 。
互达性是一种等价关系,满足自反性,对称性和传递性。
在集合 中,所有和 等价的元素构成 的子集,称为一个等价类 。
若 Markov 链 的所有状态都属于同一个等价类,即所有状态都互达,则称该 Markov 链是不可约的,反之为可约的
状态空间分解定理 状态空间 必可分解为 式中, 是瞬过状态的集合; 是两两互不相交的由常返状态组成 集,且满足如下条件:
- 对每个 内任意两个状态是互达的。
- 对任意 ,以及任意 和 和 互不可达。
- 零常返:返回自身所需的步数为无穷大(只存在于无限状态的 Markov 链中)
- 正常返:返回自身所需的步数为有限数
- 记 为首次返回状态 i 需要的步数,
- :零常返;:正常返
常返状态的周期
对常返状态 i,使 的所有 n 的最大公约数称作状态 i 的周期,记作 。
- 若对所有 ,都有 ,则约定 i 的周期为 ;
- 若 ,则称状态 i 为非周期的(即任意步上都能返回)
等价类同周期
遍历:非周期的正常返状态
第十四章 连续时间 Markov 过程
齐次连续时间 Markov 过程在时间段 内保持在状态 的概率为 因此在时间段 内离开状态 的概率为 从式 (14.1.8) 可以看出, Markov 链离开状态 的概率和时间近似成正比, 比例系数 称 为状态率。 齐次连续时间 Markov 链从状态 到状态 的状态转移率定义为 上式用到了
若连续时间 Markov 链的状态数有限, 设为 , 则此时暂态方程为 式中, 矩阵 具有如下表达 而稳态概率满足下列线性方程组
第十五章 排队论初步
用 A/B/C/D 描述排队系统,其中 A 代表用户到达时间规律,B 表示用户服务时间规律,C 表示资源窗口数及其结构,D 表示排队规律。
- 到达率(服务率):()
- 到达间隔(服务时间)的均值:()
- 比例系数:
- ,
- 时
答题要用句子,而不是抄 PPT 的 keypoint
- 有效性
- 可靠性
- 通过性:固定有效性或可靠性的情况下,正确通过信道的比特数
人为增加的冗余具有很强的纠错能力,自然的冗余则没有
故意引入 ISI(其实不是故意引入,而是 ISI 很菜,均衡技术可以轻易去除它),以扩展频宽
移动通信实现了(有人烟的地方)无缝覆盖,这是其相对于 WiFi 等的最大特点。
CDMA 必须扩频
CDMA 是第一个使用同频覆盖的技术
- CDMA 不同径、不同用户间才会有干扰;
CDMA 是自干扰系统,址间干扰的幅度远大于白噪声和多径干扰
信干噪比:信息、干扰、噪声。信噪比主要要考虑放大器的灵敏度
OFDMA(一定要写 A)
CP:循环前缀
OFDM 不适用于上行信道多用户应用:功耗太大
BCH码:
-
经典的纠错编码,固定码率对应固定的可纠错比特数
-
移动:最好
-
有线:至少
ARQ:协议层
HRQ:物理层重传,充分利用错误的帧
HARQ:HARQ ⅲ型:
- 码字重传ⅲ型:在接收侧采用最大比或等增益合并将前面传输未正确解码帧的接收信号和重传帧合并解码
- 递增冗余ⅲ型:重传版本中包含前面发送过的比特和新的冗余比特
同频覆盖可以提高容量,但小区发射功率受限
FDD:频分双工
通信系统仿真方法与技巧
等效基带
信道估计工作点在 以上
四个评价指标
可靠性指标:
- FER or BLER 才是终极指标,BER、Pe 只是简化调试
有效性:频带利用率
复杂度:算法复杂度
频稳度 接收机动态范围
信噪比应取低通滤波器后的,而非宽带信号的信噪比
存储复杂度:以存储器大小来描述,例如 1Mb
输入输出往往占80%的时间
量化:
- 最大值归一化:
- 更好用,但在加噪声后损失不少精度,因为最大值是加了噪声的
- 用于量化后的位数足够
- 功率归一化
- 部分功率归一化
- 大于 2 的再限幅 或
饱和度:被削顶的数据的比例
5G
- 频带利用率增加 10 倍以上
- Massive MIMO 支持 12 数据流(提高 6 倍)
- AMC 支持 256QAM
- 纠错码码率最高提高到 11/12
- 带宽由 20MHz 扩展到 400 MHz(十倍以上带宽,最高传输速率=带宽×频带利用率,百倍)
- 实现复杂度与能耗
- 引入参数化定义(Numerology),支持多种子载波间隔,大带宽下实现复杂度下降
- BWP 使得终端能耗大大下降同时支持灵活调度
- 低时延通过灵活的时隙结构和双工实现
- 高可靠由强大的纠错码、HARQ 和波束赋形提供
- 非公网络(No=n-Public Network, NPN)
- NR-U,非授权频段
- 室内定位:3m
复习
蜂窝,同频覆盖,多址,双工
- 4个用户:HARQ
- 5个用户:多用户分集
考点
3G:扩频+码分多址+蜂窝+同频覆盖 4G: 5G: HARQ: 仿真:
-
每个模块的作用
-
调制(1-P23)
- 如何评估一个调制的好坏?四个核心指标
- 有效性(频带利用率)
- 可靠性
- 复杂度
- 对抗信道非线性 TODO
- 8PSK、4PSK、16QAM、GMSK
- 如何评估一个调制的好坏?四个核心指标
-
对抗信道非线性有哪些技术(1-P28)
- 调制方法:峰均比小,恒包络调制天然抗非线性
- 工作在一类放大器,非线性预失真技术,使线性范围变大
- 直接回退(不得已而为之),使得功放工作点往下至线性区
- 接收端:非线性均衡技术
-
预失真,预编码,预均衡
- 相同:
- 都在发送端实现
- 通常需要发送端反馈
- 不同:
-
蜂窝:概念、作用
-
同频覆盖
-
双工和多址的概念
-
第 3 代移动通信系统
- 核心技术
- 扩频+码分多址
-
LTE 系统关键技术(4 个核心技术)
-
HARQ 作用
- 物理层(短时延特性) 协议层区别
- HARQⅠ、HARQⅡ
- 4G、5G 中都用多线程 SW 协议部分递增冗余
-
仿真:
- 评价指标:有效,可靠,复杂度,时延,频率稳定度,定时精度
- 怎样 debug,如何做好通信系统仿真(结合自身)
对应课程:南京大学并发算法与理论
试图像追番一样学习
不过时间有限,就做个简短的笔记好了
0 绪论
并发存在交织性,例如以下程序虽能编译,但会断言错误:
#include <thread>
#include <assert.h>
int x = 0;
void foo() {
while (true) {
x = 1;
x = 0;
assert(x == 0);
}
}
int main() {
std::thread t(foo);
std::thread t2(foo);
t.join();
t2.join();
}
// g++ ./main.cpp -lpthread -o main.o
1 JMM
Java Memory Model (JMM)
1-1 SC 模型
Sequential Consistency (SC) Model,顺序存储模型
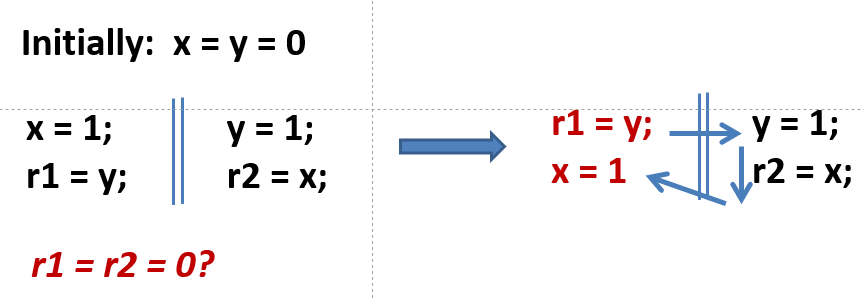
这种与顺序存储模型不符的 reordering 优化在 Java 或其它编译器中存在
1-2 DRF 程序
Data-Race-Freedom (DRF),无数据竞争:读写冲突/写写冲突
DRF 程序就不用担心受 reordering 优化影响。 因此编译器也可以大肆优化:
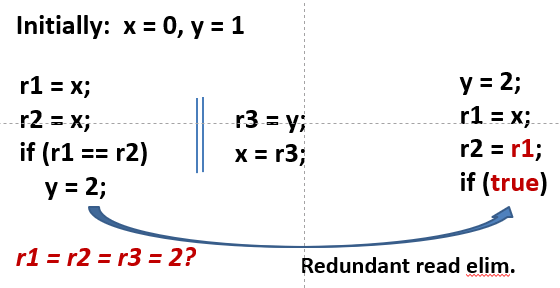
1-3 Happens-Before
操作A happens before 操作B,就是要求 操作A 对于 操作B 可见,且本质上应先于操作B 执行。譬如:
i = 1; // 操作A
j = i; // 操作B
则如果 A hb B,则 j=1;若没有声明 hb,就不能保证这个结果。
不过,即便声明 hb,也并不一定要顺序执行,只要保证结果上一致即可。
这课好像纯 Java 啊目前
对应课程:东南大学工程矩阵理论-周建华
要会证明的定理:绝对不会考察(笑),定理只要看得懂就行
- 子空间、交空间、和空间的维数定理
- 判断两个空间的和是否为直和 的等价条件
- 线性空间里的线性变换的维数定理
- 等距变换的充要条件
- 一个 Hermite 矩阵的最大特征值是 Rayleigh 商的最大值
- 矩阵的谱半径不会超过相容范数的范数值
要记的定义:
- 验证子空间:(第一章)
- 非空
- 加法、乘法封闭
- 线性映射、线性变换:保持加法、数乘
- 内积:酉空间,欧式空间(第二章)
- 等距变换:酉变换,正交变换
- 四个条件
- 特征值,特征向量(第三章)
- 若当形矩阵
- Hermite 矩阵,正规阵,酉矩阵(第四章)
- 正定:半正定,负定,半负定
- 向量范数:(第五章)
- 矩阵范数:
- 矩阵函数
- M-P 方程,计算满秩分解,性质(第六章)
先从题目形式分析,再考虑重新表示
n 个矩阵相加得到 1 个矩阵的,可以考虑分块 / 分列
行列式: 取矩阵某一行/列,对该列的每个元素求其代数余子式,并与该元素相乘,最后将所有乘积相加
代数余子式: 把元素 所在的第 行和第 列划去,求得到的行列式的值,得到余子式 ,, 即为代数余子式
求逆矩阵: 先求出各元素对应的代数余子式
- 代数余子式转置得到伴随矩阵
- 求出矩阵的行列式的值(即第一行各元素与其对应的代数余子式相乘 的和)
- 伴随矩阵除以行列式得到逆矩阵
逆矩阵的行列式 为 原矩阵行列式的倒数
上、下三角矩阵的行列式为其主对角线元素的积
Hermite 矩阵:
酉矩阵:
正规阵:
正定阵:
迹(trace):主对角线元素之和,也是特征值之和
0 第零章
0-1 行列式
行列式在初等变换后值不变,且可以混合行/列变换
注意乘法中可能存在的数字,往往能简化计算(可交换),例如
可知 有非零解
0-2 秩
矩阵的秩 等于:
- 其非零子式的最高阶数
- 或等于其行/列向量的的秩
- 或以 为基础解系的齐次线性方程组的解的秩
可逆矩阵满秩
可逆矩阵的特征值非零,行列式非零(这个是等价条件)
- 对于方阵 , 可逆
- 对于行满秩的非方阵
为幂等阵
有解等价于
第一章
维数定理: 假设,有
维数定理: 假设 ,则
极大无关组就是满秩分解里 的各列,而各列又代表对应线性映射的值域的一组基(习题1.16)
同一线性变换在不同的基偶下的矩阵是相似的 线性变换要满足 齐性,可加性
零矩阵有可能是核空间带来的,分块矩阵里的零矩阵可以考虑值域和核的直和
线性变换的值域的基下对应的矩阵为单位阵,核的基下对应的矩阵为零矩阵
的值域相同,则
子空间:
- 加法和数乘封闭
基:把一种矩阵用多个矩阵表示,每个矩阵仅含一个变量
的基,或 的基, 为 的某个矩阵:(见试卷2010b.2)
- 对 A 做行变换得到简化阶梯形矩阵
- 第 列乘以 ,每行得到一个等式
- 利用所有等式,列出一个列向量,即所有 都用其中一个 表示
- 若有自由的 ,则补一个单位列向量
直和:两个子空间交集为零向量
基下的矩阵:(见习题1.13)
- 若基为 方阵而非向量,则基下的矩阵为
不变子空间:设 ,若 ,有 ,则称 W 是 的不变子空间
定理:
第二章
最小值常常考虑正交补空间
等距变换:
- ,
- 实数时称作正交变换,虚数时称作酉变换
正定阵相似于对角阵
求 对 的正投影 : 垂直于 的基,且 能被这些基表示
第三章
最小多项式:把 J 代入到化零多项式观察得到,或者 J 中 Jordan 块对角线为 的最大阶数为最小多项式中 的最大次数
一般对于重数不超过3的特征值, 为以 为对角线元素的 Jordan 块的数量
用最小多项式求矩阵多项式:
- 用 替换矩阵多项式中的
- 将多项式表示为最小多项式的积+商,其中商的最高次为最小多项式最高次-1
- 将特征值代入其中,二重特征值则可再代入多项式的一阶导数中,以此类推
用最小多项式求 :
- 高于最小多项式最高次-1 的 的次方均可化为更低的次方项,故 的最高次项为最小多项式最高次-1
- 接下来做法同矩阵多项式
第四章
共轭合同可以理解为 H 阵的相似
特征值均为正实数:相似于正定阵
证明一个矩阵为正定阵,通常可以证明其共轭合同于一个显然的正定阵
第五章
范数非零时恒正,齐次,三角不等式
- ,谱范数, 代表取最大特征值
范数相容:
第0章 复习与引申
0-1 矩阵的代数运算
相似
矩阵相似 :可以通过初等行/列变换转换
- 约当型: 与原矩阵相似的简单矩阵
- 范数:用于刻划矩阵大小,→与的差
- 广义逆矩阵: 对方程 :
- 若 可逆,则
- 若 不可逆,则 ,其中为广义逆矩阵
矩阵乘法中的 非零零因子 : ,,但 ,则 为左零因子, 为右零因子
常见的类对角矩阵:
可交换
可交换 :
数量矩阵: ,其中 为实数, 为单位阵
- 若A与任意同阶矩阵可交换,则A为数量矩阵
矩阵的乘法交换律不成立,乘法消去律也不成立,但乘法分配律成立
当矩阵AB=BA时,二项式定理成立
分块矩阵
分块矩阵 :将A、B两矩阵分块:
在A的列的分法与B的行的分法相一致时,矩阵 也可以写成分块矩阵:
秩
秩 :矩阵内最多呈线性无关的列向量数
若 ,则
若 可由 线性表示,则
0-2 线性方程组
设方程组 ,则有
- 有解
- 若 ,则有唯一解
- 若 ,则通解中有 个自由未知量
基础解系
基础解系:若 满足:
- 是 的解
- 线性无关
- 的任一解都可被其线性表示 则其为 的基础解系
对于齐次线性方程组 ,有
- 有非零解 (系数矩阵的秩小于未知量个数)
- 若 ,则其基础解系中含 个解向量
- 若 ,则其任意 个线性无关的解向量是其基础解系
阶梯形矩阵
满足下述条件的矩阵称为阶梯形矩阵:
- 元素全为零的行均在矩阵的下方
- 非零首元所在列的下标随着行标的增大而严格增大
满足下述条件的阶梯形矩阵称为简化阶梯形矩阵:
- 各个非零行的非零首元均为 1
- 除了非零首元外,非零首元所在的列其余元素都为零
Gauss 消元法
- 用初等行变换将增广矩阵化为阶梯形矩阵
- 确定自由未知量:
- 找每行的非零首元
- 找对应未知量
- 通过回代法用自由未知量表示2.2中的未知量(此步可借助简化阶梯形矩阵)
共轭转置 :,即先复数上的共轭,再转置
矩阵的秩等于
- 其非零子式的最高阶数
- 或等于其行/列向量的的秩
- 或以 为基础解系的齐次线性方程组的解的秩
线性⽅程组恒有解 系数矩阵的秩 = 增广矩阵的秩
若阶梯矩阵有全零行,则有无穷多个解
0-3 向量
极大线性无关组
设向量组 的部分组 满足
-
线性无关(可用列方程表示)
-
中每个向量均可由 线性表示,则称 是 的一个极大无关组
-
若一向量组的极大无关组中含 个向量,则称这个向量组的秩为
-
若向量组的秩为 ,则该向量组中任意 个线性无关的向量均为其极大无关组
判断是否线性相关:
- 若有非零解,则线性相关
- 若仅有全零解,则线性无关
矩阵的秩
有关秩的不等式:1. 2. 3. 若 ,则 4. 5. 对于 ,
3 是 4 的特殊情况
初等阵:可以由单位阵经一次初等变换得到的矩阵
幂等矩阵:
可逆矩阵:又称满秩矩阵能通过初等变换得到单位阵(理由:,可知方程有唯一解,即系数矩阵相似于单位阵)
- 可知可逆矩阵的行、列向量线性无关(初等变换后满秩)
- 可逆矩阵行列式不为0,特征值全不为0
不可逆矩阵:若 为不可逆矩阵,则必有 ,使得
- 可知不可逆矩阵的行、列向量线性相关(初等变换后有全零行)
线性无关=可逆,线性相关=不可逆
满秩分解:对于 的矩阵 ,取 的矩阵 和 的矩阵 ,使得 ,其中
- 可取 为 的极大线性无关组, 则为各列用极大线性无关组表示时的对应系数
- 也就是将 化为简化阶梯形矩阵后, 为非零首元所在的 个列的 原 矩阵的列 组成的 矩阵
- 则为 非零首元所在的 个行的 的简化阶梯形矩阵的行 组成的 矩阵
1-1 线性空间
1-1-1 线性空间的定义
线性空间是由下述三个要素确定的代数系统:
- 一个数域 ,一个非空集合 ( 中的元素也称为向量);
- 两个运算:加法:;数乘:;
- 上述运算满足如下八个公理其实只需加法、数乘封闭
- 加法交换律:,有 ;
- 加法结合律:,有 ;
- 零元存在性:存在 ,使得,有;
- 负元存在性:,存在 ,使得 ;
- 幺等律:,;
- 数乘结合律:,都有 ;
- 分配律:,有;
- 分配律:,都有。
1-1-2 线性空间的例子
- 数域 上所有 维向量全体,按向量的加法和数乘,构成一个线性空间,记为
- 数域 上所有 矩阵全体,按矩阵的加法和数乘,构成一个线性空间.记为
- 数域 上所有一元多项式全体,按多项式的加法和数乘,构成一个线性空间.记为
- 数域 上所有次数小于n的一元多项式全体,按多项式的加法和数乘,构成一个线性空间,记为
1-1-3 线性空间的性质
设是数域上的线性空间,,则:
- V中的零向量是唯一的.通常记为:
- V中任一向量的负向量是唯一的.通常记为,
- 加法消去律:若,则;
- 向量方程的解:有唯一解,记为;
- ,特别地,;
- ,当且仅当或。
1-2 基和维数
1-2-1 线性相关性
设,若存在不全为零的数 使得,则称向量组线性相关。否则,称线性无关
- 相关:能表示
- 无关:不能表示
重要性质
- 若s≥2,则线性相关当且仅当存在向量 ,使得可由其余向量线性表示
- 若线性无关,但线性相关,则可由线性表示,而且,线性表示的方法是唯一的.
- 若可由线性表示,则线性相关
若可由线性表示,且线性无关,则t≤s
若与等价,且都线性无关,则
等价:两向量组可相互线性表示 线性空间中的向量仅代表元素,因此向量也可以是矩阵
1-2-2 基、维数和坐标
基
定义: 若 满足条件:
- 线性无关
- 任意的 均可由 线性表示
则称 是 V 的一组基
维数
- 若 的某一组基中含个向量,则的任一组基中都含个向量,称是的维数,记为
- 若,则中任意个向量线性相关
- 线性空间的基不一定存在,
- 如:只含一个零向量的空间称为零空间,规定零子空间的维数为
- 再如:规定
定理:若 ,则 V 中任意 个线性无关的向量均构成 的基
坐标
定义: 设 是V的一组基,,且 ,则称 是β在基下的坐标,或是β在基下的坐标(列向量)
性质:
- 线性空间的基是有序的
- 基相当于几何空间中的坐标系
定理: 假设, 在基下的坐标分别是及,则
- ;
- 线性相关线性相关.
的秩:
- 若 :线性无关
- 若 :线性相关
即其阶梯矩阵非零行的数量
1-2-3 基变换和坐标变换
形式记号
设,定义形式行向量。
比如,若 是β在基下的坐标, 则 可形式地记成 。
若 可由 线性表示, 于是,我们可以找到一个s×t矩阵A使得
性质: 若 , 则
过渡矩阵
定义: 设 及都是V的基,且 则称A是从基到基的过渡矩阵
过渡矩阵是右乘的!且顺序是反的!例如:若, 则知为从基到基的过渡矩阵 但在下应为
性质:
- 过渡矩阵一定是可逆的
- 若从基到基的过渡矩阵是A,则从基到基的过渡矩阵是.
- 若从基到基的过渡矩阵是A,从基到基的过渡矩阵是B,则从基到基的过渡矩阵是.
坐标变换公式
设 在基下的坐标是X,在基下的坐标是Y,而从基到基的过渡矩阵是,==则,或==
1-3 子空间
1-3-1 子空间的定义
设 V 是数域 F 上的线性空间, W 是 V 的非空子集。若 W 关于 V 的运算也构成 F 上的线性空间,则称 W 是 V 的子空间.记
W的运算与V中的运算应当相同
1-3-2 充分必要条件
设,则 是 的子空间 关于线性运算封闭
1-3-3 重要子空间
-
设 ,称 V 是齐次线性方程组 的解空间.(基础解系是 V 的一组基,维数是 。)
-
设 是 上的线性空间,,集合 称 W 是由 生成的子空间, 称 是W的生成元。
记 或
性质:
- 若 ,则
- 与 等价
- 的极大无关组是 的基,故
1-3-4 基扩充定理
有限维线性空间 V 中任意线性无关向量组均可扩充成 V 的基
:仅有第 i 行第 j 列为 1,其它元素为 0 的方阵
1-4 子空间的交与和
并集并不是子空间
1-4-1 交与和的定义
定义
分别称为子空间的交与和
定理 都是 V 的子空间.
1-4-2 维数定理
定理:
若
则
维数定理: 假设,有
1-4-3 直和
定义 设 ,若唯一的 ,使得 , 则称 是直和,记为
定理:设 ,则下述条件是等价的:
- 直和
- 的表示方式是唯一的
- ;
- 将的基合在一起就是的基
多个子空间的直和:
设 ,若 ,
唯一的,使得,
则称 是直和,记为 .
定理: 设,则下述条件是等价的:
- 直和
- 的表示方式是唯一的
- ;
- 将的基合在一起就是的基
1-5 线性映射
1-5-1 映射的概念
定义:
设 S 和 T 是两个集合, 是一个法则,使得对 中每个元素 ,
在 T 中必存在唯一的元素 y 与之对应,则称 是 S 到 T 的映射,
记为
如果,则称 y 为 x 的象,x 为 y 的原象
S在映射 下的全体象记为 ,称为 的值域
集合S到自身的映射 称为S上的变换
集合S到自身的映射 ,称为S上的恒等变换
定义: 设映射
- 若 .则称 是满射
- 若由 必能推得 ,则称 是单射
- 若 既是满射又是单射,则称 是双射
定理: 是双射 是可逆映射 (即,存在映射,使得,fg=I_T)
线性映射设 V,U 是数域 F 上的线性空间,若映射满足条件:
- 齐性
- 可加性
则称 是从 V 到 U 的线性映射, 从 V 到 U 的线性映射全体记为 V 到 V 自身的线性映射称为 V 上的线性变换
假设是线性映射.则:
- ;
- 若 则
- 若 线性相关,则 线性相关
- 若 ,则 的值域
- 是 V 的子空间,称为 的核空间,也记作
线性变换的运算
假设 ,定义 如下:
- 容易记错!不满足交换律
容易验证,以上运算的结果仍然都是线性映射
是线性变换
性质: 设 。则:
1-5-2 基下的矩阵
设,选定基偶: 若 则称 A 是 在选定基偶下的矩阵 特别如果 ,且, 则称 A 是线性变换 在所选基下的矩阵.
定理: 若在基偶 下的矩阵是 在 的坐标是 , 则 在基 下的坐标是 .
过渡矩阵: 到 基 的过渡矩阵是 ,也就是
定理:
设 在选定基偶: 的一组基 到
基 的过渡矩阵是 , 的一组基 到
基 的过渡矩阵是,
若 在基偶 与 下矩阵为A,在基偶 与 下矩阵为 ,
则
特别是,若 在基 下的矩阵是 , 则 在新的基 下的矩阵 是
可知 A 与 B 相似,也就是说同一线性变换在不同的基偶下是相似的
定理: 假设 在 V 的基 下的矩阵分别 是A,B,设 ,则在基 下,
- 的矩阵是
- 的矩阵是 ;
- 的矩阵是 ;
- 可逆 矩阵 可逆,并且, 的矩阵是
1-5-3 值域和核
假设 ,则
- 是满射。若 ,则
- 是单射
值域的计算
若 在基偶 , 下的矩阵是 A,即 由于 的极大无关组是 的基 特别地,
1-5-4 核子空间的计算
若 在基偶 , 下的矩阵是 A, 在 的坐标是 X,则 在基下的坐标是 。因此, 从而,若 是 的基础解系, 是以 为坐标的 中的向量,则 是 的基
维数定理: 假设 ,则
推论: 设 ,则 可逆 是单射 是满射
对无限维空间,推论不成立
1-5-5 不变子空间
设 ,若 ,有 ,则称 W 是 的不变子空间
2-1 内积空间的概念
内积就是点乘
2-1-1 内积空间的定义
假设 V 是数域 F上的线性空间,在 V 上定义了一个二元函数 ,若
- ;且等号成立当且仅当 则称 是 的内积。
- 定义了内积的线性空间称为内积空间
- 当 时,称 V 是欧基里德空间,简称欧氏空间
- 当 时,称 V 是酉空间
欧基里德空间和酉空间统称为内积空间
迹(trace):主对角线元素之和,也是特征值之和
标准内积:
- 在空间 上定义内积 ,则 是欧氏空间
- 在空间 上定义内积 ,则 是酉空间
2-1-2 内积空间的性质
- 对任意
度量矩阵
设 是 V 的基, 的坐标是 则 其中,,称 A 是 V 在基 下的度量矩阵
- 若 ,则度量矩阵是对称矩阵:;
- 若 ,则度量矩阵是Hermite矩阵:
度量矩阵须为正定阵
2-1-3 模与正交性
定义: 设 的模(长度)定义为 ,若,则称 α 是单位向量。
性质:
- ,且 ;
- 故若 ,则称 是单位向量
柯西不等式: ,当且仅当 线性相关时等号成立,即两者平行
可以从夹角公式 推出柯西不等式
- 线性相关:向量组不全两两正交。若只有两个向量,则两者平行
- 线性无关:向量组两两正交
三角不等式:
向量距离:
三角不等式的距离形式:
正交性:若向量 的内积为零,则称 是正交的,记
勾股定理:若 ,则
- 由两两正交的非零向量组成的向量组称为正交向量组
- 由两两正交的单位向量组成的向量组称为标准正交向量组
- 由正交向量组组成的基称为是正交基
- 由标准正交向量组组成的基称为是标准正交基
标准正交基下的内积
设 是 V 的标准正交基, 在 下的坐标是 X,Y 则
2-1-4 Schmidt 正交化方法
设 是线性无关的,
- 正交化:
- 单位化: 则 是与 等价的标准正交向量组
推导:
2-1-5 酉矩阵
定义: 若 n 阶复矩阵 A 满足 ,则称为酉矩阵
A 是酉矩阵的行/列向量组是 的标准正交基
定理 设 是 V 的标准正交基, 则 是标准正交基 是酉矩阵.
Schmidt正交化方法的应用
====
- 若 A,B 是同阶酉矩阵,==则 都是酉矩阵==
- 假设 A 是上(下)三角矩阵,若 A 是酉矩阵,则 A 是对角阵,且其主对角元的模均等于1.
如果 是 V 的基,则有标准正交基 使 其中,T是上三角矩阵,且其主对角元均大于零
2-1-6 基扩充
基扩充定理
假设 W 是 V 的子空间, 是 W 的标准正交基,则 存在 使 得 是 V 的标准正交基。
2-2 正交补空间
正交性: 设 ,若 ,称 若 ,对,称
定理 设 ,则
2-2-1 正交补空间
定义: 设 ,记 易证这是 V 的子空间,称是 W 在 V 中的正交补空间
定理: 设 ,则 而且,若 ,且 ,则 .
推论: 若 ,则
2-2-2 和
定理:
2-2-3 正投影
已知 ,若 满足 则称 为 在 W 中的正投影
定理: 假设 ,则
- 若 在 W 中的正投影存在,则正投影必定是唯一的;
- 是 在 W 中的正投影当且仅当
定理: 如果 是有限维的,则任意 在 W 中的正投影必定存在
2-2-4 应用
最小二乘解: 设 ,线性方程组 的最佳近似解 为 的解
2-3 等距变换
定义: 设 V 是内积空间,,若 称 是等距变换
- 若 ,称 是正交变换
- 若 ,称 是酉变换
充要条件 设 V 是内积空间,,下述条件等价:
- 保持长度不变
- 保持内积不变
- 将标准正交基变为标准正交基
- 在标准正交基下的矩阵是酉矩阵
镜像变换
假设 V 是一个欧氏空间, 是一个单位向量,映射 则是 V 上的等距变换(正交变换)
镜像变换在任意一组基下的矩阵都相似于
3-1 特征值与特征向量
3-1-1 定义和计算
矩阵的特征值与特征向量
定义: 假设 A 是 n 阶方阵, 是数,若存在 n 维列向量 ,使得 ,且 则称 是 A 的特征值, 是 A 的属于特征值 的特征向量。
定理: 假设 A 是 n 阶方阵,则 A 相似于对角阵的充分必要条件是 A 有 n 个线性无关的特征向量。
线性变换的特征值与特征向量
定义: 设 是线性空间上的线性变换,假设 , 若存在使得 ,且 则称 是线性变换 的特征值, 是相应于 的特征向量。
线性变换的可对角化问题: 设 V 是 n 维线性空间, 是线性空间 V 上的线性变换, 则存在 V 的基使得 的矩阵是对角阵当且仅当 有个线性无关的特征向量。
线性变换的特征值、特征向量的计算
设 在 V 的基 下的矩阵是 A 若 在基 下的坐标是 , 则 在基 下的坐标是 ,故 即: 是 的属于特征值 的特征向量当且仅当 是 A 的属于特征值 的特征向量。
行列式: 取行列式某一行/列,对该列的每个元素求其代数余子式,并与该元素相乘,最后将所有乘积相加
代数余子式: 把元素 所在的第 行和第 列划去,得到余子式 ,, 即为代数余子式
的行列式 的行列式的平方
定理: 若 是相似的,则
注意:
- 定理的逆命题不成立
- 可定义线性变换的特征多项式
相似矩阵特征值相同。
3-1-2 特征多项式
特征多项式的计算
定义: 假设矩阵 ,,则 A 的第 行, 第 列交叉处的元素构成的 k 阶子式称为 A 的 k 阶主子式
Cauchy-Binet公式
定理: 设 ,则 其中, 为 A 的所有 j 阶主子式之和,特别地
矩阵的迹
定义: 设 ,称 为 A 的迹,记为
- 若 的特征值为 ,则
- 若 相似,则
== 的阶数大于 m 的子行列式应全为零,主子式应全为零==
不一定等于 ,但 一定等于
为 的特征值,则 为 的特征值
等于特征值的和
化零多项式
引理: 设 是多项式,若 ,则 A 的特征值均是 的根,称 为 A 的化零多项式
3-1-3 Hamilton-Cayley 定理
Schur 引理: 对 ,存在酉矩阵 U 使得 是上三角矩阵。
定理: 设 ,则 。
定理: 设 是 的特征多项式,则 。
3-1-4 最小多项式
矩阵的最小多项式
根据 Hamilton-Cayley 定理,一定存在最小多项式
定义: 矩阵 A 的次数最低的、最高次项系数为一的化零多项式称为 A 的最小多项式
性质:
- 若 分别是矩阵 A 的最小多项式、化零多项式,则
- 任意矩阵的最小多项式是唯一的,
- 如果矩阵 相似,则 有相同的最小多项式
线性变换的最小多项式
定义: 设线性变换 在 V 的一组基下的矩阵为 的最小多项式称为 的最小多项式
等价定义: 线性变换 的次数最低的、最高次项系数为一的化零多项式称为 的最小多项式
设 ,,有
定理: 设 分别是矩阵 A 的最小多项式和特征多项式, 则 ,并且,对
3-2 可对角化问题
- 矩阵 A 相似于对角阵 有 n 个线性无关的特征向量
- 矩阵的属于不同特征值的特征向量线性无关
- 若 是矩阵 A 的互不相同的特征值, 是 A 相应于特征值 的线性无关的特征向量,则 线性无关
线性变换的可对角化问题
定理: 假设 V 是 n 维线性空间,。则
- 可对角化当且仅当 有 n 个线性无关的特征向量
- 的属于不同特征值的特征向量线性无关
- 若 是矩阵 A 的互不相同的特征值, 是 相应于特征值 的线性无关的特征向量,则 线性无关
3-2-1 特征子空间
定义: 设 , 是 的特征值,称 为 的相应于特征值 的特征子空间
相应于特征值 , 刚好有 个线性无关的特征向量
定理: 设 为 的相异特征值,则 是直和。
定理: 假设 的特征多项式为 则存在 V 的基使得 的矩阵是对角阵的充分必要条件是
3-2-2 几何重数
定理: 设 的特征多项式是 ,则 。 其中 称为几何重数, 称为代数重数
定理: 设 的特征多项式是 ,则下述条件是等价的:
- 是可对角化的
3-2-3 最小多项式与可对角化
引理: 若 n 阶矩阵 满足 ,则
定理: 矩阵 A 相似于对角阵当且仅当 A 的最小多项式无重根
对角阵的行列式等于其主对角线元素之积
3-3 若当标准形
3-3-1 Jordan 形矩阵
定义:
- 形如 的矩阵称为 Jordan 块
- 形如 (其中 均为 Jordan 块)的矩阵称为 Jordan 形矩阵
若当块一定可以被开方
3-3-2 Jordan 标准形
对角阵是一种若当形矩阵
定义: 若 是若当形矩阵,且矩阵 与 相似,则称 是 的若当标准形
设 ,则 的各列 为 对应列的特征值对应的特征向量
3-3-3 唯一性
若 是矩阵 的 Jordan 标准形, 其中, 是 的一个排列,则 K 也是 A 的 Jordan 标准形。
下面的定理表明:在承认存在性的前提下,除了相差 Jordan 块的次序外,每个矩阵的 Jordan 标准形是唯一的
定理: (假设矩阵的Jordan标准形是存在的)设 是 n 阶方阵 A 的特征值, 则对任意一正整数 k,A 的 Jordan 标准形中主对角元为 且阶数为 k 的 Jordan 块的块数等于 其中,
,并约定
中阶数为 的 Jordan 阵块数:
可逆矩阵的 k 次方后的秩不变
仅有 Jordan 阵顺序不同的 Jordan 标准形算作同一个
一般对于重数不超过3的特征值, 为以 为对角线元素的 Jordan 块的数量
Jordan标准形与最小多项式
定理: 若 则矩阵 的最小多项式间有关系:
定理: 假设矩阵 A 的最小多项式是 , 则 即是 A 的 Jordan 标准形中以 为主对角元的 Jordan 块的最高阶数。 特别地,A 相似于对角阵 的最小多项式无重根
相似矩阵有相同的迹,相同的秩
3-4 特征值的分布
3-4-1 谱半径和盖尔圆
定义: 设 ,称 A 的特征值的集合为 A 的谱, 称 A 的特征值的模的最大值为 A 的谱半径,记为 。记 称之为 A 的第 i 个盖尔圆; 称 为 A 的盖尔圆系
3-4-2 第一圆盘定理
定理: 矩阵 A 的特征值必定在 A 的盖尔圆系中
注意:并不是每个盖尔圆上都有特征值,但是在盖尔圆之外没有特征值.
3-4-3 第二圆盘定理
定义: 设 ,在 A 的 n 个盖尔圆中,有 k 个圆构成一连通区域, 但与其余 个圆不相交,则称这个连通区域为 区
定理: A 的盖尔圆的 区中有且仅有 A 的 k 个特征值
推论: 如果 A 的 n 个盖尔圆互不相交,则 A 有 n 个互不相等的特征值
3-4-4 谱半径的估计
设 则
4-1 H 阵和正规阵
4-1-1 Hermite二次型与H阵
定义: 设 ,若有 ,则称矩阵为 Hermite 矩阵,简称为H阵,这时的 称为是 Hermite 二次型。
H 阵主对角线一定都是实数
4-1-2 H 阵的性质
实对称矩阵的性质:
- 实对称矩阵的特征值都是实数
- 实对称矩阵的属于不同特征值的特征向量相互正交
- 对任意实对称矩阵 ,存在正交矩阵 ,使得 是对角阵
H阵的性质
- H 阵的特征值均是实数
- H 阵的属于不同特征值的特征向量相互正交
- 若 A 是 H 阵,则必存在酉矩阵 U,使得 是对角阵
可知
4-1-3 正规阵
定义: 设 ,若 ,则称 A 是正规阵
H阵,酉矩阵,反H阵均是正规阵
定理: 若 A 既是上三角的,又是正规的,则 A 必是对角阵
定理: 是正规阵 酉相似于对角阵
定理: 是正规阵 有 n 个两两正交的单位特征向量
幂等阵的特征值非 0 即 1
4-2 标准形
4-2-1 共轭合同关系
可逆线性变换
若 A,B 都是 H 阵,且对 ,则
设 是可逆矩阵, 若在 下,,则
定义: 设 A,B 是 H 阵,若有可逆阵 C,使得 ,则称 A 与 B 是共轭合同的
共轭合同关系满足:反身性,对称性,传递性
4-2-2 Hermite二次型的标准形
标准形
定义: 假设 Hermite 二次型 在可逆线性变换下 变成只含“平方”项的形式 则称 是 的标准型
标准形的计算:
- 配方法(初等变换法)
- 酉变换法
4-2-3 酉变换下的标准形
假设 Hermite 二次型 ,A 是相应的 Hermite 矩阵,酉矩阵 U 满足 令 ,则
4-3 惯性定理
4-3-1 Hermite二次型的惯性定理
唯一性
定理: 若 在可逆线性变换 下变成标准形 在可逆线性变换 下变成标准形: 其中, 均大于零。则
定义: Hermite 二次型标准形中的正项个数称为其正惯性指数,负项个数称为其负惯性指数
两者之和为秩
4-3-2 关于 H 阵的惯性定理规范形
贯性定理的矩阵形式
若 H 阵 A 与 共轭合同,则 与 中正、负项个数相同
定义: 与 H 阵 A 共轭合同的对角阵中的正项个数称为 A 的正惯性指数,负项个数称为 A 的负惯性指数
4-3-3 规范形
如果 Hermite 矩阵 A 的正、负惯性指数分别是 , 则 A 必定与矩阵 共轭合同。称此矩阵为A的规范形
定理: 矩阵 A,B 共合同 有相同的正、负惯性指数 相同的秩和正惯性指数
4-4 有定性
4-4-1 正定性
定义: 设 是 阵,,若对 , 则称 是正定的, 是正定的 阵
如何建立判别方法:
- 设 则D是正定的
- 若 H 阵 A,B 共轭合同,则 A 正定 正定
- 若 H 阵 A 与 共轭合同,则 A 正定
正定的充要条件
定理: 设 A 是 阵,则下述条件等价:
- A 是正定的
- A 的特征值均大于零
- A 与 I 共轭合同
- 存在可逆阵 P 使得
- A 的各顺序主子式均大于零
各主对角线元素即 A 的各一阶主子式,因此主对角线元素为正
正定阵隐含为 Hermite 阵
正定阵可逆,其逆矩阵为
4-4-2 其它有定性
定义: 设 A 是 H 阵,
- 若对 ,则称 是负定的, 是负定的 H 阵
- 若对 ,则称 是半正定的, 是半正定的 H 阵
- 若对 ,则称 是半负定的, 是半负定的 H 阵
负定 正定
负定 正定 的偶数阶顺序主子式 > 0 的奇数阶顺序主子式 < 0
正定矩阵与半正定矩阵的和一定是正定矩阵
如何建立判别方法:
- 设 则D是半正定的
- 若 H 阵 A,B 共轭合同,则 A 半正定 半正定
- 若 H 阵 A 与 共轭合同,则 A 半正定
半正定的充要条件
定理: 设 A 是 阵,则下述条件等价:
- A是半正定的,即
- A的特征值均大于或等于零
- A 与 共轭合同;
- 存在矩阵 P 使得
- A的各主子式均大于或等于零
4-5 Rayleigh商
4-5-1 Rayleigh商
设 A 是 n 阶 H 阵,则 ,于是,可以定义一复变量的实值函数 称此函数为 A 的 Rayleigh 商
4-5-2 第一定理
假设 H 阵 ,A 的特征值 ,则
酉矩阵为正规阵
5-1 向量范数
5-1-1 定义
设 是数域 上线性空间, 是定义在 上的实值函数。如果 满足:
- 对任意 (正定性,恒正性)
- 对任意 (齐次性)
- 对任意 (三角不等式) 则称 是 上的范数。 定义了范数的线性空间称为赋范线性空间
5-1-2 长度与范数
设 是内积空间,则 上内积下的长度 是 上的一个范数
因此,从现在起,在不致于引起混淆的情况下,任意线性空间上的范数就记为
5-1-3 中的范数
对任意
- 向量 1-范数:
- 向量 2-范数:
- 向量 范数:
中更多的范数对任意 ,
- 时,有向量 p-范数:
- 如果 是已知的范数,A 是一可逆矩阵向量,则 也是 上的一种范数
5-1-4 V上的范数
设 是数域 上 维线性空间, 是V的一组 基, 是 上已知的范数,据此可以定义 上的范数: 若 在基 下的坐标是 ,规定
5-1-5 序列的收敛性
向量序列的收敛性
设 是 V 上的范数, 是 V 中的一个向量序列,。如果 则称向量序列 在范数 下收敛到 ,记为
范数的可比较性
假设 和 都是线性空间 上的范数。若存在大于零的数 , 使得对任意 ,不等式 成立, 则称 上的范数 和 是可比较的
定理: 有限维线性空间 V 上任意两个范数都是可比较的
5-2 矩阵范数
5-2-1 矩阵 p 范数
矩阵p-范数: 设矩阵 ,则有下列矩阵范数: 又记为 ,称为 Frobenius 范数,简称 F 范数
性质: F 范数是酉不变的:若 U,V 是酉矩阵,则
5-2-2 相容性
定义: 设 中定义了范数 ,,, 若对 则称范数 ,, 是相容的
定理: , 是相容的, 是不相容的
相容矩阵范数的定义域可以覆盖所有尺寸的矩阵
5-2-3 算子范数
设 , 分别是 上的范数,定义 上的实值函数 : 称是由 是由 , 诱导的算子范数
定理: 算子范数一定是相容的矩阵范数
5-2-4三个重要的算子范数
,, 诱导的 A 的算子范数分别被称为 A 的算子 1-范数,算子 2-范数,算子 范数,分别记为,,
定理: 设 ,则
- ,列模和范数
- ,谱范数, 代表取最大特征值
- ,行模和范数
5-3 收敛定理
5-3-1 矩阵序列的收敛性
定义: 设矩阵序列 , 如果 ,且 , 则称
可以证明:若 是一矩阵范数,则
5-3-2 幂序列
对给定的方阵 A ,考虑方阵序列
定理: 若有相容矩阵范数 ,使得 ,则
定理:
5-3-3 谱半径
定理: 若 是相容矩阵范数,则
定理: 对任意矩阵 ,若 ,则一定存在 上相容矩阵 范数 ,使得
5-3-4 矩阵幂级数
设 A 是方阵,对于幂级数 若矩阵序列 收敛于矩阵 M,则称矩阵幂级数 收敛于 M
定理: 若幂级数 的收敛半径为 ,则
- 当 时,矩阵幂级数 收敛
- 当 时,矩阵幂级数 发散
5-4 矩阵函数
5-4-1 定义
设函数 可以展开成幂级数 设 ,且 ,定义
几个重要的函数
5-4-2 Jordan 形矩阵
Jordan 形矩阵的函数
假设 其中
令 ,得
Jordan 块的函数
设 若当块 ,则
利用Jordan 标准形计算
定理 设矩阵 A 的 Jordan 标准形是 则
定理 己知 矩阵 A 的特征值为 ,则 的特征 值为
5-4-3 待定系数法
设矩阵 A 的 Jordan 标准形是 则 其中,
定理: 若 A 的最小多项式为 ,则 对每个特征值 ,
若最小多项式最高次为 ,则任何 都能化为次数不超过 的多项式, 因此可以设 ,或
性质
定理: 设 是 零矩阵,则
- 若 ,则
6-1 Moore-Penrose 方程
定义:设 ,若 满足下述四个条件,则称 是 的广义逆矩阵:
这四个方程也称为 M-P 方程
- 若 为可逆阵,则 为 的广义逆
定理:设 ,则 的广义逆矩阵是存在的,且是唯一的。 的广义逆记为
由广义逆存在性的证明可知,如果矩阵 的满秩分解为 ,则
6-2 广义逆矩阵的性质
6-2-1 分块矩阵的广义逆
- , 其中,
6-2-2 运算性质
注意: 与 一般不相等!除非
定理:设 , 则:
- 若 为实数, 则
- 若 是酉矩阵, 则
若 为 Hermite 矩阵,则 也为 Hermite 矩阵
若 为正规阵,则
6-2-3 广义逆的值域与核
定理
助记:
- 在涉及到值域和核空间的时候, 的性质类似
- 只要记助记,定理就会证明了
6-3 广义逆矩阵的应用:最小二乘解
当线性方程组 无解时, 如何求最好的近似解, 即求 使 得 最小?
定义: 设 , 若 则称 是线性方程组 的最小二乘解, 长度最小的最小二乘解称为极小最小二乘解
定理: 是 的最小二乘解 是 的解
定理: 的最小二乘解的通解 为: , 其中, 是唯一的极小最小二乘解
1 绪论
VLSI 的设计思想
VLSI 设计思想:
- 分层分级
- 每层、级间均有严格的接口定义
VLSI 的主要设计方法
- 自底向上:根据现有的简单功能块或积木块单元,逐级向上组合,直至实现 VLSI 的总体功能。每一级的功能及尺寸以及与上下级接口均有严格定义。
- 自顶向下:层次性设计。将要设计的 VLSI 系统逐级分解成较简单的功能,直至达到可进行高效设计的、足够简单的功能块。同样,每一级将要完成的功能以及上一级和下一级的接口均有严格的规定;
- 系统级 算法
- 寄存器级 有限状态机
- 门级 布尔方程
- 网表 连接关系
- 版图 器件布局
CAD 软件内容
- 逻辑设计阶段:逻辑综合、逻辑模拟、逻辑图的自动输入
- 电路设计阶段:电路分析、时域分析
- 版图设计阶段:逻辑划分、自动布局布线
- 工艺设计阶段:工艺模拟、器件分析
EDIF、CIF 等格式
- EDIF 是电路级规范,在电路图绘制,电路行为及结构文本描述、逻辑描述、PCB 设计、ASIC版图设计和其它分析综合工具间建立起一个公共标准
- CIF 是版图级规范,采用层次式结构的图形描述,便于设计师进行阅读、修改、组合和跟踪;同时,CIF 文件描述了一个完整芯片的设计
两者的关键特征是实现了共享和继承,是实现并行设计和设计升级的框架协议。
VLSI 设计流程及各设计阶段的内容
- 逻辑设计:
- 逻辑处理(S-EDIT):将组合逻辑化归为 与非 和 或非,用 宏结构 连接所要实现的数字系统, 最后将高层次的系统描述转化为硬件
- 逻辑模拟(T-SPICE):验证逻辑设计的正确性,并进行故障模拟
- 电路分析
- 主要目的是确定电路性能的电路结构和元件参数,同时考虑环境影响,来辅助完善设计
- 版图设计(L-EDIT)
- 根据前期设计确定 掩膜版图
- 工艺模拟
- 对制造中的各流程的工艺参数进行模拟,针对不同情况进行优化
可靠性和可测性设计
可测性设计的目标是实现设计的可控性和可观测性。
可控性是指用一个有限位长的输入码可以使所设计的芯片置于任何一种可能的状态。
可观测性是指所设计芯片的任何一种可能状态均可通过观测一个测试码的输出结果来得到,即在外部可测量芯片内部的状态。
可测性 DFT(design for testability)
- 直流特性测试:检验芯片好坏和可靠性。包括输入特性、输出特性、转移特性和功能项目。
- 交流特性测试:又称动态特性测试,测试脉冲的传输特性。
- 逻辑功能测试:通过设计生成测试图形、测试码、测试矢量,得到实际测试结果
可靠性 DFR(design for reliability)
定义:IC 在规定的条件和时间内完成规定任务的概率
目的:提高和保证电路正常工作的概率
包括:
- 元件和数值留有冗余度
- Memory 电路的坏块处理
- 增加 ESD 保护电路
- 合理布局的热设计
- 合理布线避免串扰和电迁移
2 专用集成电路 CAD 设计基础
全定制、半定制电路的区别
- 全定制电路的全套集成电路研制过程都是为用户定制的,其设计方法是全套掩膜版,有标准单元法,功能块法,优化阵列法等。
- 半定制电路的大部分设计和制备过程并非定制,而是已事先完成大部分,只需根据用户要求进行最终的制备烧结,有固定门阵列、可编程逻辑器件和现场可编程门阵列等。
ASIC 的主要结构
- 全定制 ASIC
- 行式结构
- 积木块结构
- 规则阵列结构
- 半定制 ASIC
- 固定门阵列
- 可编程逻辑器件
- 现场可编程门阵列
用固定门阵列实现
用 E/D NMOS PLA 实现 和
先化成最小项
3 CAD 电路分析基础
对图示电路做综合分析

1 直流工作点分析
先用节点电压法(即对每个节点列电流等式),再以电压的系数合并同类项
2 瞬态分析
瞬态就是电感电容伴随模型
- 电容的伴随模型:
- h 为时间步长
- 电感的伴随模型:(电流不能突变
- 各类元件都可以用诺顿等效模型:电导和电流源并联
交流
交流就是电流为 ,电容阻抗 ,电感阻抗
本课中计算时都用电导表示,最后再展开
4 CAD 逻辑模拟基础
对图示电路进行延迟分析,并按要求画出波形图。分析延迟:
- 传输延迟 :信号通过元件和导线传播引起的延时
- 上升、下降延迟 ,:器件输出从0到1的时延 / 从1到0。两者宽度不等时会改变脉冲宽度
- 模糊延迟 :最大延迟 和最小延迟 之间的信号值不是精确可测的
- 惯性延迟 :为使器件转换状态,对于输入的一个变化所必须维持的最小持续时间称为元件的惯性延迟。若输入脉冲宽度不到 则会被门过滤;若大于等于 ,则器件表现出不小于 的传输延迟
惯性延迟优先级最高(不然就没法解释答案了!)
逻辑模拟
三值模拟
用0,1,μ表示一个信号状态的逻辑模拟
故障
s-a-0:stack at 0,卡在了 0。
路径敏化法
路径敏化法步骤:
- 反映故障:确定输入,在故障部位产生需要的值(s-a-1故障时为0,s-a-0故障时为1)。
- 传播故障:选择一条从故障部位到达输出的路径,并且确定这条路经的另一些信号值,以便将故障传播到输出。
- 确定输入:使得产生 2 中规定的信号值。
D 算法
- D表示正常电路值为1而故障电路值为0的信号;
- 表示正常电路值为0而故障电路值为1的信号。
- D立方代数运算与布尔代数相同,不过此时门的输入为4值(0,1,D ,)。
有:,,, ,,
传播立方:无关故障,要考虑各路出错的可能(不过似乎只考虑 D,不考虑 D反
D 驱动操作:先选取故障原始 D 立方,然后先与传播立方相交,再与原始立方相交
5 CAD 版图设计基础
布线
垂直约束图
- 列出约束关系
- 从没有下边的端子开始,绘制垂直约束图(VCG)
水平带图
自左向右扫描,当某列上有线网结束时,做个记号。 如在后面的第j列上有新的线网开始时,则新的重迭区从第j列开始,而前一个重迭区在j-1列结束。 也有一些特殊情况,若同一列既有线网结束又有线网开始,则可以划分为一个独立的区; 若此时前面的分区没有划分,则合并为一个分区。
自动布图包含哪些内容,分别涉及哪些常用的算法?
- 自动布图包含:逻辑划分,电路排列,连线。
- 涉及的算法:结群,布图规划和布局,总体布线,总体压缩,无网格的通道布线和通孔,线长优化。
如何处理总体布线和通道在线的关系,李氏算法主要解决什么问题
- 总体布线是划分通道,是线网在各通道的分配
- 通道布线是在通道中排列线网,进行线网的走线
李氏算法是最小路径算法的一个应用,用于将线网分配到各 通道。
集成电路CAD的主要内容:
- 电路分析
- 逻辑模拟
- 版图设计
- 工艺模拟
EDA:电子设计自动化(Electronic Design Automation)
VLSI:Very Large Scale Integration,超大规模集成电路
VLSI 设计思想:
- 分层分级
- 每层、级间均有严格的接口定义
VLSI 的主要设计方法
- 自底向上:根据现有的简单功能块或积木块单元,逐级向上组合,直至实现 VLSI 的总体功能。同样,每一级的功能及尺寸以及与上下级接口均有严格定义。
- 自顶向下:层次性设计。将要设计的 VLSI 系统逐级分解成较简单的功能,直至达到可进行高效设计的、足够简单的功能块,每一级将要完成的功能以及上一级和下一级的接口均有严格的规定;
- 系统级 算法
- 寄存器级 有限状态机
- 门级 布尔方程
- 网表 连接关系
- 版图 器件布局
VLSI 由 LSI 组成,LSI 由 MSL 组成,MSL 由 LSL 组成。
复杂电路总可以分解为较简单的电路。
1-2 IC 设计中的方法
1-2-1 Framework
Framework 是一种规范,由国际 CAD 框架协会制定:
- EDIF 网表(电子设计自动化中介格式)
- CIF 网表(加州理工中介格式)
关键特征:实现了共享和继承,是实现并行设计和设计升级的框架协议。
2 并行工程
一种系统化、集成化、并行的产品及相关过程的开发模式
3 逻辑综合优化
逻辑综合功能将高层次的系统行为设计自动翻译成几级逻辑电路描述,使设计与工艺相对独立。
优化则是对于上述综合生成的网表,根据布尔方程式功能等效的原则用更小更快的综合结果替代一些复杂的单元,与指定的库映射生成新的网表。
1-3 VLSI 设计流程
1-3-1 逻辑设计阶段
- 逻辑处理
- 将所要实现的数字系统中的组合逻辑部分最小化为 与非 和 或非;
- 将所要实现的数字系统用一些宏结构经过连接来实现;
- 将高层次的系统描述逐步转换成与实现技术相关的硬件。
- 逻辑模拟
- 验证逻辑设计的正确性;
- 进行故障模拟,产生故障诊断的测试码。
- 分为门级、功能级、寄存器级三类
1-3-2 电路分析
定义:根据电路给定的元件参数进行性能模拟和分析,并给出模拟结果,为设计者提供修改建议
目的:确定电路性能的电路结构和元件参数,考虑环境、工艺偏差导致的性能变化。
常用软件:SPICE :
- 主要功能:
- 直流分析
- 交流小信号分析
- 瞬态分析
- 不同温度下分析
1-3-3 版图设计
定义:根据逻辑和电路功能要求以及工艺制造的约束条件来设计掩膜版图
常用软件:LEDIT, VIRTUOSO
1-3-4 工艺模拟
定义:对制造中的各流程工艺参数进行模拟,根据具体情况对不合格的设计进行修正
1-4 SOC 的设计方法
主要使用自顶向下设计方法,分为
- 高层综合:行为级设计和结构级设计
- 逻辑综合:逻辑设计和电路设计
- 物理综合:版图级设计
也可分为
- 前端设计:系统、功能、结构和电路设计
- 后端设计:版图设计
1-5 可测性和可靠性
可测性设计的目标是实现设计的可控性和可观测性。
可控性是指用一个有限位长的输入码可以使所设计的芯片置于任何一种可能的状态。
可观测性是指所设计芯片的任何一种可能状态均可通过观测一个测试码的输出结果来得到,即在外部可测量芯片内部的状态。
1-5-1 可测性 DFT(design for testability)
- 直流特性测试:检验芯片好坏和可靠性。包括输入特性、输出特性、转移特性和功能项目。
- 交流特性测试:又称动态特性测试,测试脉冲的传输特性。
- 逻辑功能测试:通过设计生成测试图形、测试码、测试矢量,得到实际测试结果
1-5-2 可靠性 DFR(design for reliability)
定义:IC 在规定的条件和时间内完成规定任务的概率
目的:提高和保证电路正常工作的概率
包括:
- 元件和数值留有冗余度
- Memory 电路的坏块处理
- 增加 ESD 保护电路
- 合理布局的热设计
- 合理布线避免串扰和电迁移
2-1 IC 分类
- 按工艺分类:双极(Bipolar) 、金属氧化物半导体CMOS):
- 按功能分类:模拟(Analog) 、数字(Digital) 、数/模混合(Mix);
- 按用途分类:通用(GSIC) 、专用(ASIC):
- 按设计方式分类: 半定制(Semi-Custom) 、全定制(Full-Custom) 。
- 按结构形式分类:单片集成电路(Chip) 、膜集成电路(Hybird Circuits);
- 按规模分类:小规模(SSI) 、中规模(MSI) 、大规模(LSI) 、超大规模(VLSI), ULSI 、GLSI 均认为是VLSI:
- 按制造方法分类:掩膜(MASK) 、电可编程(e-Programmable) 。
2-1-1 工艺分类
- 常规工艺电路:
- 双极(BJT): 多子器件,电流大,驱动大;
- MOS: 少子器件,面积小,速度快。
- 特殊工艺电路:
- BiMOS: 速度和功率的平衡;
- DMOS: 双扩散MOS, 高压大功率;
- BCD: 现在流行的工艺,综合了双极、CMOS 、DMOS 工艺特点。
PN 结
PN结的形成:参见 1-2 PN结
扩散运动(正偏)电流较大,漂移运动(反偏)电流较小,是以为半导体
两种载流子:电子 和 空穴
BJT
饱和区、放大区、截止区
常用公式:
- 放大模式:发射结加正向电压,集电结加反向电压,
- 饱和模式:均正偏,(掺杂浓度不同)
- 截止模式:均反偏
- 集电结正偏:集电极高于基极
- 发射结正偏:基极高于发射极
在晶圆上制作(一般是 P 型衬底)
- P 型衬底(P-sub)
- N+ 埋层(buried layer)
- N 型外延
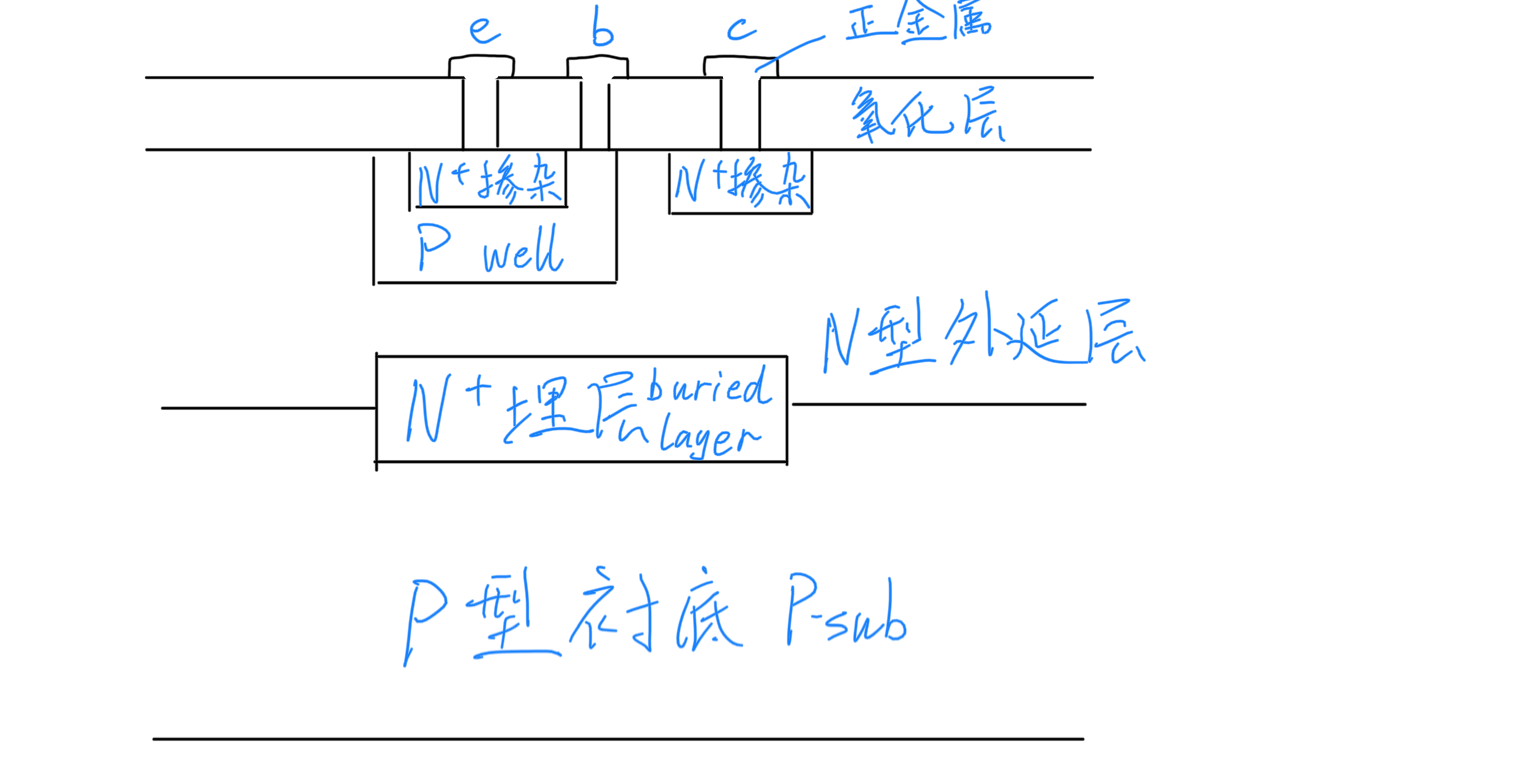
MOS
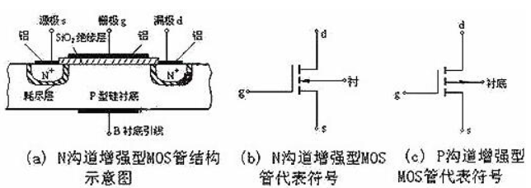
| N沟道 | P沟道 | |
|---|---|---|
| 非饱和区 | ||
| 饱和区 |
非饱和区:
- 很小时:
- 计及沟道长度调制效应时:(源漏电压差导致漏极电流变化)
饱和区:
BiMOS 代表器件:IGBT
IGBT(Insulated Gate Bipolar Transistor)是一个非通即断的开关,相当于一个由 MOS 驱动的厚基区 PNP 型晶体管。
分为:
- N 沟道 IGBT,N-IGBT,NMOS 驱动
- P 沟道 IGBT,P-IGBT,PMOS 驱动
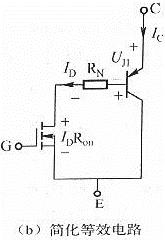
导通和截断由栅极 G 和发射极 E 间电压决定,当大于开启电压时,NMOS 内形成沟道并为 PNP 双极型晶体管提供基极电流,驱动 IGBT 导通。
特性对比
- 双极(BJT):多子器件,电流大,驱动大;
- MOS:少子器件,面积小,速度快;
- BiMOS:速度和功率的平衡;
2-1-2 模拟集成电路设计特点
- 模拟IC的应用环境对工艺造成的电气参数的离散性要求很高,常采用负反馈技术来保证电气性能指标的一致性和稳定性;
- 在基本放大电路中多采用漂移小、对称性好的差分放大器和有源负载放大器;
- 电路设计和版图设计配合实施匹配性设计;
- 偏置电路不用电阻而用温度补偿效果较好的恒压源、恒流源;
- 设计中多用有源器件而少用电阻,或者用有源器件代替无源器件:
- 大电阻很占面积,不如电流镜
- 电阻误差有时高达20%
- 采用比例电阻,不用绝对值设计,二极管用三极管实现
- 比例电阻:
2-1-3 通用和专用 IC
专用集成电路 ASIC 相对通用而言,但两者没有明显界限
ASIC 可分为:ASCP 和 ASSP
- ASCP:Application Specification Customed Product,面向专用的定制产品
- ASSP:Application Specification Standard Product,面向专用的通用标准产品
2-1-4 专用集成电路的设计方式
分为全定制、半定制电路
有人认为应分为全定制、半定制、可编程三类,这种分法实际上是突出了可编程类器件。
全定制电路
针对某一用户设计的集成电路,包括从电路图输入开始,完成逻辑或电路验证、版图生成、掩膜(MASK)制备到芯片制作的全套集成电路研制过程 。
半定制电路
并非针对某一用户,有一定的 母板 结构
只设计全套掩膜版中的一块或数块,包括门阵列法和可编程阵列法等
ASIC的主要优点
降低了产品的综合成本 提高了产品可靠性 提高了产品的保密程度和竞争能力 降低了电子产品的功耗 提高了电子产品的工作速度 大大减少了电子产品的体积和重量
2-2 专用集成电路的主要结构形式
2-2-1 主要结构形式
- 全定制 ASIC
- 行式结构
- 积木块机构
- 规则阵列结构
- 半定制 ASIC
- 固定门阵列
- 可编程逻辑器件
- FPGA
行式结构
芯片中央为单元阵列和布线通道,芯片四周是输入输出
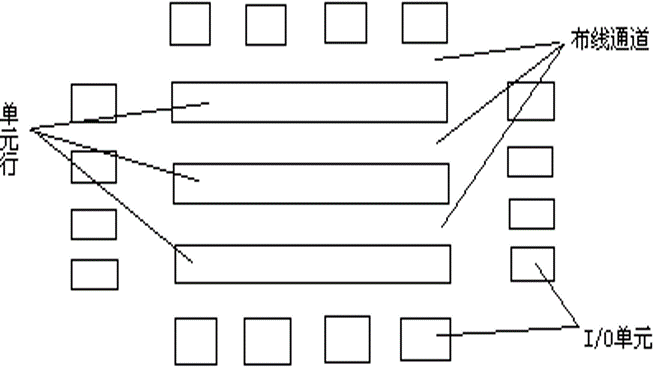
积木块结构
所谓的积木块结构是一种大的单元的布图结构,这些单元可以是一种CAD 产品的规则结 构,也可以是一块优化门阵列,还可以是人工精心设计的电路单元或者存储器阵列。标准专用 电路通常采用积木块结构。
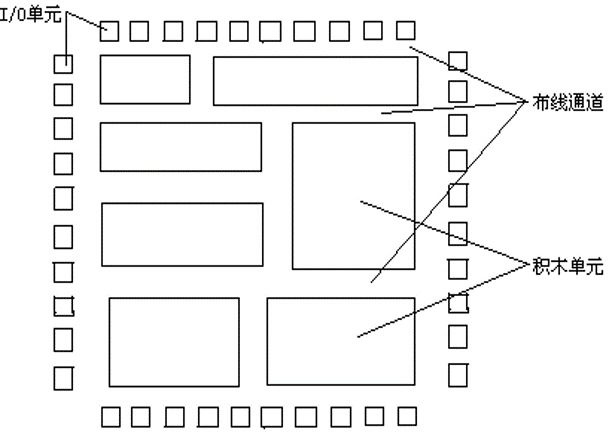
单片机这种结构的布线通常将连线按数据流和控制流进 行分类,采用面向线网的布线方法。所谓面向线网的布线方法是指布线的优化是按照线网顺 序进行。
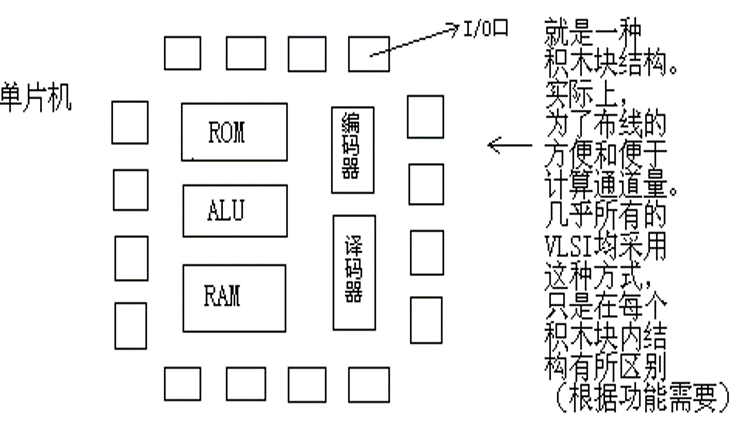
规则阵列结构
一般为两级阵列:与阵列 和 或阵列
固定门阵列
固定门阵列实现 ASIC 是在预先生产的门阵列母片上进行布线,来完成 ASIC 的一种结构 和设计技术。
可编程逻辑器件 PLD
- PROM:
- PROM(Programable Read Only Memory)其基本结构包括一个固定的“与”阵列,其输出加到一个可编程的“或”阵列之上,主要用于有效计算机程序和数据。
- PAL:
- PAL(Programable Array Logic)器件即可编程阵列逻辑器件,由一个可编程的“与”阵列和一个固定的“或”阵列组成。其对“与”阵列可编程特性使输入项可以增多,而“或”阵列固定使器件简化。
- GAL:
- GAL(Gate Array Logic)是一种通用阵列逻辑器件,是一种可电擦写、可重复编程、可以加密的PLD。GAL器件是将一个可编程的“与”阵列连接到输出逻辑宏单元(OLMC)上输出,通过对OLMC的编程,就可在符合各种逻辑设计的需求方面,给设计者提供更大的灵活性。
- EPLD:
- EPLD(Erasable Programable Logic Devices)是一种可擦除的可编程逻辑器件,它是将EPROM直接合成于PLD 芯片之中。不同型号的EPLD大都由不同个数的宏单元组成,每个宏单元一般包括三个组成部分:逻辑阵列、可编程寄存触发器、可编程I/O控制模块。
- FPGA:
- FPGA(Field Program Gate Array)是由掩膜可编程门阵列和可编程逻辑器件二者演变而来,将它们的特性并在一起。
半定制电路有较快的设计和生产周期
全定制电路可以采用MPW的方式来试制电路从而减小风险和制造成本
2-2-2 门阵列
门阵列是一种规则化的版图结构,采用行式结构, 常采用标准 与非门、或非门 定义的门单元排列在行式结构的单元行内。
是结构决定逻辑的一种阵列
本课程涉及的门阵列
- 固定门阵列
- 优化门阵列
- CMOS门阵列
固定门阵列
固定门阵列的设计方法又称“母片”法,是一种母片式半定制技术。
固定门阵列具有规则的结构,即有固定大小、固定结构、固定I/O数量的门阵列。
优化门阵列
属于全定制集成电路
是不规则的门阵列结构,即其单元行宽度不完全相同,每行单元数有多有少,布线通道的容量也不完全相同
CMOS 门阵列
相比 TTL、ECL 等,CMOS 门阵列工艺较简单,布线、电源和地线也较好处理
2-2-3 标准单元
标准单元设计方法又称库单元法,采用逻辑单元版图,按芯片的功能要求排列成专用电路。
电源线和地线通常安排在单元的上下端,从单元的左右两侧同时出线。 电源、地线在两侧的位置要相同,线的宽度要一致,以便单元间电源、地线的对接。
单元的输入/输出端安排在单元的上、下两边,要求至少有一个输入端或输出端可以在单元的上、下两边方向引出, 单元在上、下边引出线的位置及间隔以某个数值单位进行量化。 引线具有上下出线的能力的目的是为了线网能够穿越单元, 位置和间隔量化的目的是使CAD布线简洁,目标明确。
2-2-4 可编程逻辑阵列 PLA
用掩膜编程技术 或 熔丝编程、电场编程技术来实现
PLA 利用两级 ROM 结构构成的 与阵列 和 或阵列, 其中 与阵列 只能外部输入内部输出,或阵列 只能外部输出,内部输入。
可编程MOS结构: 栅极为多晶硅浮栅,未编程时浮栅无电子沟道完全闭合,始终断开; 编程后浮栅内引入负电荷,当控制栅有高电势时排斥浮栅,浮栅打开沟道,MOS正常工作。
3-1 电路模拟原理
3-1-1 电路分析的 CAD 基本方法
人工分析 -> 实验分析 -> CAD 分析
- 人工分析
- 实验分析
- CAD 分析:把方程转为计算机可解的形式
- 建立电路元器件的模型
- 电路拓扑的描述
- 建立电路方程
- 编写计算机程序
- 显示计算结果
3-1-2 集成电路的 CAD 分析
电路功能分析:
直流分析、交流稳态分析、瞬态分析、灵敏度分析、容差分析和噪声分析以及温度影响分析等
-
欧姆定理
-
基尔霍夫定理
-
KCL 电流定律
-
KVL 电压定律
-
节点电压法(方程数少,常用于 CAD)
-
支路电流法
节点电压法运用 VCR(元件的伏安关系) 和 KCL,对GND、参考节点以外的 N-2 个节点列方程
3-2 基本电路分析
3-2-1 线性电路的直流分析
直流分析也称为直流稳态分析,做直流分析时,电路中的电容视为开路,电感视为短路。 网络的节点和支路必须编号。
节点电压法不能处理独立源支路,阻抗为0支路和流控元件。
电路矩阵的一般形式为:YV=I 或 YnVn=In
其中,Y 为导纳矩阵,V 为电压,I 为电流
- Y矩阵的主对角线上的元素为电路中相应节点上的自导纳,总为正;
- 非主对角线元素为电路节点的互导纳,总为负
自导纳:与该节点相连的导纳之和
互导纳:该节点与相邻节点的连接支路上的导纳之和
3-2-2 线性电路的交流分析
直流分析和交流稳态分析的主要差别是: 在交流分析中Y和所有数都是复数,即系数矩阵Y,电流向量I和电压向量V都会是复数矩阵和复数向量,所需求解的方程是一个复数方程。 此外,通常要考虑求解频带内的一系列的频率点,对每个频率点都要进行完整的分析。
3-2-3 非线性电路的直流分析
非线性电路难以有解析式,常用数值方法求解,譬如用 牛顿-拉夫森迭代
电路原型:
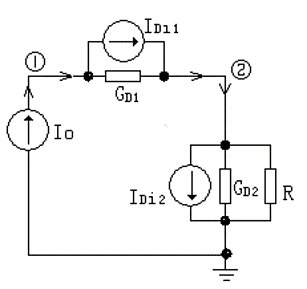
物理模型:

数学模型:
3-2-4 非线性电路的交流分析
在每个频率下分别分析
3-2-5 瞬态分析
计算电路遇到一个瞬时的激励时的瞬态过程
电容:
电感:
方法:用基尔霍夫电流定律列出节点方程,是一个微分方程组,用数值积分来求解。
欧拉法:用差商代替导数,即用代替
隐式欧拉法:用代替
用积分梯度近似可得:
-
电容的伴随模型:
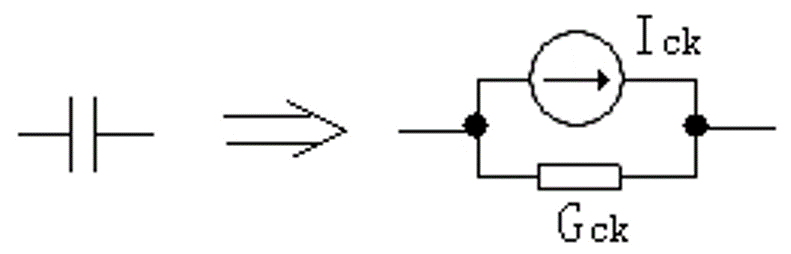
- h 为时间步长
-
电感的伴随模型:(电流不能突变
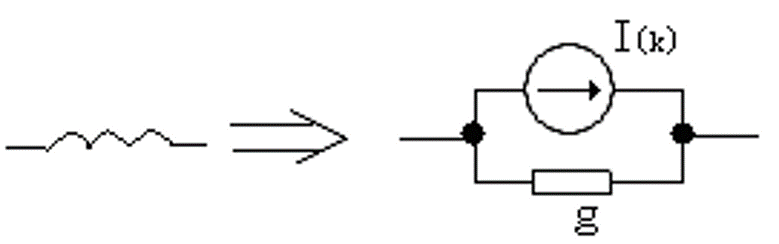
-
各类元件都可以用诺顿等效模型:电导和电流源并联
3-3 基本电路元器件模型
3-3-2 三极管的 H 参数模型
- 输入电压函数:
- 输出电流函数:
对以上二式采用全微分法,可得到 和 的微变增益一般表达式,即
可见 为交流分量, 用
得到方程组:
- 输入电压方程 ;BE 间可以等效成一个电阻与一个受控电压源串联
- 输出电流方程 ;CE 间可以等效为一个受控电流源与一个电阻并联
i: input, o: output, r: reverse, f: forward
中的四个元素量纲不同,故称混合参数(H 参数)
晶体管的H参数模型:
在放大区,输入端等效为一个动态输入电阻,输出端等效为一个电流控制的电流源
三极晶体管放大区H参数等效模型:

3-3-3 三极管的 SPICE 模型
从工艺到电气模型都包含在内
4-1 逻辑模拟
在计算机上建立数字电路模型,并向其施加一个输入序列激励,计算电路中的响应
逻辑模拟的主要用途
- 评价新的设计。检验逻辑的正确性,获得电路的竞争、冒险和电路振荡条件的资料;
- 分析故障。用测试序列分析故障,包括在一定的故障条件下的电路工作特性,和给定的测试序列下获得的故障分辨率。
4-1-1 逻辑故障的产生
冒险
对于单个逻辑信号,由于延迟的原因,组合电路可能产生瞬态错误或尖峰脉冲,称为冒险。
冒险:电路输出有瞬间的错误“毛刺”

竞争
对于多路信号,在若干信号同时改变时会引起竞争。在竞争的条件下,电路的动作取决于信号变化的实际次序。
竞争:某个输入变量通过两条或两条以上的途径传到输出端,由于每条途径延迟时间不同,到达输出门的时间就有先有后

4-1-2 逻辑模拟方式
逻辑模拟的分级
分为 门级,功能级,寄存器级
- 门级模拟:检查各门,检验逻辑和时序的正确性
- 功能级模拟:以功能块为基本部件,检查其逻辑电路的正确性
- 寄存器级模拟:检查设计的指令流程和在寄存器中传输的情况
逻辑模拟系统可用精确性、有效性、通用性来评价
- 精确性指信号值与时间的关系必须严格对应于实际电路所呈现的关系;
- 有效性指模拟过程有效而成本低;
- 通用性指程序能够处理各种各样的逻辑电路。
4-2 逻辑模拟的模型和算法
门级或混合级的模拟是逻辑模拟的主要方式。
逻辑模拟主要是验证逻辑功能和时间延迟
4-2-1 器件的延迟模型
延迟有时是好事(振荡器),有时也是坏事(引起故障)
奇数个反相器形成振荡器,偶数个形成锁存器
前级反相器驱动能力弱,容易起振
- 传输延迟 :信号通过元件和导线传播引起的延时
- 上升、下降延迟 ,:器件输出从0到1的时延 / 从1到0。两者宽度不等时会改变脉冲宽度
- 模糊延迟 :最大延迟 和最小延迟 之间的信号值不是精确可测的
- 惯性延迟 :为使器件转换状态,对于输入的一个变化所必须维持的最小持续时间称为元件的惯性延迟。若输入脉冲宽度不到 则会被门过滤;若大于等于 ,则器件表现出不小于 的传输延迟
4-2-2 多值模拟
信号有不定状态,即有可能为0,也可能为1的状态。
三值模拟
用0,1,μ表示一个信号状态的逻辑模拟

定理:组合电路C在输入序列X(t)→X(t+1)时,信号线Z存在静态冒险的充分必要条件是信号响应为0µ0或1µ1。
三值模拟的用途:
- 表示冒险
- 表示初始态
- 确定后级电路哪些会出现输入变化,哪些不会以确定面向事件的模拟
五值模拟
0到1 和 1到0 作为一个值,未知量单独用 μ
八值模拟
- 静态0值,静态1值,
- 无冒险0→1,无冒险1→0,静态0冒险,静态1冒险,
- 动态冒险0→1,动态冒险1→0
4-2-3 基本模拟程序的结构
编译法
表格驱动面向事件
4-3 测试码生成
逻辑模拟主要作用:
- 评价系统
- 分析故障
4-3-1 故障测试
用于测试电路的一组输入 / 输出信号叫做测试码或测试矢量
测试方法
- 完全测试:两种定义:
- 对应输入的所有可能的信号进行测试,共有2N个测试输入,N为输入端数,它可以测到包括冗余故障以外的所有节点,但会出现一个节点被几次测试的问题
- 对除冗余故障以外的所有节点的故障测试,对应每个故障产生一组测试矢量。这一定义的测试矢量小于上一定义
- 功能测试
- 只就电路功能进行测试,只要电路满足功能的完成即可。
- 显然会出现有些节点重复测试、有些节点没被测试的情况。
- 通常对ASIC采用功能测试,而对CPU之类的芯片采用完全测试
4-3-2 故障检测
设节点A有故障As-a-1:
为使A的故障在Z点有反映,必须使所有通路全打开,让Z=A。
∵B=0,F=A,C=1,G=A,D=E=0时Z=A,所以要使Z=A,那么为反映节点A的故障A=0,必须B=D=E=0,C=1。
正常情况,若A=0,则Z=0。而有故障情况,A=0,Z=1,表明有故障。
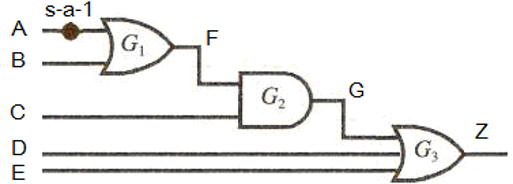
若G有故障“1”,为反映G,让Z=G,则D=E=0。为反映G=1故障,门2 输出FC=0,则C=0或F=0。则A=0,B=0即对应输入A,B,C,D,E为00×00或××000。共有5个输入序列能反映G=1故障,即00000,00100,01000,10000,11000。
冗余故障:即使出错也不会影响电路的最终输出
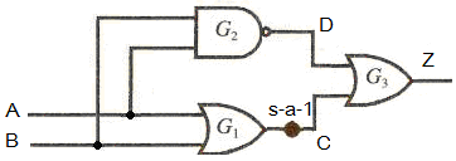
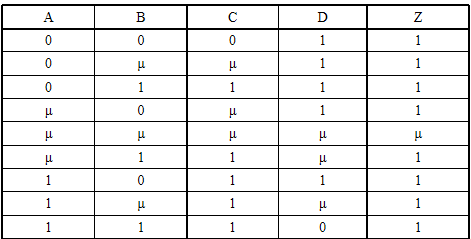
电路的三值真值表可以看出,这仍然是一个静态1冒险的电路,若需要固定输出1电平,就要避免输出μ状态,即A、B不允许同时改变状态。
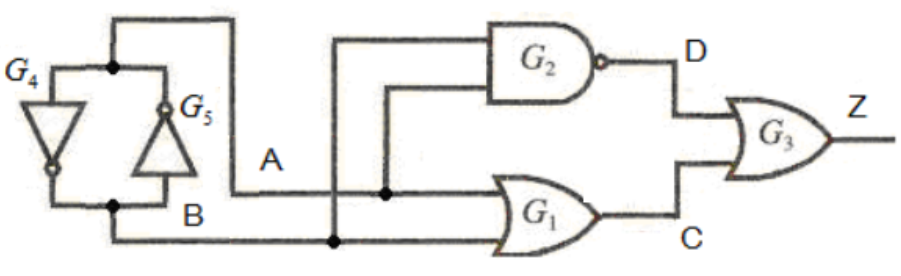
A、B端接一个双稳态电路,那么在电路上电的初始状态输出μ状态之后,A、B不允许同时为0或1状态,从电路的三值真值表可以看出,这个电路避免了成为一个静态1冒险的电路,可以实现固定输出1电平。
4-3-3 故障模型
- 物理故障:开路、短路、老化
- 逻辑故障:
- 固定型故障:当某个信号线的信号被固定在某个逻辑电平的电位上,即为固定型故障。如果该线(或该点)固定在逻辑高电平上,则称为固定1故障(stuck-at-1),记为(s-a-1);若信号固定在逻辑低电平上,则称为固定0故障(stuck-at-0),记为(s-a-0)。
- 桥接故障:当两条以上信号线短路在一起并建立逻辑时,就会产生桥接故障。若故障涉及n个线网(n>2),就称为n重桥接故障,否则称为简单桥接故障。一般在芯片原始的输入端口比较容易发生多重桥接故障。
- 元件输入端之间的桥接故障:导致 线与、线或,有可能会改变电路的拓扑结构
- 反馈桥接:桥接线跨接在输入输出端,将组合电路转变为时序电路,使电路出现振荡或反馈
- 时滞故障:一种动态故障,在高频时因为元件延时而出现,低频则无
4-3-4 路径敏化法
两种测试码产生方法:
- 代数法:根据描述电路的布尔等式求解出测试矢量
- 算法:用电路机理跟踪、敏化路径,使得故障效应传播到电路的原始输出,然后给原始输入分配满足故障传播和生成条件的值
路径敏化法:
为使输入能够检测信号点 As-a-j(j=0,1) 的故障,必须保持正常(无故障)电路的信号点A为值(暴露故障),这只给出了对检测该故障的必要条件,但并不是充分的。 同时,故障信号的效应必须由故障部位或故障原始点沿某条路径传播到输出
路径敏化法步骤:
- 反映故障:确定输入,在故障部位产生需要的值(s-a-1故障时为0,s-a-0故障时为1)。
- 传播故障:选择一条从故障部位到达输出的路径,并且确定这条路经的另一些信号值,以便将故障传播到输出。
- 确定输入:使得产生 2 中规定的信号值。
4-3-5 D 算法
D-算法是一种多路径敏化法,基于 D-立方
布尔函数的立方表示法
布尔函数可以用以下方法表示:
- 卡诺图,真值表
- 几何表示法
- 布尔函数可用集合体上所有使f=1的点的集合来表示,又可用所有使f=0的点的集合来表示。
- f=1;S1={A1,B1,C1,D1};
- f=0;S0={A0,B0,C0,D0}。
- 立方表示法:利用函数的有1顶点构成的各个子立方体来表示布尔函数。例如有两个子立方体(A1,D1)和(C1,B1),它们的坐标可以分别写成(X1,X2,X3)=(1,0,X)和(0,X,0),每一个坐标叫做一个立方。
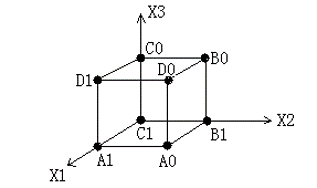
奇异立方
将f与的立方连同f的值一并列出。表中的每一行(包含自变量与函数值)称为函数的奇异立方。 这个表实质上是函数真值表的压缩形式,这个表又称为函数f的奇异覆盖。
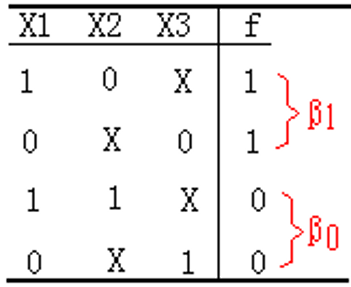
D-算法的符号与运算
- D表示正常电路值为1而故障电路值为0的信号;
- 表示正常电路值为0而故障电路值为1的信号。
- D立方代数运算与布尔代数相同,不过此时门的输入为4值(0,1,D ,)。
有:,,, ,,
原始立方
原始立方表示产生规定输出而要求的最小输入条件

故障原始-D立方
故障原始-立方是反映故障的最小条件

传播-立方
表示将故障进行传播,即对路径进行敏化, 将元件中的一个(或几个)输入错误信号传播到输出所需要的最小输入条件

立方的交
定义:两个立方中对应具有相同值的位置上,相交值即为该值; 如果在某个位置上,其中一个立方为不定值x时,相交值即为该位置上另一立方的值; 若两个立方 αi,βj在某个位置上有确定的但不相等的值,则交不存在。
例:δ=0x10,ε=x110,γ=1x1x,则δ∩ε=0110,ε∩γ=1110,δ∩γ为空(第一位不一致)
算法实现
- 根据电路组成,在计算机中建立所有门的原始、故障、传播立方。
- 选择被测故障的一个故障原始 D-立方(反映故障)。通常存在选择性:三输入与非的Zs-a-0有三种选择,初始选择是任意的,但在算法实现中可能需要放弃原选择而返回进行其它选择,这称为后退,后退可能需要重复进行,直到所有可能选择都被考虑过为止。
- 敏化从故障源到输出所选路径(故障传播),通过故障原始D-立方或已产生的测试码和传播D-立方的交来传播故障效应,建立故障传播路径并任选一条,这一过程称为D-驱动,D-驱动一直进行到某个原始输出端为 D 或 。
- 一致性操作(线合理性)即导出相应的初级输入值。在D-驱动过程中,经D-交运算形成的元件信号值称为测试立方 (未确定的可认为是x) 。
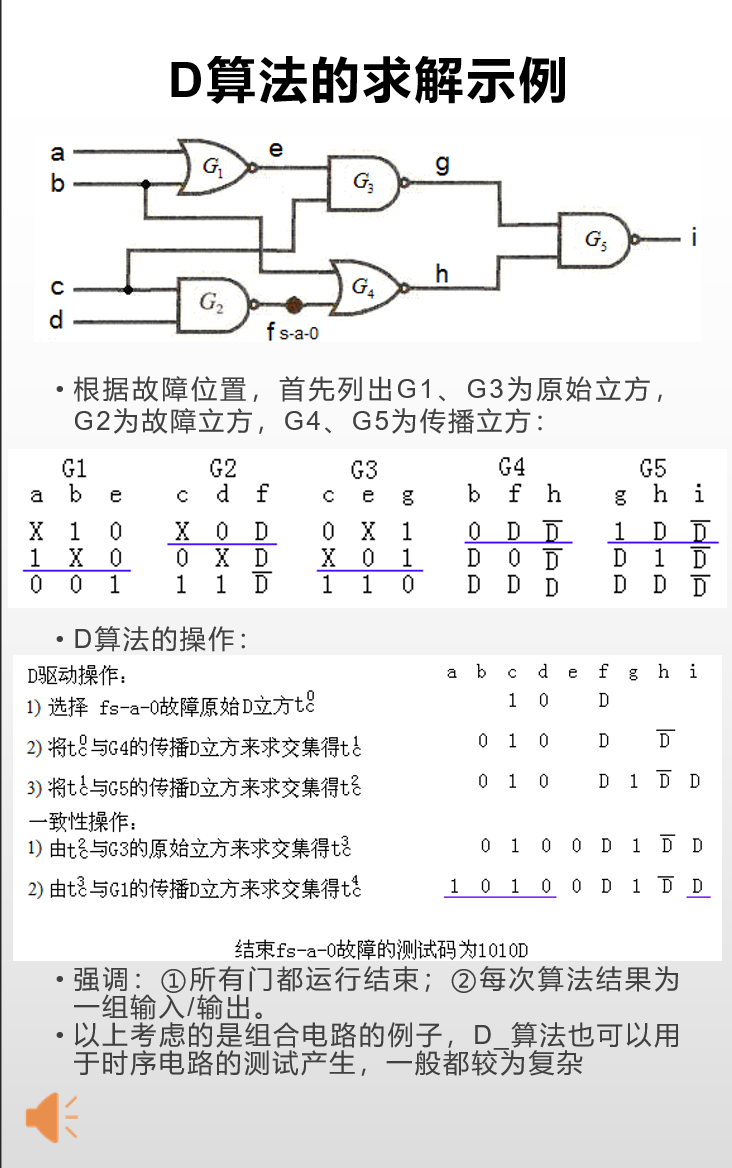
版图设计属于后端设计部分。
集成电路版图设计就是指将电路设计电路图或电路描述语言映射到物理描述层面,从而可以将设计好的电路映射到晶圆上生产。
版图是包含集成电路的器件类型,器件尺寸,器件之间的相对位置以及各个器件之间的连接关系等相关物理信息的图形,这些图形由位于不同绘图层上的图形构成。

从自动化程度划分版图设计方法:
- 全自动版图设计
- 半自动设计
- 人工设计
从版图设计类型划分:
- 标准版图设计
- 半定制版图设计
- 全定制版图设计
两种主要的版图设计方式:
- 一种是几乎所有部件的高度都相等的标准化方式,如多单元(Polycell)或标准单元(Standard cell)方式,常通过自动布图设计系统的版图,如SPR(Standard Placement Routing)等实现
- 另一种是针对各种不同大小的部件的方式,狭义来说就是积木块方式(Building Block)。这种方式允许存在像RAM、ROM、移位寄存器等规模很大的部件或子模块,因而适用的范围也较广,采用BBL(Building Block Layout)等方式实现,如BPR(Block Placement Routing)。
布图的分级:
- Top down的布图设计一般都是分级设计,布图规划是是一个软件的划分过程,主要针对软模块(网表)
- 而布局是针对全部硬模块,并且是Bottom up的布图设计,它可以是分级设计,也可以不是分级设计
一旦模块设计完成,有了具体的物理版图,它就是一个硬模块,也称为IP硬核(Hard core)。 在分级设计过程中,待设计的模块也可为软模块,即软核(Soft core)。 最低一级的是基本单元,可以是硬的,也可以是软的。 硬核与具体Foundry的制造工艺结合紧密,软核在验证正确后,可以形成固核(Custom core),也可以形成多种的硬核。
5-1 逻辑划分
布图规划的输入是一个有层次的网表,这个网表描述了功能方块(如RAM,ROM,ALU等),方块内的逻辑单元(如NAND,NOR,触发器等)和逻辑单元的接线端子。
网表是ASIC的逻辑描述;平面布局是ASIC的物理描述;因此,布图规划就是逻辑描述(网表)和物理描述(平面布局)之间的映射。
5-1-1 划分要求
逻辑划分的原则是:
- 逻辑功能块的功能完整性: 每个模块完成一定的功能,即模块对应的子电路在电学上、逻辑上是相对独立的。
- 连线尽量在模块内实现: 使每个模块的内部均有较强的连接关系,同时使模块间有尽量弱的连接关系。
一个电路系统As,它可以划分为m个子块,每个子块有对应的面积和端子数; 子块的面积和端子数有约束条件,一般存在上限
5-1-2 典型算法
简单连接度法
若用B(Ai)表示单元Ai所有的外部连接的集合,则
- 两个单元Ai,Aj之间的连接度(即连接数)为:
- Ai,Aj之间的分离度(即无关连线之和)为:
,
算法过程:
- 任何一个电路都是由若干单元构成,在待划分的单元集A中取出一个单元,第一次划分选取原则是具有与其它单元最少连线的单元,表示为最小,放入划分集Ai中,Ai由ɸ变成,A变成。
- 在A中取出一个单元a2,使Con(Ai,a2)为最大,即最相关。如果存在两个以上连接度相同的单元,则选Dis(Ai,a2)最小的单元,即a2与其它单元有弱的连接关系。
- 检查, 如满足条件则转(2)继续执行;若不满足条件,则转(4)。
- 检查A=ɸ,若不满足条件,i=i+1,转(1)产生新的划分集;否则结束划分过程,输出划分结果。
5-1-3 框架规划
I/O 和电源规划
时钟规划
5-2 布局
布局就是要在满足有关约束条件下对已划分后的n个组件寻找一个最优放置方案,以使某一个或多个目标函数为最优或较优,这需要制定一定的测量技术和算法规则。
布局一般在一个平面上实现。
布局的目标函数与约束条件
- 几何要求:满足设计要求,不能重叠,单元间划出布线通道,面积尽可能小
- 拓扑要求:具有强连接的单元间的距离要求,譬如最长线网长度限制
理想的布局目标
- 保证100%能完成布线
- 关键线网的最小化延迟
- 使芯片上放置的单元尽可能紧密
优化的目标
- 最小化能量耗散
- 最小化信号间的交叉
量化的具体目标
- 总的互连线长度的最小化估计
- 满足关键线网的时钟需要
- 最小化互连线拥挤情况
5-2-1 距离树
距离树是一个近似的指标,是一种互连线长度的定量方式,用曼哈顿距离计算
反映了一个线网的所有节点的结构图被称为树
几种常用的树
- 最小生成树:其顶点是线网的个顶点的最小长度树
- 最小斯坦纳树:其顶点是包含线网的个点的最小长度树,线网本身的连线包含在树内
- 最小链:从源点开始,连接所有的个点,除起点和终点的连接度为1之外,其余点连接度为2,并以最小长度连接个顶点
- 矩形半周长:包围线网的所有顶点的矩形的半个周长
5-2-2 布局处理算法
5-2-3 初始布局
初始描述
初始布局就是在满足约束条件的情况下,按照一定的目标,把单元安放在芯片的特定位置上。 为以后的布局迭代改善提供较好的初始条件
单元布局描述:
其布局描述为:
- cell A 2,3,4,5
- cell B 1,6
- cell C 1,2,7
- cell D 3,4,7
- cell E 5,6
规则
- 选择规则:主要以未安置单元与已安置单元的连接度为依据
- 安置规则:一般总是将待安置单元放在已安置单元的邻域的空位上。这些空位的集合称为候选单元位置集Sp
究竟安放在哪个位置,需要采用上述的四种距离树中的一种来进行估算
以最小生成树为计算规则进行安置,单元应安置在所有线网总距离为最小的位置上
5-2 布线
布线就是在满足工艺规则和电学规则情况下,完成给定的信号线网连接,并使布线结果最佳
通常将布线分成总体布线和详细布线两部分;另外根据对象的不同又可分为面向线网的布线和面向通道的布线;根据布线区域也可以分为门间布线与通道布线
总体布线主要是面向整个线网的布线,而详细布线更多的是指通道布线和通道内的面向线网的布线;一般情况下,除了门间布线是单元(或模块)内部的布线外,其余都是指单元(或模块)外部的布线
5-3-1 门间布线
即单元内布线
门阵列
以三输入与非门为例
- 符号表示:
- 端点描述:
in:A,B,C out:O - 版图连接描述:
- 线段描述:横线段由三个数据组成:纵坐标、起点横坐标、终点横坐标。竖线段也由三个数据组成:横坐标、起点纵坐标、终点纵坐标。都是三个数据,区别为横线的第一个数据前有个“-”号。
- 输入输出描述:
- 输入:INPUT 端子号,上出线端坐标,下出线端坐标;
- 输出:OUT 端子号,上出线端坐标,下出线端坐标。
5-3-2 通道布线算法
布线区与通道区:
- 布线区是一个总体的概念,是指芯片中除电路单元所占区域以外的能进行布线的区域。
- 通道区指的是被电路单元布局分割后出现的各个分离的矩形区域
二边通道布线模型
所谓二边通道指的是通道具有二边平行边界的通道。在给定通道的上下边界上等距的分布着各个线网的端子。除0以外的相同端子号代表是同一线网,把各出线端按号加以连接就构成了线网,0号端子表示在该位置是空的引线端。左右两端的引线用对应的端子号标注,其出线的上下位置是自由的,即该端点可以用导线延伸。除固定门阵列外,通道宽度可根据线网的多少调节宽度。

双层布线的严格分层
对于二边通道布线,通常必须用双层布线,即两层金属层布线,中间绝缘层; 或一层半布线,即多晶竖线,金属横线
垂直约束图
为了防止同列的竖直线重叠,则水平线所处的上下位置关系必须符合一定的约束条件。采用一个有向图来表示这种约束关系,称为垂直约束图VCG。
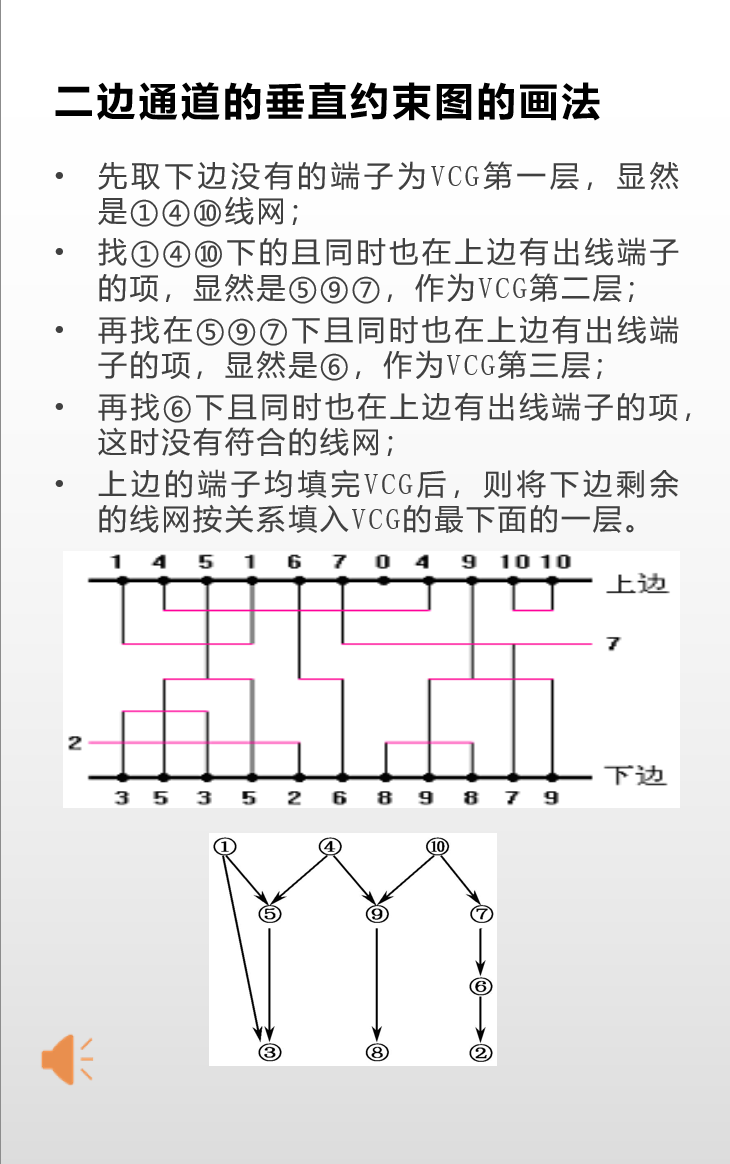
水平重叠区(带区)
重叠区是通道区中一个尽可能大的连续的列的集合,通过重叠区(包括通过重叠区中某些列)的任何二条线网都不允许在同一条水平布线通道上。
自左向右扫描,当某列上有线网结束时,做个记号。 如在后面的第j列上有新的线网开始时,则新的重迭区从第j列开始,而前一个重迭区在j-1列结束。 也有一些特殊情况,若同一列既有线网结束又有线网开始,则可以划分为一个独立的区; 若此时前面的分区没有划分,则合并为一个分区。

5-3-3 面向布线区的布线方法
第一步进行总体布线,第二步进行通道布线。
总体布线
总体布线是将布线区划分成通道及线网区的分配
- 通道划分:对于如门阵列、标准单元等的行式结构的芯片形式,其单元区间的区域即为水平通道区。同时单元的硅栅或预留的穿线道即为垂直通道。线网的分配和布线主要在水平通道内进行。
- 线网在各通道的分配:将线网分配到各个通道的算法的主要依据是对两点间路径的分配
- 李氏算法:有两种方法
- 现要连接A→B,通过李氏算法的单源波扩散可以找出一条无任何阻挡的最短路径(阴影部分是布线障碍区),可见从A到B的最短路径为10步,共有有两种走法。
- 为双源波扩散的李氏迷宫算法,为源X和目标Y之间寻找一条最短路径。在X源端和Y目标端同时发出一个波,向外扩散,在每个格子上编号,一旦两个扩散波相遇,即可完成连接,如果有两个格子编号一样,优先选择不拐弯的格子
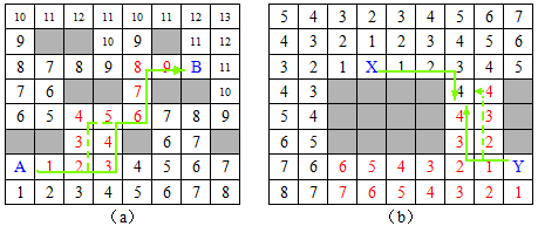
- 海塔算法:一种线搜索算法,使用线而非波来寻找连接。比李氏算法更有效率
- 线网划分:
- 将线网按李氏算法分配到各通道,如是多点线网,则进行分解,两两连接。会导致部分通道要布的线超过其通道容量,称之为关键通道
- 将线网中的部分拆除,一般先拆溢出最大的线网,有多种布线方案的线网也拆。被拆的线网需要分配到非关键通道。重复该过程直到所有所有通道线网密度小于通道容量为止(有时这个过程进行到所有通道的线网分布比较均匀时为止)。
通道布线
主要是考虑线网的排列顺序和如何走线。有多种算法,这里只考虑二边通道布线的算法。
- 无约束左端算法
- 各线网间不存在垂直约束关系,每个线网在通道内只有一条水平线。只要决定这个水平线的位置,便完成了该线网的安置。
- 因为不存在垂直约束,两个线网的垂直线不会相交。垂直线可以从出线端所在列连接所对应的水平线
- 有约束左端算法
- 当前能布的线网是活动线网,如果活动线网中有线网已布线,就要修改垂直约束图;
- 然后又产生新的活动线网,布线中新产生的活动线网与原有的活动线网同等的参加布线;
- 布线仍按水平布线线道顺序进行,布线集始终由活动线网组成
活动线网:VCG 的最下层
同一批活动线网中,从左向右铺
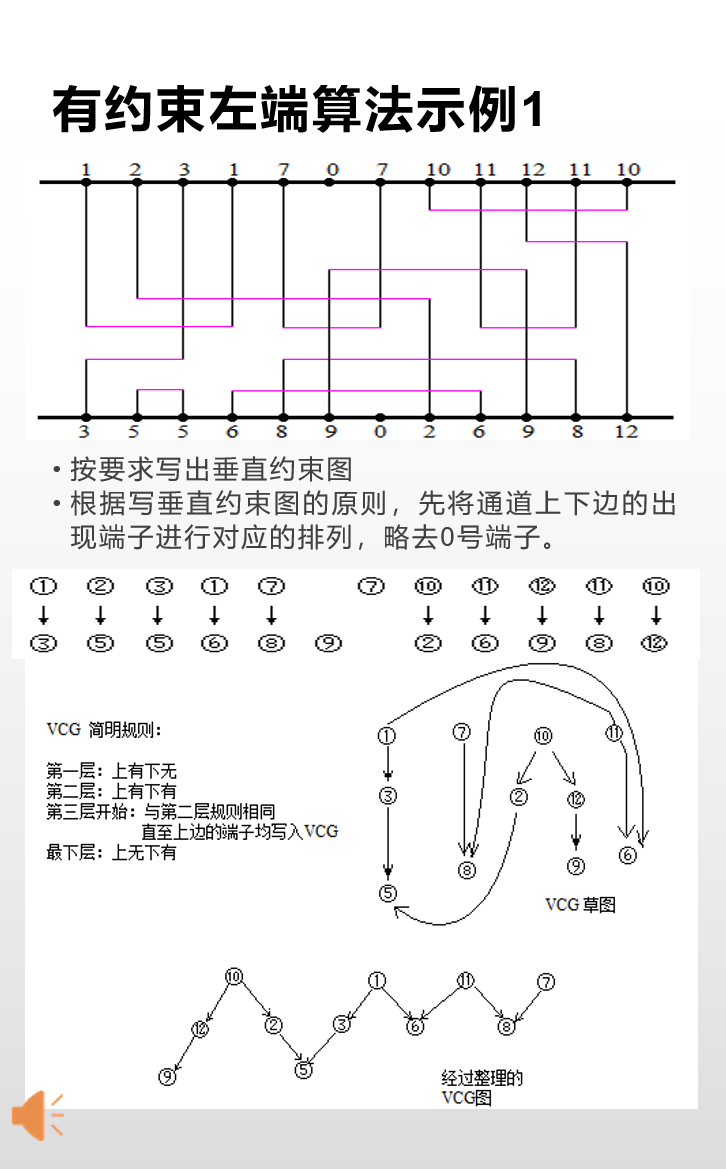
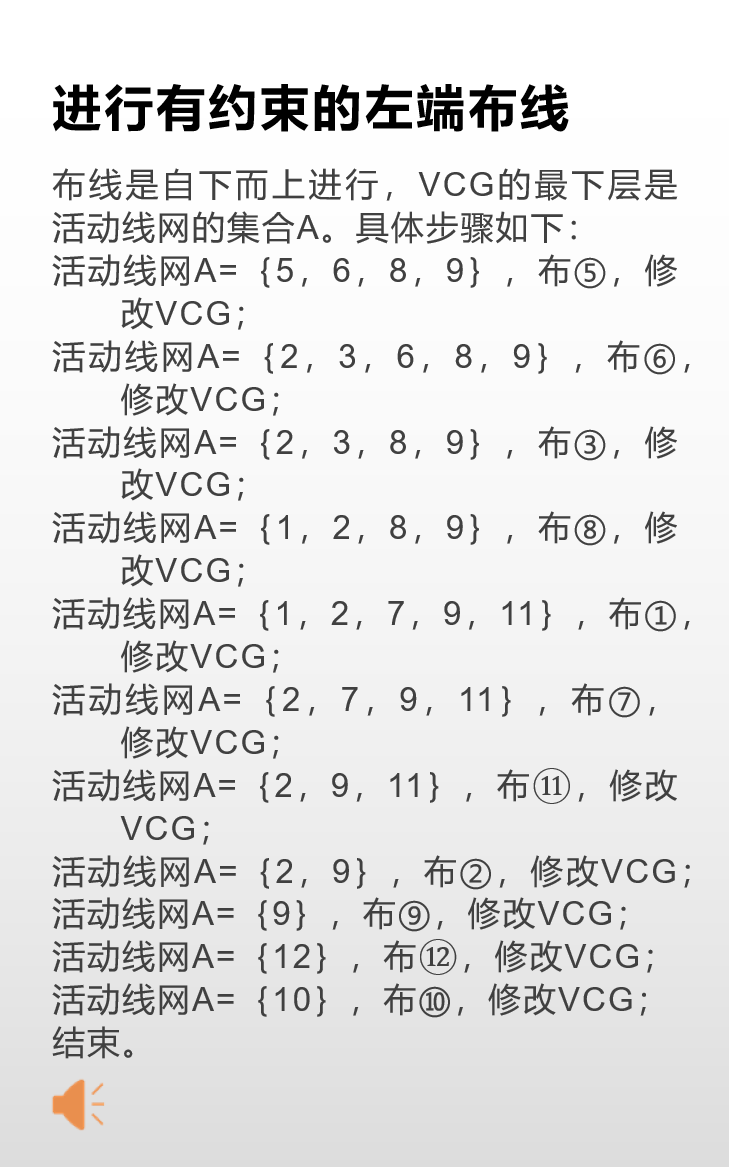
水平重叠区划分通道,保证通道数能够完成通道布线
计算机视觉
3周实验,1周报告
1 图像处理基础
1-1 图像定义
- 图像:二维函数
- 数字图像:由像素构成
- 用二维矩阵描述
- 像素值为整数
- 原点为左上角
1-2 空间滤波
图像 * 模板
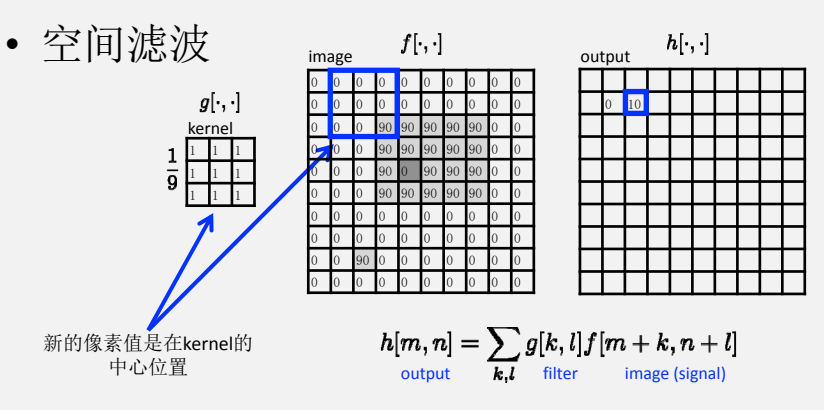
1-3 空间滤波的应用
边缘检测
- 图像梯度
- 通过梯度计算边缘点
1-4 Hough 变换
Hough 变换原理:
- 利用图像空间和 Hough 参数空间的点-线对偶性
- 把图像空间中的检测问题转换到参数空间
- 通过检测参数空间中的极值点来估计该曲线的参数
直线
参数空间:y=mx+b,m和b为变量,x和y为参数
由此每个点(x, y)对应一条参数空间m,b上的直线
直线拟合: 多个点则得到多条参数空间中的直线,获得一或多个交点。 相交最多的参数交点即为拟合得到的直线。
还可以用极坐标:
| 方程式 | 参数空间 | |
|---|---|---|
| 斜截式 | m, b | |
| 极坐标 | θ, ρ |
圆
若圆的半径未知,参数空间是圆锥
| 方程式 | 参数空间 | |
|---|---|---|
| 半径已知 | a, b | |
| 半径未知 | a, b, r |
2 相机与成像模型
2-1 小孔成像
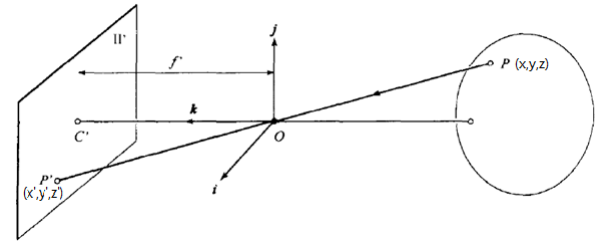
透视投影方程:(相似三角形)
三点共线
2-2 成像特点
- 近大远小
- 不保持平行性:平面上的平行线在像平面上可能相交(铁轨)
聚焦条件:
变焦:改变焦距(移动镜头组中镜片的相对位置)
对焦:让像成在底片上,通常移动镜头来实现
薄透镜:透镜厚度在计算中可忽略不计
3 相机标定
相机标定:求解 3D 到 2D 的映射的参数
相机的几何模型:
3-1 齐次坐标
用 n+1 维向量表示 n 维向量:
- 原坐标
- 齐次坐标
平面:
球面:
3-2 坐标系变换
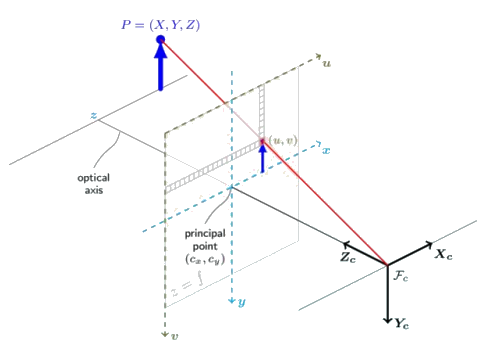
世界坐标系,相机坐标系,
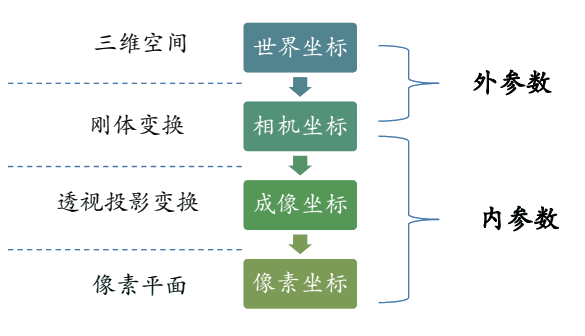
两个几何变换:
- 从世界坐标系到相机坐标系的刚体变换(相机的外参数)
- 从相机坐标系中三维坐标到成像平面上二维坐标的透视投影变换(相机的内参数)
刚体变换
刚体:形状、大小不变,内部各点的相对位置不变
刚体变换:把刚体做旋转、平移等坐标变换
是两个正交坐标系间的变换
- 平移变换:
- 旋转变换:
- 例如坐标系 A 绕 k 轴旋转:
- 通用旋转矩阵:
- 刚体变换:
下标指示被表示的对象,上标指示用来表示对象的坐标系, 如是坐标系 A 下 P 的表示,是坐标系 A 在坐标系 B 中的旋转矩阵。
3-3 相机建模
虚拟成像平面:与物理成像平面平行,在光轴上距光心为 f
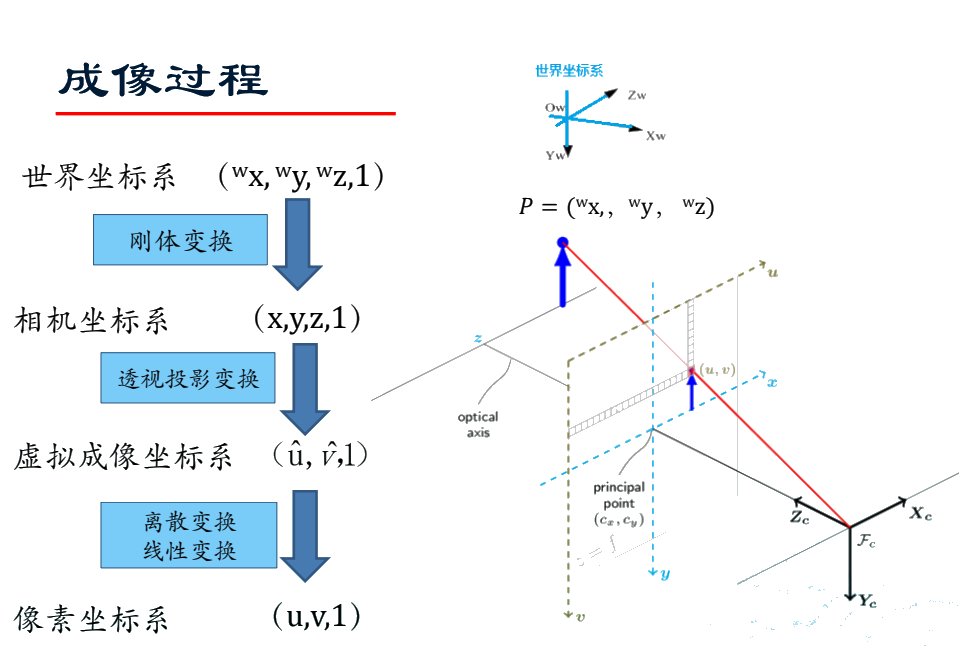
像素坐标尺度内参外参世界坐标
注意:r 为三维列向量
歪斜角 :相机传感器非矩形而是平行四边形
像素纵横系数:,将虚拟成像平面映射到物理成像平面(像素坐标系)
3-4 参数求解
最小二乘法
当 时,最小化误差函数 E
若 y 均为0,则为齐次方程,解为 的最小特征根所对应的特征向量
算法步骤
- 物点的世界坐标,像点的像素坐标)经由多组数据的最小二乘法,得到(矩阵 M 的 12 个元素值)
- 再算出相机的内外参数之积 M
计算 M
令 ,有 , 得
将 n 组点代入(即 n 个 u,v,P)
转为齐次方程:
则得 为矩阵 最小特征根对应的特征向量 其中 ρ 为齐次方程的系数。由此解出 M。
,且 ,
其中 ε 表征物体与相机是否在世界坐标系的同一侧(1 为同)
估计参数
4 图像配准
4-1 图像配准
- 图像配准可以视为源图像 I2 和目标图像 I1 关于空间和灰度的映射关系: 其中: f 为二维空间坐标变换(如仿射变换),g 为灰度变换。
- 图像配准问题的关键:最佳几何变换 f
- 选取图像特征
- 估计几何变换
图像配准的模式分类
- 按自动化程度分类:
- 人工配准方法
- 半自动方法
- 全自动方法
- 按成像模式分类:
- 不同视角(多视角分析)
- 不同时间(多时段分析)
- 不同传感器(多模式分析)
- 场景与场景模型图像配准
- 按图像配准的应用领域分类
- 医学、遥感、计算机视觉、军事等领域
- 按图像的维数分类
- 2D-2D、2D-3D、3D-3D
- 按对图像信息的利用情况分类
- 基于灰度信息
- 基于特征信息
4-2 图像预处理
4-2-1 图像的灰度变换
- 线性灰度变换
- 对数灰度变换
- 分段线性灰度变换
- 直方图的均衡化
4-2-2 图像的平滑处理
- 邻域平均法
- 中值滤波
4-3 图像配准
4-3-1 主要方法
基于灰度的图像配准
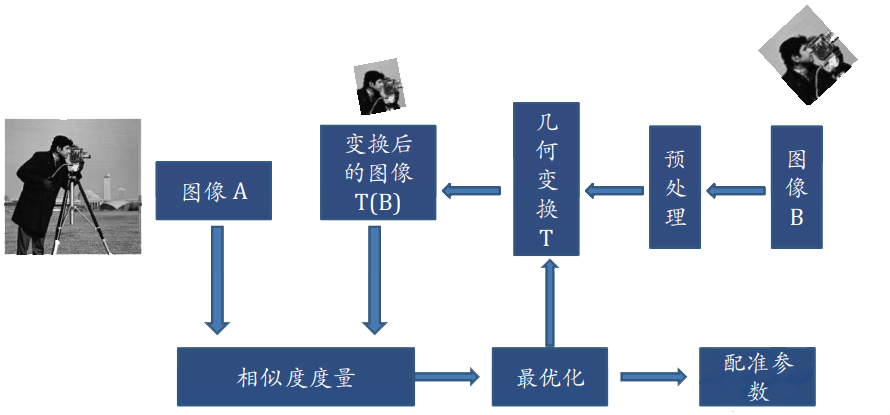
基于特征的图像配准
- 特征提取
- 特征匹配
- 通过特征估计变换模型
- 图像重采样
图像配准的核心模块
- 特征选取
- 充分表达图像的内部结构
- 消除畸变噪音的干扰
- 降低参与计算的数据量
- 几何变换的选取
- 选择合适的几何变换
- 搜索策略
- 动态规划、牛顿法、最速下降法、共轭梯度法
- 相似度度量
4-3-2 特征选取
- 找到图像特征点
- 特征点配对
- 图像拼接:通过匹配的特征点,估计参数
角点检测
- 角点:像素值变化剧烈的点
- 定义移动窗口的像素变化值
- W 为窗口
- 移动量为 (u,v)
- 窗口内像素变化函数
Harris 角点检测
- 假定窗口滑动微小,图像平滑,则通过泰勒展开
则:
圆括号内的 求和 记为矩阵 H
根据特征值的计算公式:
得到H的两个特征值:
-
几何关系
- 表示 E 的最大变化分量
- 征表示 E 的最小变化分量
- 在方向的增量值
- 在方向的增量值
-
平坦区域: 和 都很小
-
边缘区域: 大, 小
-
角点区域: 和 都很大
Harris 算子
Harris 无需计算特征值,算子大则检测到角点。
4-3-3 特征描述
SIFT描述子
- 提取图像的局部特征
- 具有平移、旋转、伸缩不变性
- 对光照变化、仿射变换和三维投影变换具有一定的鲁棒性
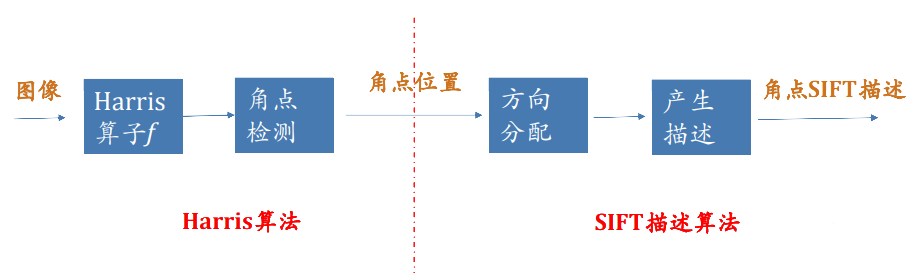
SIFT描述子产生过程
- 方向分配
- 在关键点为中心的邻域窗口,计算每个点的梯度
- 用直方图统计邻域像素的梯度方向分布(每10度为一个统计区间)
- 最大的梯度所在的方向即为关键点的主方向
- 产生描述
- 将坐标轴旋转为关键点的主方向,确保旋转不变性
- (以窗口长度为8为例)
- 根据预设的尺度与角度,在特征点附近取窗口
- 获得窗口内每点的梯度
- 将原始窗口分为2×2共4个子窗口,计算每个窗口内的梯度直方图(仅考虑8个方向)
- 这2×2×8共32个数值(4个直方图),获得特征描述
- 归一化以消除光照影响
4-3-4 特征匹配
- 设特征 和 是与特征 最近和次近的特征
- 计算距离比例
- 当r小于某个阈值,则匹配成功
- 阈值的选取需根据图像确定(建议范围:0.4到0.8)
由于图片角点十分多,因此需要用 K-d 树等数据结构来加速
K-d 树略
4-3-5 几何模型估计
转自 doowzs 的博客,推荐国防科技大学-计算机网络
本笔记将原书(自顶向下第四版)的 第四章 拆为 第四、第五两章
拾遗
| TCP/IP | OSI | 数据单元 | 主体 | 协议 |
|---|---|---|---|---|
| 应用层 | 报文 message | 进程 | SMTP | |
| 应用层 Application | 表示层 Presentation | |||
| 会话层 Session | ||||
| 传输层 Transport | 分段 segment | 端口 | TCP UDP | |
| 网络层 Network | 分组/数据包 packet | 主机 | IP | |
| 链路层 Data Link | 帧 frame | 节点 | 以太 | |
| 物理层 Physical |
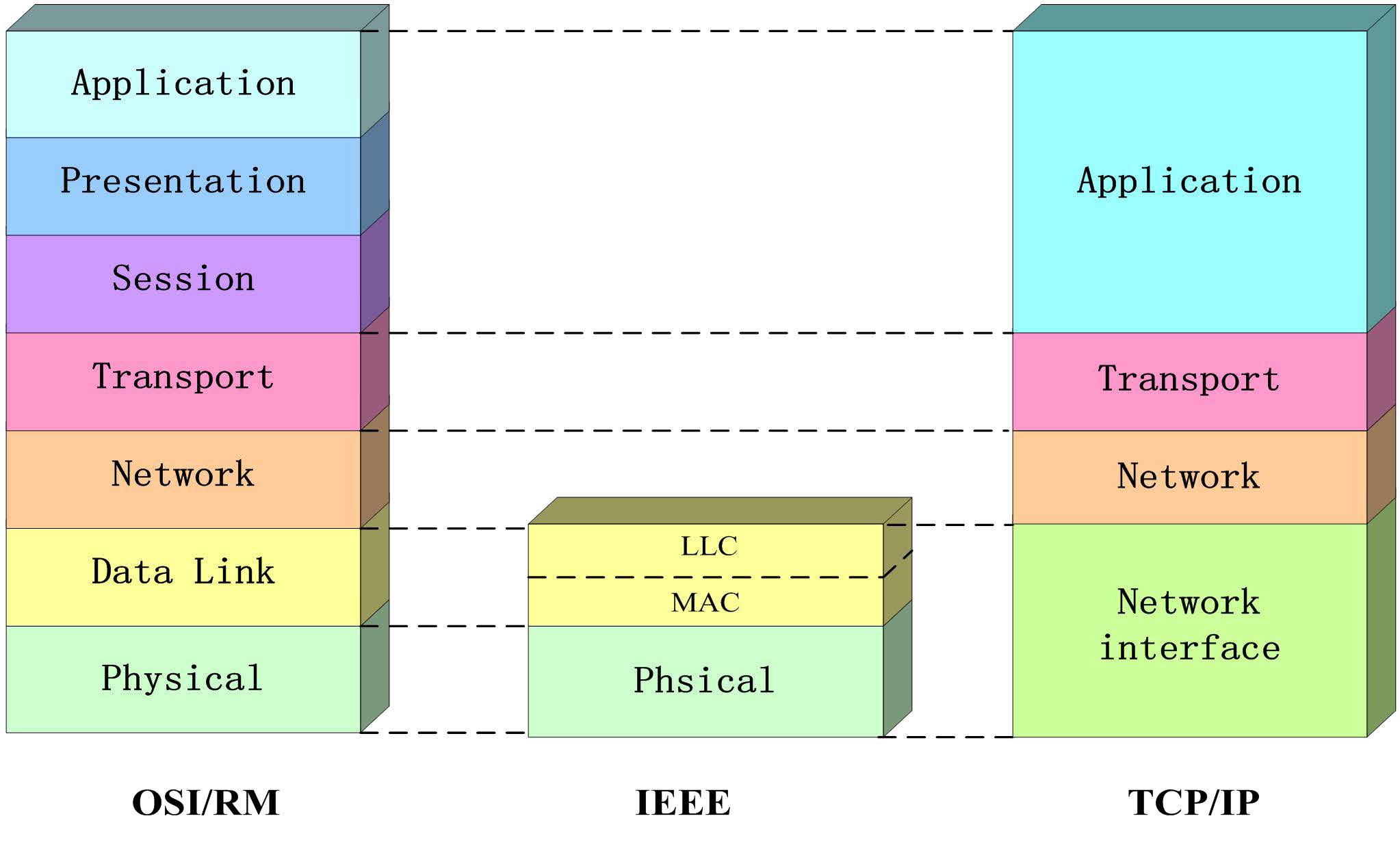
socket:
- 相当于操作系统的 API 罢了
- UDP socket 教程
网络协议:为进行网络中的数据交换而建立的规则、标准或约定。
由以下三个要素组成:
- 语法:即数据与控制信息的结构或格式。
- 语义:即需要发出何种控制信息,完成何种动作以及做出何种响应。
- 规则:即事件实现顺序的详细说明。
要发给外网的报文:
- 目的 MAC 应该是路由器 LAN 口,因为是路由器负责转发
- 目的 IP 应该是服务器(废话
路由器转发后的报文:
- 源 MAC 和源 IP 都应该是路由器 WAN
- 目的 MAC 应该是网关,不过如果不用走网关(即服务器在同一子网内,但不归这个路由器管,因为有公网 IP),就直接写服务器 MAC,因为路由器 ARP 里有这个服务器
- 目的 IP 应该是服务器(废话
1 计算机网络与因特网
按范围分类
- Body Area Network
- Personal Area Network
- Metropolitan Area Network
- Wide Area Network
- InterPlanetary Network
按节点移动性分类
- The Internet
- Wireless Sensor Network
- Optical Network
- Mobile Communication System
- Satellite Communication Network
- Mobile Ad hoc Network
1.3 网络核心
分组交换
分组交换中不会预留带宽、缓存等
计算机网络是分组交换
电路交换
电路交换中会预留带宽和缓存,建立连接时,沿途所有交换机都为其维护连接
电话网络是电路交换
电路交换的优势是可确保服务质量,有专用资源,不会被干扰
1.4 分组交换网中的时延、丢包和吞吐量
端到端时延
传播延时 prop只与链路长度有关,视为常量
- 消息 message:应用层中进程间交互的数据单元
- 分段 segment:传输层中端口间交互的数据单元
- 分组 packet:网络层中主机间交互的数据单元
- 帧 frame:数据链路层中节点间交互的数据单元
2 应用层
| 应用 | 应用层协议 | 传输层协议 |
|---|---|---|
| SMTP/POP3 | TCP | |
| The Web | HTTP | TCP |
| File transfer | FTP | TCP |
| Resolve domain names | DNS | UDP |
| Trivial File Transfer | TFTP | UDP |
| Remote login | Telnet | TCP |
get 返回信息中的 content length 单位是字节
邮箱服务器之间使用 SMTP,POP3 纯收邮件,IMAP 在线直接访问邮件
3 传输层
UDP(User Datagram Protocol)
几乎等同裸的 IP,只能通过网络层(IP)提供的源地址信息分辨发送者
- 无连接传输,不可靠,可靠性要由应用层实现
- 首部 8 字节,总长不超过 64KB()
- 服务端一个套接字可接收多个客户端连接
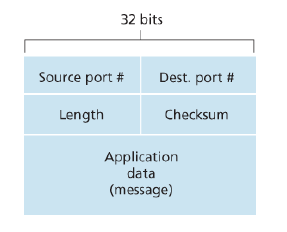
校验
(每个字长 16 bit)
对包含伪首部、首部、数据在内的数据:
- 每 16 位求和得到一个 32 位数
- 若高 16 位不为 0,则高 16 位与低 16 位相加,得到新的 32 位数
- 重复步骤 2 直到高 16 位为 0,将低 16 位 取反 得到校验和
取反使得检验时只要将校验码和数据一起相加即可得到全1
能确保检测到 1bit 错误,2bit 及以上不一定能检测。
伪首部包含 源IP,目的IP,补位用的8位全0,协议代码(17),UDP数据包长度。伪首部仅用于计算校验和,不会真的发送。
TCP(Transmission Control Protocol)
- 可靠传输,有持续连接和非持续两种
- 首部 20~24 字节
- 服务端一个套接字仅服务一个客户端连接
Reliable Data Transfer
参考:可靠数据传输基本原理
rdt 是没有窗口的
- rdt1.0:
- 假设信道完全可靠
- 收发双方都只有一个状态
- rdt2.0 停等:
- 假设信道只可能比特受损
- 差错检测,接收方反馈,重传:NAK 的时候重传,ACK 的时候继续
- 不能在等待反馈的时候接收上层数据,故称 停等
- rdt2.1:
- 考虑反馈受损
- 加上分组编号,由于停等,故只要 0 1 两个编号
- rdt2.2:
- 不发 NAK,只发最新的包的 ACK
- 冗余 ACK 相当于 NAK
- rdt 3.0 ABP,比特交换协议:
- 考虑数据丢失
- 加入定时器 RTT(往返时间 round trip time),超时就重传
- 利用率:
Go Back N
- 发送方可以有 N 个未确认的数据包(也就是最多能 回退 N)
- 接收方只依次 ACK,不能跳跃。若收到的包不连续,则持续 ACK 上一个连续的包
- 计时器给最老的、未确认的包计时
- 刚建立连接时,接收方构造一个虚的 上次确认
- ,k 为数据包序号长度
Selective Repeat
- 发送方可以有 N 个未确认的数据包
- 接收方为每个数据包单独 ACK
- 每个数据包都有一个计时器
- ,否则若 ACK 全丢失,会把重传数据当成新数据
TCP
是 GBN 和 SR 的结合
- 像 GBN 一样只为最老的数据包计时
- 像 SR 一样支持不连续的ACK,即:支持累积确认,总是传 ACK 请求的包
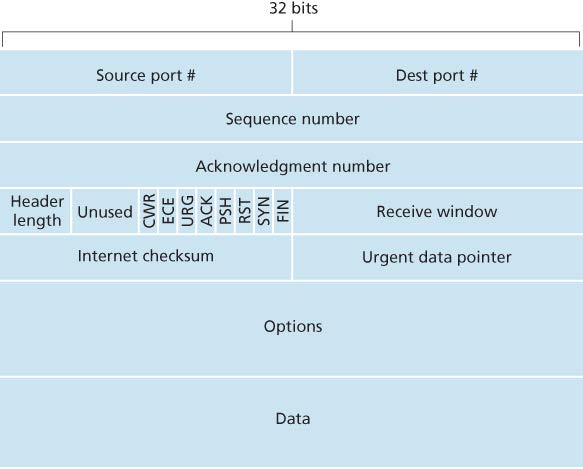
ACK
确认的 ACK = 发送的 seq+1;确认的 SEQ = 发送的 ack。双方都是这样
序列号是当前字节在文件中的偏移量,确认号是希望收到的下一个字节的偏移量
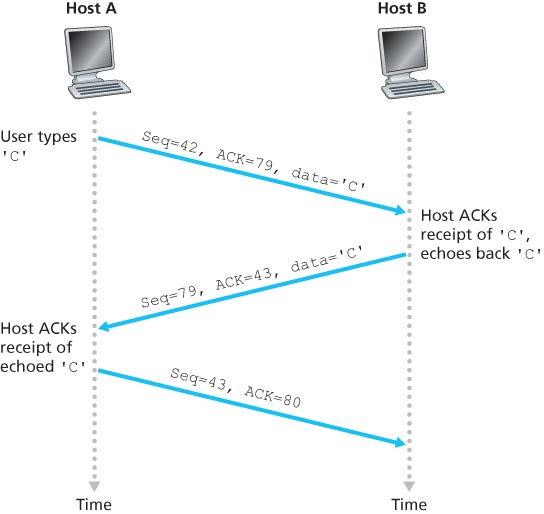
只有 TCP 的 ACK 会超前,GBN、SR 的ACK 都不超前
RTT
计时器要长于 RTT
- 过短:不必要的重传
- 过长:效率低
估计 RTT:
- SampleRTT:忽略重传的,并且最近的传输权重大
忽略重传:是因为若出现 premature timeout,即第一次的 ACK 在超时重传后才送达,则发送方的 RTT 测量为错误结果
重传
三种重传:
- 超时重传:定时器结束时未收到 ACK,则重传
- premature timeout:重传后收到 ACK,接收方收到重传后仍确认最大的序号
- 跳过 ACK:没收到上一个 ACK,就收到了后面的 ACK,发送方仍继续发送收到的 ACK 请求的数据包
总之一切照常
快速重传:连续收到三个相同的 ACK 就立刻重传,不管定时器
流量控制
发送方有一个接收窗口 rwnd,即未确认的数据包不能多于 rwnd。也就是 GBN 和 SR 里的 N。
三次握手
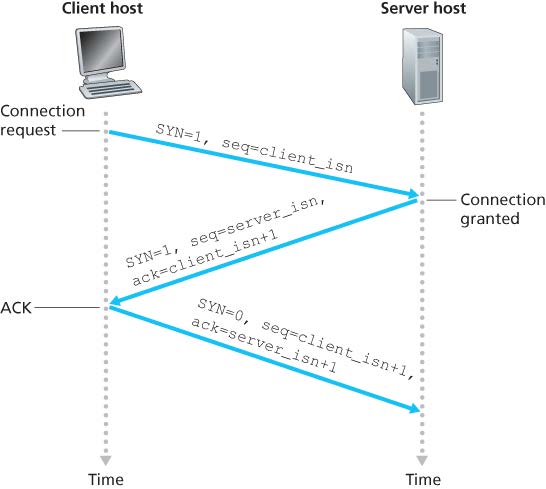
第一、第二次握手的 seq 都是随机生成的,第一次握手无 ACK,其他正常。
第一、第二次握手的 SYN = 1,不能携带数据;第三次 SYN = 0,可以携带数据
若服务器的一个老第一次握手请求发送到了客户端,客户端会进行确认,但服务器会注意到过期的 ISN 编号,并忽略该第二次握手。
同样,客户端也会检查第二次握手中的 ISN 编号。
四次挥手
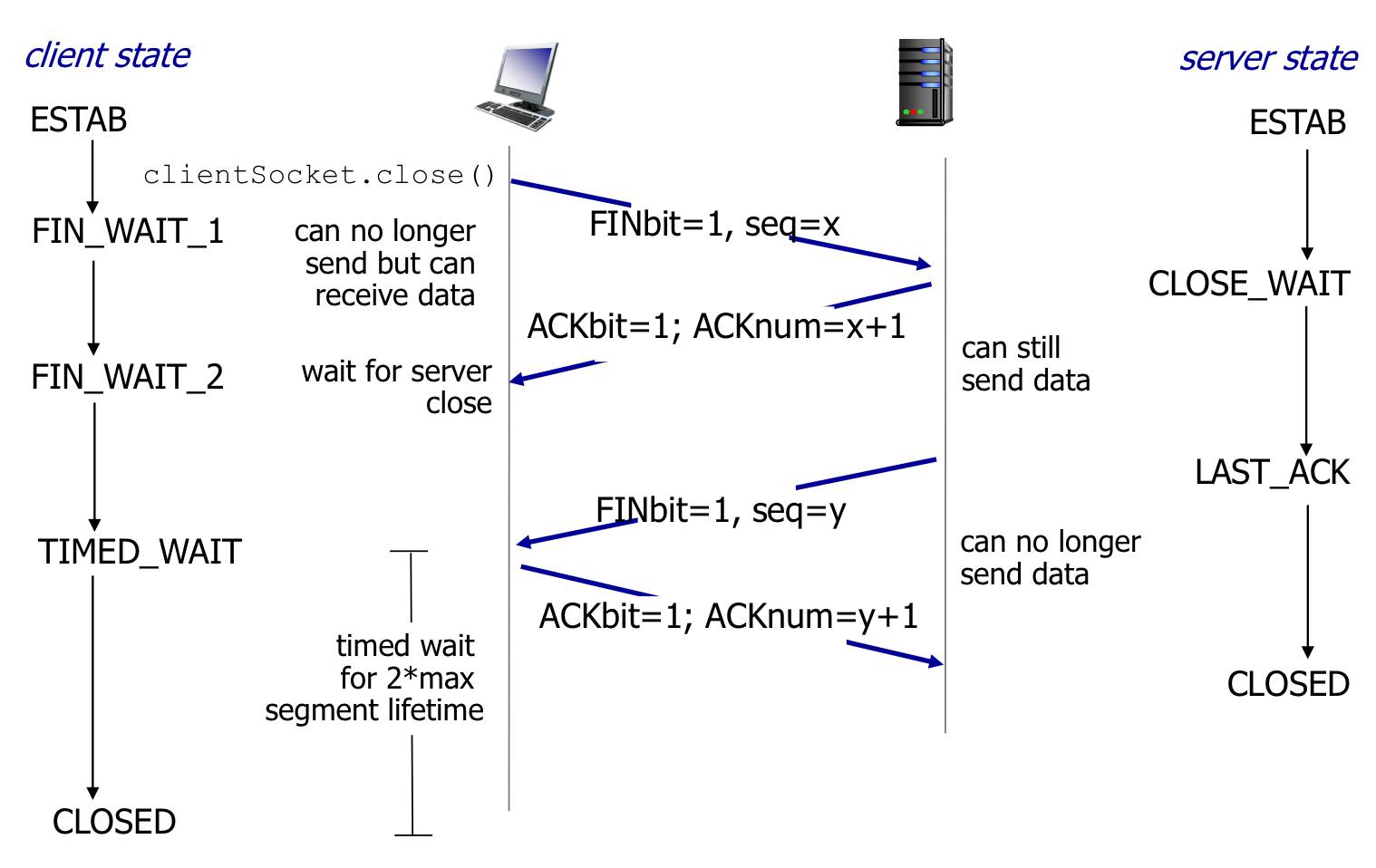
第一、第二次挥手可以携带数据,第三第四次不行(因为连接已断开)
拥塞控制
流量控制是收发双方间的,是为保证来得及接收而控制发送速度; 拥塞控制是防止网络中数据过多,使网络过载,而控制发送速度。
加性增加,乘性减少
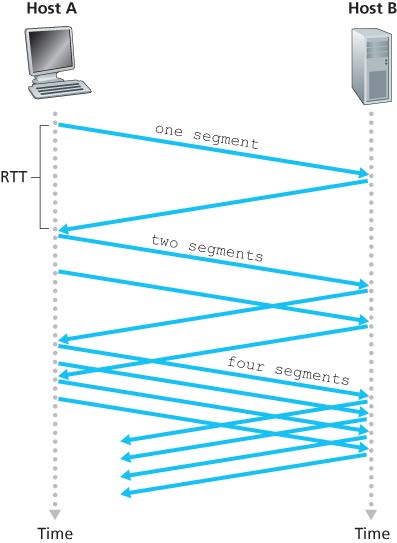
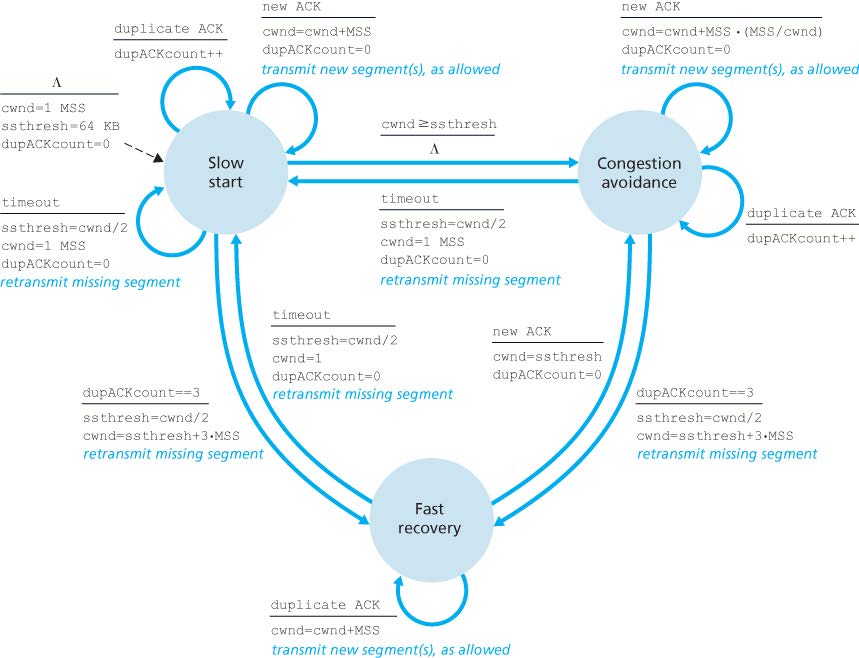
TCP congestion-control algorithm: (cwnd = congestion window, ssthresh = slow start threshold)
- slow start:(指数,超时或初始进入,以窗口为1为开始)
- 初始状态或出现超时时将发送窗口长度设置为1,此后每收到一个ACK则窗口长度+1(也就是每一轮之后翻倍)
- 若窗口大小达到慢启动阈值则进入拥塞避免
窗口1+1=2后,发送的数据数也变为2,于是会收到2个ACK,则该RTT下窗口长度2+2=4,实现指数增长
- congestion avoidance:(线性)
- 收到新ACK时 cwnd = cwnd + MSS/cwnd
MSS:最大报文段长度
- fast recovery:(指数,三个重复ACK时进入,以窗口锐减为开始)
- 每收到一个重复的ACK则恢复1个发送窗口长度(指数)
- 收到了新的ACK则恢复拥塞避免
- 若超时则进入慢启动状态,阈值设为窗口的一半,窗口设为1
- Tahoe:有重复三个 ACK 时将窗口设置为1(旧版)
- Reno:有重复三个 ACK 时将阈值设为先前窗口的一半,窗口为阈值(+3MSS)(常用)
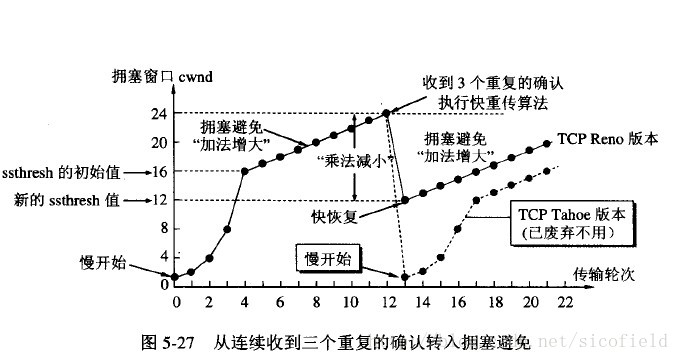
窗口减半后,即进入快速恢复后,若窗口指数增长,则还是快速恢复;若窗口线性增长,则是拥塞避免
TCP 平均吞吐率:3 / 4 W,W 为拥塞窗口大小
TCP 公平性:
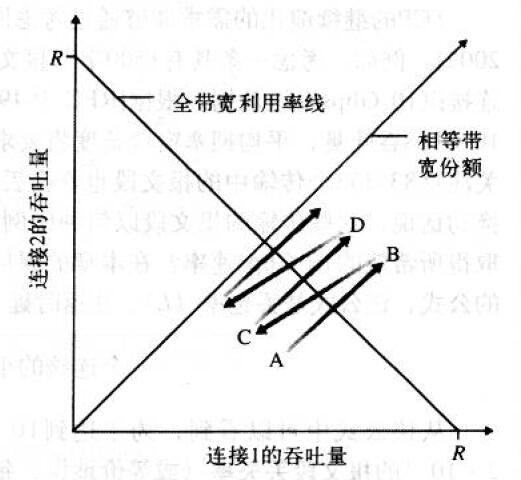
从 A 开始,到 B 时丢包,减半至 C(C 为 B 与原点的中点),如此反复不断逼近最优点
4 网络层1:数据
虚电路和数据报网络
虚电路:预先建立好路线;数据报:每个报文单独走
都是分组交换!
Virtual Circuit 虚电路
在废物 ATM 网络用过(不是自动柜员机啦
一条虚电路在不同路段的编号不同。如果相同,那要修改就会影响整个网络。
转发表
| 入接口 | 入VC号 | 出接口 | 出VC号 |
|---|---|---|---|
| 1 | 12 | 2 | 22 |
| 2 | 63 | 1 | 18 |
| 3 | 7 | 2 | 17 |
| 1 | 97 | 3 | 87 |
每经过该路由器创建一个新虚电路,就会在表里加一项
虚电路是单向的(只是有些题目的设定罢了!)
选路和转发
- 选路是在网络中寻找到目的节点的路径,通常依赖选路算法进行;
- 转发是在已知路径的基础上,根据路径选择下一个节点,以便转交数据包
- 两者的关联:选路是转发的基础。
Datagram Network 数据报网络
最长前缀匹配
| Prefix Match | Link Interface |
|---|---|
| 11001000 00010111 00010*** ******** | 0 |
| 11001000 00010111 00011000 ******** | 1 |
| 11001000 00010111 00011*** ******** | 2 |
| otherwise | 3 |
Ex:11001000 00010111 00011000 00011000 10101010 -> 1
一般而言,路由器仅需将部分地址转发至内网,其它的统统指向外网即可,于是不用记忆四十亿地址
路由器
输入排队
HOL(Head of the line)Blocking 是一个 由于其队伍前面的数据报被阻塞,导致即使其自己的目标出口畅通,也被阻塞
IP(internet protocol)
- 无连接,不可靠
- 首部 20~24 字节
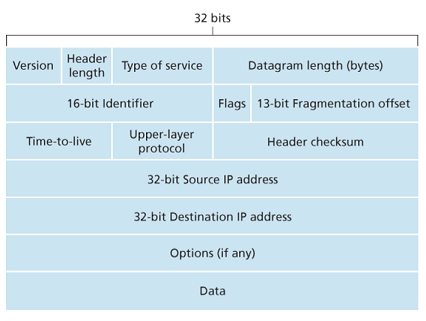
- Time to live:每转发一次就减一,减到 0 时路由器必须抛弃该数据包
- Upper layer protocol:上层协议,仅会在到达终点的时候用到,6 = TCP,17 = UDP
IPv4 数据包分片
分片可能在任一个节点进行,还可能出现多次分片
不同链路都有不同的最大传输单元 MTU(maximum transmission unit),即硬件限制。当要传输的数据包大于链路的 MTU 时,就要进行分片。
每次分片,IP 头部都会占用 20 字节。
- length:含 ip 头 的字节长度
- id:同一个分组的分片有相同 id
- flag:是否还有后续片
- offset:之前的(按原数据算)所有片的字节长度除以 8(不含 ip 头)
原数据总长也算了头部!
IPv4 编址
IP 地址分给网卡而不是主机
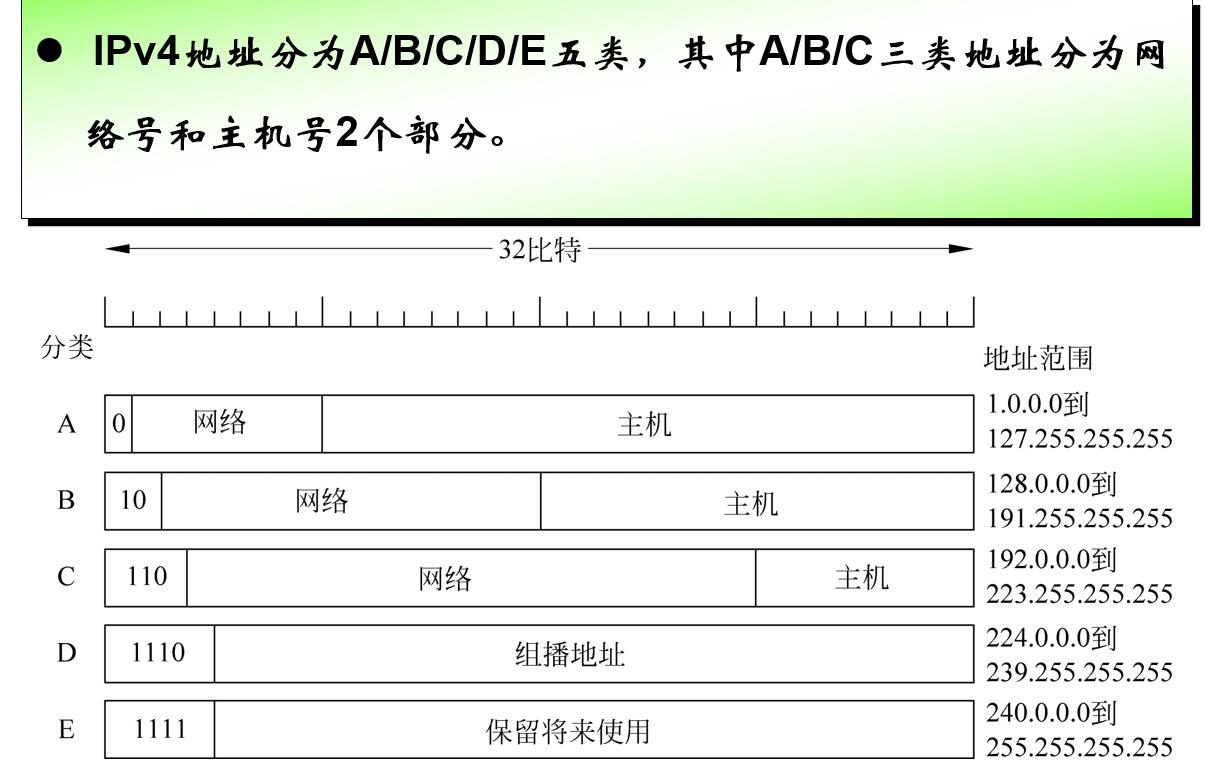
- 全 0 为该网络的该主机
- 主机全 0 为网络地址,路由器路由表现
- 网络全 0 为本网络的某主机
- 全 1 为受限广播地址,本网络全部主机
- 主机全 1 为直接广播地址,某网络全部主机
127 开头为回环地址
10.0.0.0~10.255.255.255,172.16.0.0~172.131.255.255,192.168.0.0~192.168.255.255 为内网 ip
补充知识:
100.64.0.0/10已经被用于运营商NAT。
分子网只会减少能用的主机!子网只是方便路由器进行管理
- 子网:将主机位中的前几位设为子网号
- 子网掩码:将标准地址与掩码按位与得到子网号(故默认掩码为 255.255.255.0)
- 例如 255.255.240.0 (240=11110000)从B类网络的16位主机号借了4位作为子网号,即
- 子网号中全0全1保留,故子网至少要2位,主机号也至少2位
CIDR(Classless Interdomain Routing)
a.b.c.d/x 中 x 为子网长度
CIDR aggregation:聚合 CIDR,即把多个 CIDR 表示的子网聚合成一个 CIDR 表示的子网。目的是减小最长匹配的长度
转发表
写转发表时,前缀越长越好。题目可能会对前缀数(即 entries)有要求,一般是 others 里加一条,补其它接口的空子:即写一个比之前接口更长的,且不影响那个接口转发的前缀
DHCP(Dynamic Host Configuration Protocol)
- 新加入的主机会用 UDP 向所有设备 67 端口广播
- DHCP 服务器收到广播后会向所有设备广播要启用的新 IP(广播是因为新设备还没 IP 地址),即 DHCP offer
- 新来的主机会选用一个 offer 并向对应的 DHCP server 请求
- server 发送 ACK
NAT(Network Address Translation)
用端口号表示内网连接
穿越NAT方法:
- 静态配置:绑定路由器某端口与内网设备的某端口
- UPnP:动态配置
- 中继:将NAT信息登记到应用提供商的服务器
|WAN side|LAN side| |24.134.112.235:5001|192.168.1.3:3345| |24.134.112.235:5002|192.168.1.3:3346|
其中24.134.112.235为路由器 WAN 口 ip,192.168.1.3为内网某主机
ICMP
internet control message protocol,主要通知报错信息
ICMP 报文包含一个类型字段和一个编码字段
ICMP通常被认为是IP的一部分,但从体系结构看是在IP之上,是3.5层。
traceroute就基于ICMP

IPv6
- 128 位地址
- 固定的 40 字节头部
- 不再分片,要是过大就用 ICMP 发个“Packet Too Big”给发送方
- 可以用 Tunnel 把ipv6的报文封装在ipv4的里,需要人工配置隧道
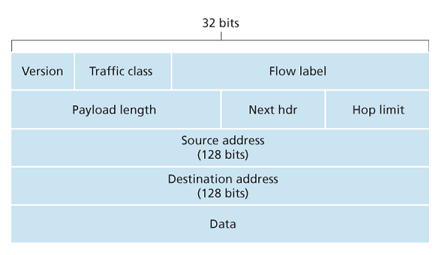
5 网络层2:控制
路由算法
路由器只关心下一跳去哪,而不关心整体的路径。路由算法负责维护转发表。
把网络抽象为有权图,路由算法就在该图中求解最短路径。
-
全局路由算法:L-S
-
分布路由算法:D-V
-
静态路由算法:人工填写,若拓扑结构有变化(例如链路故障)就要人工及时修改
-
动态路由算法
LS(Link-State)路由算法
Link-State Packet,链路状态报文,即路由器测量与其直接相连的路由器的链路状态(延时), 生成LS报文,并向所有路由器广播,由此每个路由器都获得了完整网络拓扑结构。
一个 LS 报文记录从路由器 A 到路由器 B 的链路状态,路由器每收到一个邻居发来的 LS 报文就要应答, 并向其他路由器发送新收到的这个报文
每个路由器会对每个已收到的 LS 报文贴上一个序号和生存期,此后只会记录序号更大的 LS 报文
获得完整网络拓扑结构后使用 Dijsktra 算法:
- D:cost,P:上一跳的点,N:记录各个 D 最小的点,一开始仅含起点
- 先找一遍邻居
- 把 D 最小的点加入 N,然后从 D 最小的点,重复上一步,若 D 变小就更新之。加入 N 的点就不再写其值
考虑流量的时候,会出现链路负载振荡的现象
要写到所有点进 N 为止
Distance-Vector (DV) 路由算法
DV:Distance vector,距离向量
路由器 A 计算自身到C的成本(A-C不直连):获取邻居路由器 B 到 C 的成本,则 A到C = A到B + B到C
当链路状态有变化时,将自己的 DV 发给邻居,邻居据此通过Bellman-Ford 算法重新计算,若有变化,则通知邻居
好消息更新快,坏消息更新慢:因为坏消息之前的状态会残留在邻居的通知内

出现路由黑洞,通过毒性逆转解决,即当 C 通过 B 选路到达 A 时,C 告诉 B:C 到 A 的成本为无穷大 (然而该协议在环路内失效)
要写到某一步无更新为止
对比 LS 和 DV
- 报文复杂性:DV仅在新的链路费用导致最优路径变化时才广播,而LS在任意变化下都广播
- 收敛速度:DV收敛慢,还有路由黑洞
- 鲁棒性:DV算法的一个不正确的节点计算值会扩散到整个网络
Intra-AS Routing(自治系统内选路)
intra-AS Routing 也被称为 interior gateway protocols(IGP)
上述选路算法在大规模网络的迭代一定不会收敛,并且单个路由器不应受限于外部网络而被迫选用某种选路算法。
自治系统(Autonomous System,AS)用于解决这两个问题。
AS之间运行自治系统间选路协议(inter-AS routing),一个AS内部的路由器运行相同的选路算法(intra-AS routing),且拥有彼此之间的信息。每个AS都有一个或多个负责连接外部网络,称为网关路由器。
AS routing 是要让 某个 AS 知道地址ip属于哪个 AS;当这个地址属于两个AS时,还要在AS层面确定选哪条链路最优。(选路算法必须让每个ip只有一条路径)
RIP(Routing Information Protocol)
基于 DV
- RIP的成本计算是以跳数计,一跳就是1,最多支持15跳。
- 路由器每30秒与邻居打一次招呼(更新)
- 每次只能更新25个目的子网
路由器根据邻居发来的通告(即邻居自己的转发表)更新自身转发表。若180秒未监听到邻居,就认为其不可达,并通告其他路由器。
路由器也可以使用RIP请求邻居到指定目的地的费用(以UDP的方式使用520端口)
OSPF(Open Shortest Path First)
OSPF是RIP的后继者。RIP是DV类算法的典型代表,而OSPF是LS的代表协议核心是一个使用泛洪链路状态信息的协议和Dijkstra算法。
OSPF 通告包含在OSPF报文中,而报文直接承载在IP分组中,不依赖TCP、UDP。
OSPF 将AS再细分为了多个区域(area),其中有一个主干(backbone)区域,负责为其他区域之间的流量选路。
- 内部路由器:不属于主干,只执行 intra-AS
- 区域边界路由器:同时属于区域和主干
- 主干路由器(非边界路由器):内部路由器通过所在区域的主干路由器知晓通往其他区域的路由
- 边界路由器:与其它AS的路由器交流
自治系统间选路:BGP
BGP 是全互联网使用的 自治系统间选路算法
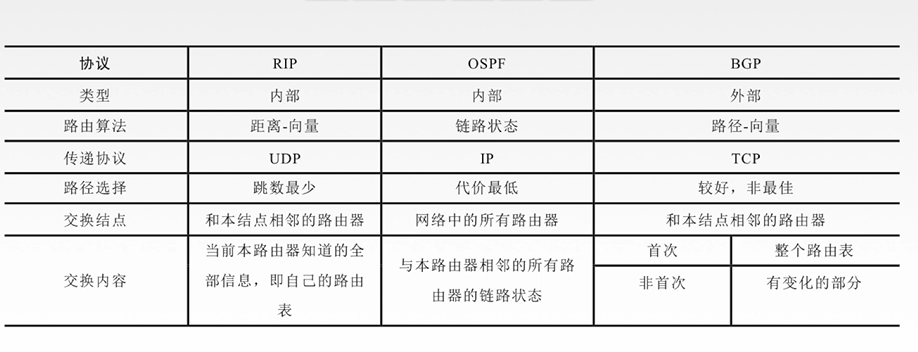
- eBGP:在AS之间传播可达信息,网关路由器用eBGP向其他网关路由器通告所在网络能够到达的其他网络
- iBGP:在AS内部传播可达信息,网关路由器用iBGP向所在网络的其他路由器通告eBGP获得的信息
eBGP 需要直接连接,iBGP不需要(TCP报文可以经过多跳)
BGP Notes
BGP 只计算 AS 跳数,不计算路由器跳数,即:BGP选择的是AS-path最短的路径,与路由器个数无关
Next-Hop 不会保留源路由器的端口号,而是改为发布者的端口号,便于回溯
广播和多播选路
广播
源不必把一个报文发多次,每次设定不同目的,而是只要发一次,在路由时广播。
节点转发过就不必再转发,节点通过序号来辨别,即转发的报文只递增不递减。
用生成树的形式实现,源作为树的根。
组播(多播)
地址为D类,即1110开头。组播地址需要申请。
IGMP
Internet Group Management Protocol,互联网组管理协议,既不属于传输层,也不属于网络层
IGMP 管理路由器上的组播组,并维护状态表来进行转发。
6 链路层
链路层简介
链路层提供的服务
- 成帧(framing):有帧头帧尾,故又称帧定界
- 链路接入(媒体访问控制协议/MAC)
- 可靠交付(相邻节点间可靠,不保证端到端可靠,因为可能在节点被抛弃)
- 流量控制
- 差错检测和纠正
- 半双工和全双工
链路:加上可靠性控制的电路
链路层在何处实现
- 主体部分:网络适配器(network adapter)/网络接口卡(Network Interface Card, NIC)
- 网络适配器核心是链路层控制器,一个实现了许多链路层服务的专用芯片
- 链路层功能大多是硬件实现的,但部分是在运行于主机CPU上的软件中实现的
链路层是硬件和软件的结合体,即是协议栈中软件和硬件交接的地方。
0.5层:驱动,在软件做;1.5层:网卡,在硬件做。
源到目的可能经过多种链路层协议
差错检测和纠正
3种技术:
- 奇偶校验
- 加上校验位后共有奇数个 1 or偶数个 1
- 二维:在纵向也进行奇偶校验,如此能够实现差错纠正
- 最短校验和:一般在将数据排成接近正方形的格式能实现最短校验和
- 检验和(checksum,适用于运输层)、因特网检验和
- 切成16位一段,取二进制补码,求和,把进位加回最低位
- 循环冗余检测(CRC,适用于适配器中的链路层):多项式编码、生成多项式
- 数据 D,r+1 位的生成多项式 G(最高次为r),G 的最高位须为1
- 发送方选择 r 个附加比特 R,附加到 D 之后,使得得到的 d+r 能够用模2算术被 G 整除
- 接收方若发现不能整除,则出错
- R 实际就是 (D<<r)/G 的余数(此处除法每步是异或,不是减法!)
- codeword:D后接R
若 G 中 的系数非0,则可以检测所有 1 比特差错(根据数字通信,这俩必须为1,所以永远能检测 1 比特)
若 G 中含有 至少三项的因式~~()~~,则可以检测所有 2 比特差错
若 G 中含因式 x+1,则可以检测所有奇数比特差错
可以检测长度不大于 r 的差错,大于 r 的不一定能检测到
G 的各项系数为 1 或 0,所有运算均模 2
能否检测x比特差错:若一个阶数不大于 d+r,错误位数为x的错误模式,可以被 G 整除,则不能检测x比特差错。譬如1000001可以被1101整除,故1101不能检测所有2比特差错
多路访问链路
多路访问问题(multiple access problem):如何协调多个发送和接收节点对一个共享广播信道的访问?
- 多路访问协议(multiple access protocol):节点通过这些协议来规范它们在共享的广播信道上的传输行为,并且不需要一个单独的信道进行管理。又称介质访问控制协议。
- 碰撞(collide):多个节点同时传输帧,所有节点同时接到多个帧,没有一个节点能够有效的获得任何传输的帧。
- 3种类型的协议:
- 信道划分协议(channel partitioning protocol):借助频分、时分、码分划分信道
- 随机接入协议(random access protocol):允许冲突,协议负责从冲突中恢复
- 轮流协议(taking-turns protocol):轮流让信道担任管理者
随机接入协议
随机接入协议中,一个传输节点总是以信道的全部速率进行发送。当有碰撞时,涉及碰撞的每个节点反复地重发它的帧(分组),直到该帧无碰撞的通过为止。
但是当一个节点经历一次碰撞时,它不必立刻重发该帧,而是等待一个随机时延(独立地选择随机时延)。
常见的随机接入协议:
- ALOHA:纯 ALOHA 和 时隙 ALOHA
- 载波侦听多路访问(CSMA)(以太网)
纯 ALOHA
- 当一帧首次到达(一个网络层数据报在发送节点从网络层传递下来),节点立刻将该帧完整地传输进广播信道。
- 如果帧的传输经历了碰撞,该节点立即(完全传输后)以概率 重传该帧。
- 否则,该节点等待一个帧传输时间。在此等待后,以概率 传输该帧,或者以概率 再等待一个帧传输时间。
成功传输要求其他节点在2个时间间隔内不传输(即只要与其它帧有部分重叠,就判定为冲突),因此一个节点成功传输的概率是 ,纯ALOHA协议的最大效率为 ,其中 N 为节点总数。
时隙 ALOHA
作出假设:
- 所有帧都是比特长
- 一个时隙等于传输一帧的时间
- 结点只在时隙起点开始传输帧
- 结点是同步的,每个节点都知道时隙何时开始
- 如果一个时隙中有两个或更多个碰撞帧,则所有节点在该时隙结束之前检测到碰撞事件
令是一个概率,则每个节点中时隙ALOHA的操作为:
- 当节点有一个新帧要发送时,它等到下一个时隙开始并在该时隙传输整个帧;
- 如果没有碰撞,该节点成功传输,不需要考虑重传;
- 如果有碰撞,则该节点在时隙结束之前检测到碰撞。该节点以概率在后续的每个时隙中重传它的帧,直到该帧被无碰撞地传输出去。
优点:
- 当某节点是唯一活跃的节点时,允许以全速连续传输。
- 分散的:每个节点检测碰撞并独立地决定什么时候重传(但仍然需要对时隙同步,即各节点时钟同步)。
- 极为简单。
载波侦听多路访问(CSMA)
载波侦听多路访问(CSMA)和具有碰撞检测的CSMA(CSMA/CD)协议族中包括两个规则:
- 载波侦听(carrier sensing):一个节点在传输前先侦听信道。如果来自另一个节点的帧正向信道上发送,节点则等待直到检测到一小段时间没有传输,然后开始传输。
- 碰撞检测(collision detection):当一个节点在传输时一直在侦听信道,如果检测到另一个节点正在传输干扰帧,就停止传输并等待一段随机时间。
由于信道传播时延,即使在侦听当前信道,仍然可能导致碰撞发生。传播时延越大,载波侦听节点不能侦听到网络中另一个节点已经开始传输的机会就越大。
具有碰撞检测的载波侦听多路访问(CSMA/CD)
- 适配器从网络层获得一条数据报,准备链路层帧,并将帧放入适配器缓存中;
- 如果适配器侦听到信道空闲,它开始传输帧。否则则等待直到侦听到没有信号能量时才开始传输帧。
- 在传输过程中,适配器监视来自其他使用该广播信道的适配器的信号能量的存在。
- 如果适配器传输整个帧而未检测到来自其他适配器的信号能量,则传输成功;否则中止传输,等待一个随机时间然后重复第二步骤(等待信道空闲)。
- 二进制指数后退(binary exponential backoff)算法:当传输一个给定帧并经历了一连串的次碰撞后,均匀地随机地从 中选择一个间隔时间长度 。对于以太网,一个节点等待的实际时间量是 比特时间, 能取的最大值在10以内。
CSMA/CD 的最小帧长 = 冲突域 * 传播速率 = 2 * 单向传播时延 * 传播速率
1-persist CSMA,1 指等待的概率为 1,也有概率为 0 或 p 的。为 0:信道忙就睡一会再来看看
比特时间:传1bit所需时间
争用期:即碰撞窗口,节点在发送完成后的争用期中监听信道,无碰撞则认为发送成功。本质为,以太网的争用期为
51.2μs
链路层寻址
MAC 地址
MAC 地址是链路层地址,是给接口的(网卡)
交换机没有 MAC地址,因为交换机应当是透明的
MAC 地址长 6 字节
- 适配器要发送一个帧时,将目的适配器的MAC地址插入到该帧中,并将该帧发送到局域网上。
- MAC广播地址:
ff:ff:ff:ff:ff:ff - 一台交换机偶尔将一个入帧广播到它的所有接口,适配器可以接收一个并非向它寻址的帧。
- 适配器接收到一个帧时,将检查该帧中的目的MAC地址是否与它自己的MAC地址匹配。如果匹配,该适配器提取出封装的数据报并向上传递;否则丢弃该帧。
ARP(Address Resolution Protocol)
下面是在ARP表中添加一条记录的过程,TTL一般为20分钟。假设交换机会广播所有帧。
- 发送方构造一个称为ARP分组(ARP packet)的特殊分组,一个ARP分组有几个字段:发送、接收IP地址以及MAC地址。ARP查询分组的目的是查询子网上所有其他主机和路由器,以确定要解析的IP地址的MAC地址。
- 适配器封装ARP分组,用广播地址作为帧的目的地址,将帧传输进子网中。
- 目标主机给查询主机发送回一个带有所希望映射的响应ARP分组(使用标准帧而不是广播地址),然后查询主机更新ARP表,并发送IP数据报。
默认相同子网内的设备互相知道对方MAC。可以从ip看出是否相同子网
发送数据报到子网以外
假设子网1的网络地址为111.111.111/24,子网2的网络地址为222.222.222/24。
- 发送数据报不能使用子网2适配器的MAC地址,因为子网1没有任何适配器与之匹配
- 发送主机使用ARP获得路由器接口的MAC地址,然后创建一个帧将该帧发送到子网1中
- 子网1的路由器适配器看到该链路层是向它寻址的,将这个帧传递给路由器的网络层
- 路由器通过转发表得知转发的子网2接口,并将数据报告诉子网2的适配器,该接口使用ARP获取目标MAC地址
- 子网2接口用目标MAC地址重新封装成一个新的帧发送到子网2中
这是“缺省网关地址”方式,还有“代理ARP”方式
以太网技术
- 10BASE-T
- 10BASE-2
- 100BASE-T
- 1000BASE-LX
- 10GBASE-T
其中10:10Mbps;BASE:基带以太网(媒体仅承载以太网流量);T/2/LX:物理媒体,T为双绞铜线。
| 参数 | 10Mbps | 100Mbps | 1Gbps | 10Gbps |
|---|---|---|---|---|
| 比特时间 | 100ns | 10ns | 1ns | 0.1ns |
| 冲突窗口 | 51.2μs | 5.12μs | 4.096μs | |
| 帧间间隔 | 9.6μs | 0.96μs | 0.096μs | |
| 冲突重发次数 | 16 | 16 | 16 | |
| 冲突回退限制 | 10 | 10 | 10 | |
| 阻塞帧(冲突信号) | 4字节 | 4字节 | 4字节 | |
| 最大帧长度 | 1518字节 | 1518字节 | 1518字节 | 1518字节 |
| 最小帧长度 | 64字节 | 64字节 | 416字节(载波扩展) | 64字节 |
10Gpbs使用专线,交换机间不存在多路通信,无需CSMA
链路层交换机
- 过滤(filtering):决定一个帧应该转发到某个接口还是应当将其丢弃
- 转发(forwarding):决定一个帧应该被导向哪个接口,并把该帧移动到哪些接口
- 交换机表:包含某局域网上某些主机和路由器的(不是全部)的MAC地址、通向该MAC的交换机接口、时间
假定目的地址为dd:dd:dd:dd:dd:dd,从接口 到达:
- 交换机表没有目的地址表项,此时交换机向除 以外的所有接口转发该帧的副本(广播)
- 交换机表有一个表项与接口 连接起来,执行过滤功能
- 交换机表有一个表项将接口 连接起来,该帧被转发到与接口 相连的局域网网段
自学习:
- 交换机表初始为空
- 对于每个接口收到的每个入帧,交换机存储源地址、接口、时间(雁过拔毛,A从1口发来数据,那以后发给A就走1口)
- 对于未知端口的目标MAC地址,交换机向除发送端口外的端口做广播(同一端口的收发不需要通过交换机)
- 如果在一段时间(老化期(aging time))后,交换机没有接收到该地址作为源地址的帧,就在表中删除这个地址
交换机是即插即用设备(plug-and-play device),因为他们不需要网络管理员或用户的干预。交换机也是双工的,任何交换机接口可以同时发送和接收。
交换器 v.s. 路由器:
- 交换机
- 即插即用,自学习
- 相对高的分组过滤和转发效率
- 必须处理高至第二层(链路层)的帧
- 对于广播风暴不提供任何保护措施
- 路由器
- 需要人为地配置IP地址,通过路由算法学习
- 当网络中存在冗余路径时,分组通常不会通过路由器循环
- 必须处理高至第三层(网络层)的帧
- 对第二层的广播风暴提供防火墙保护
通常路由器在交换机的上层,连接多个交换机
- 集线器 hub
- 一个口收到的信号,原封不动的发送给所有其他的口。
- 工作在物理层。
- 网桥 bridge
- 与 hub 相比,网桥会过滤 mac,只有目的mac地址匹配的数据才会发送到出口。
- 工作在链路层
- 交换机 switch
- 可以看做多个网桥的集成,但是也有三层交换机,即实现了部分路由功能的交换机
- 工作在链路层
- 路由器
- 基于 IP 做转发
- 工作在网络层
PPP 协议
Point to Point Data Link Control
- 没有多个用户,就不需要 MAC 和 MAC 地址
- 异步传输,两帧间隔随意
- 全双工、拨号都支持
- Point to Point Protocol 或 HDLC
PPP 需求
- 成帧:把网络层报文封装到链路层帧,并且能够解封装到不同的高层协议
- 比特传输:若用户数据出现了和帧头帧尾一样的数据,需要能检测出并正确传输
- 差错检测:但是不用纠错
- 链接活性:能检测链路层的故障,并向网络层通知
- 能支持网络层的协商,自动配置 IP 地址
PPP 帧格式
套用了HDLC的帧格式
- 帧头帧尾各 1 字节:都是 01111110(7e)
- 地址全 1:点到点了你要啥地址啊
- 控制字段固定:不实现差错控制
- 协议字段 1 或 2 字节:高层协议
- 用户数据
- CRC:2 或 4 字节
字节插入
为了允许用户发送 01111110,在用户发送的 01111110 前无条件插入 01111101(7d)。
为了允许用户发送 01111101,在用户发送的 01111101 前无条件插入 01111101(7d)。
接收方看到一个 7d,就把其看作转义字符,而其后的是用户数据。
获取网页
N2是一台新机器,具有本机IP地址和MAC地址。如果在浏览器中打开 http://www.sciroccogti.top/ ,则该命令会用到哪些应用层、传输层、网际层协议,描述浏览器获取信息过程?
- N2通过ARP查询获取默认网关MAC地址;用到网际层协议:ARP协议
- N2通过DNS获取 http://www.sciroccogti.top/ 的IP地址;用到应用层协议:DNS协议、OSPF、BGP;传输层协议:UDP;网际层协议:IP;
- N2与 http://www.sciroccogti.top/ 建立TCP连接;用到传输层协议:TCP;网际层协议:IP;
- N2通过HTTP获取web网页;用到应用层协议:HTTP,传输层协议:TCP,网际层协议:IP;
第一章 - 计算机网络和因特网
1.1 什么是因特网
- 描述因特网的具体构成,包括基本硬件和软件组件
- 根据为分布式应用提供服务的联网基础设施来描述因特网
具体构成描述
- 所有联网设备称为主机(host)、端系统(end system)
- 端系统通过通信链路(communication link)和分组交换机(packet switch)连接到一起
- 链路的传输速率(transmission rate)以比特/秒(bps)度量
- 分组交换机主要包括路由器(router)和链路层交换机(link-layer switch)
- 从发送端系统到接收端系统,一个分组所经历的一系列通信链路和分组交换机成为通过该网络的路径(route/path)
- 端系统通过因特网服务提供商(ISP)接入因特网
- 端系统、分组交换机和其他部件都要运行一系列协议(protocol),TCP(传输控制协议)和IP(网际协议)是两个最为主要的协议
- 因特网标准由因特网工程任务组(IETF)研发,其标准文档称为请求评论(RFC)
服务描述
- 分布式应用程序(distributed application)
- 与因特网相连的端系统提供了一个套接字接口(socket interface),该接口规定了运行在一个端系统上的程序请求因特网基础设施向运行在另一个端系统上的特定目的地程序交付数据的方式
1.2 网络边缘
- 主机有时又被进一步划分为两类:客户端(client)和服务器(server)
- 大部分服务器属于数据中心(data center)
接入网
接入网:将端系统物理连接到其边缘路由器(edge router)的网络。
- 家庭接入
- 数字用户线(Digital Subscriber Line, DSL)(非对称)
- 电缆(cable)
- 光纤到户(Fiber To The Home, FTTH),分为主动光纤网络(AON)和被动光纤网络(PON)
- 拨号与卫星
- 企业接入
- 以太网
- WiFi
- 广域无线接入
- 3G、4G/LTE、5G……
物理媒体
对于每个发射器-接收器对,通过跨越一种物理媒体传播电磁波或光脉冲来发送比特。
物理媒体分为两种类型:导引型媒体和非导引型媒体。
- 双绞铜线
- 同轴电缆
- 光纤
- 陆地无线电信道
- 卫星无线电信道
1.3 网络核心
分组交换
-
端系统彼此交换报文(message)
-
分组交换机(路由器、链路层交换器)
-
存储转发传输:必须接收到整个分组,然后才能进行输出。 通过由 N 条速率均为 R 的链路组成的路径(N-1 台路由器),端到端时延是
-
排队时延:链路正忙于传输其他分组时,该到达分组必须在输出缓存中等待。
-
分组丢失(丢包):缓存已被其他等待传输的分组充满,必须将当前分组或正在排队的一个分组丢弃。
-
转发表:将目的地址(或目的地址的一部分)映射成为输出链路。
-
路由选择协议:自动地设置转发表。
电路交换
当两台主机要通信时,该网络在两台主机之间建立一条专用的端到端连接(end-to-end connection)。
- 复用:通过频分复用(FDM)、时分复用(TDM)实现电路。
- 静默期(silent period)利用率不够高。
网络的网络
- ISP、客户、提供商
- 区域ISP、第一层ISP(tier-1 ISP)
- 存在点、多宿(multi-home)、对等(peer)、因特网交换点(IXP)
- 内容提供商网络(content provider network)
1.4 分组交换网中的时延、丢包和吞吐量
- 节点处理时延
- 排队时延
- 传输时延(transmission delay):传输到链路上,
- 传播时延(propagation delay):链路上的传播,
累加起来得到节点总时延。
排队时延和丢包
令aaa表示分组到达队列的平均速率(pkt/s),比率 被称为流量强度(traffic intensity)。要求 小于1。
端到端时延
- traceroute
- 有意地延迟传输:分组化时延
吞吐量
在任何时间的瞬时吞吐量(instantaneous throughput)是主机接收到一个文件的速率(bps)。如果文件由FFF比特组成,主机接收到所有比特用去 秒,则文件传送的平均吞吐量(average throughput)是 bps。
- 瓶颈链路
- 干扰流量
1.5 协议层次和服务类型
协议栈
- 应用层:HTTP、SMTP、FTP……
- 运输层:TCP、UDP
- 网络层:IP
- 链路层
- 物理层
OSI参考模型额外包括表示层和会话层。
封装
- 封装(encapsulation)
- 报文、数据报、链路层帧(frame)、有效载荷字段(payload field)
1.6 面对攻击的网络
- 恶意软件(malware)、僵尸网络、病毒、蠕虫
- 拒绝服务攻击(DoS)
- 弱点攻击
- 带宽泛洪
- 连接泛洪
- 分组嗅探器
- IP哄骗(IP spoofing)
Chapter 3 - Transport Layer
3.1 Introduction and Transport-Layer Services
A transport-layer protocol provides for logical communication between application processes running on different hosts.
Transport-layer protocols are implemented in the end systems but not in network routers. On the sending side, the transport layer converts the application-layer messages into transport-layer packets, known as transport-layer segments. The transport layer then passes the segment to the network layer at the sending end system. On the receiving side, the network layer extracts the transport-layer segment and passes the segment up to the transport layer. The transport layer then processes the received segment, making the data available to the receiving application.
3.1.1 Relationship Between Transport and Network Layers
A transport-layer protocol provides logical communication between processes running on different hosts, a network-layer protocol provides logical-communication between hosts.
Certain services can be offered by a transport protocol even when the underlying network protocol doesn’t offer the corresponding service at the network layer.
3.1.2 Overview of the Transport Layer in the Internet
Two transport-layer protocols: TCP and UDP.
The most fundamental responsibility of UDP and TCP is to extend IP’s delivery service between two end systems to a delivery between two processes running on the end systems. Extending host-to-host delivery to process-to-process delivery is called transport-layer multiplexing and demultiplexing. UDP and TCP also provide integrity checking by including error-detection fields in segments’ headers.
TCP offers several additional services:
- reliable data transfer
- congestion control
3.2 Multiplexing and Demultiplexing
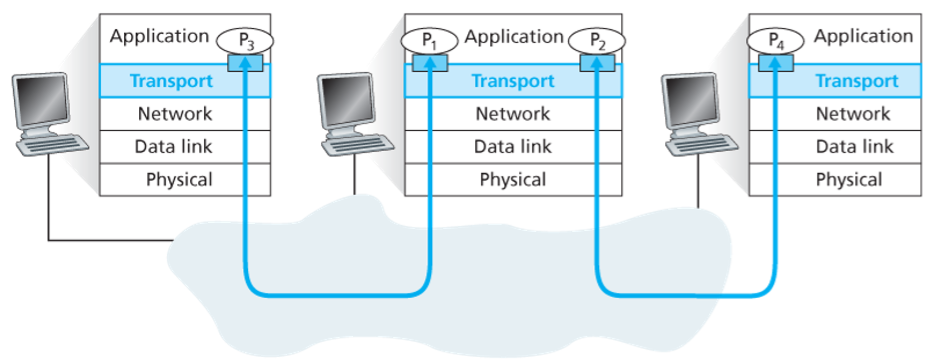
At the receiving end, the transport layer examines the fields to identify the receiving socket and then directs the segment to that socket. The job of delivering the data in a transport-layer segment to the correct socket is called demultiplexing.
The job of gathering data chunks at the source host from different sockets, encapsulating each data chunk with header information to create segments and passing the segments to the network layer is called multiplexing.
Transport-layer multiplexing requires (1) that sockets have unique identifiers, and (2) that each segment have special fields that indicate the socket to which the segment is to be delivered. These special fields are the source port number field and the destination port number field. Each port number is a 16-bit number from 0 to 65535. The port numbers from 0 to 1023 are called well-known port numbers and are restricted.
Each socket in the host could be assigned a port number, and when a segment arrives at the host, the transport layer examines the destination port number in the segment and directs the segment to the corresponding socket. The segment’s data then passes through the socket into the attached process.
UDP sockets are connectionless: socket is fully identified by a two-tuple consisting of a destination IP address and a destination port number. If two UDP segments have different source IP addresses and/or source port numbers, but have the same destination IP and port number, two segments will be directed to the same destination process via the same destination socket.
TCP sockets are connection-oriented: socket is identified by a four-tuple (source IP + port, destination IP + port). Two arriving TCP segments with different IP address/port will be directed to two different sockets.
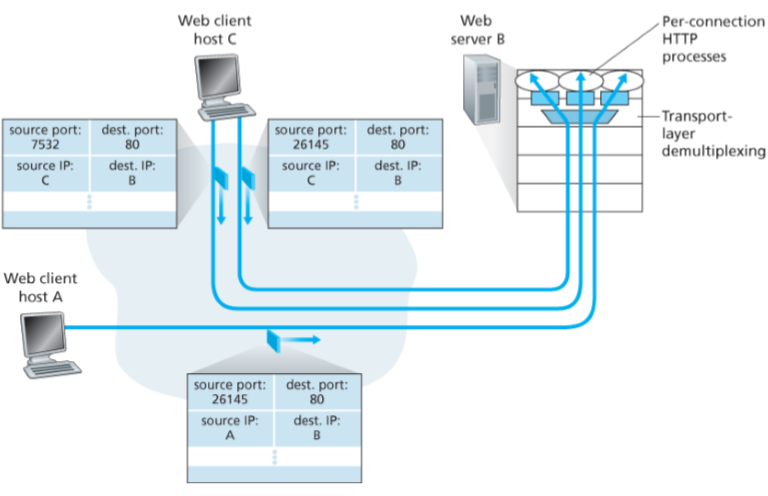
The server host may support many simultaneous TCP connection sockets, with each socket attached to a process and with each socket identified by its own four-tuple. When a TCP segment arrives at the host, all four fields are used to direct the segment to the appropriate socket.
3.3 Connectionless Transport: UDP
UDP does just about as little as a transport protocol can do. In fact, if the application developer chooses UDP instead of TCP, then the application is almost directly talking with IP. With UDP there is no handshaking between sending and receiving transport-layer entities before sending a segment. Therefore UDP is said to be connectionless.
Some applications are better suited for UDP for some reasons:
- Finer application-level control over what data is sent and when. UDP will package the data and immediately pass the segment to the network layer. While TCP has a congestion control mechanism that throttles the transport-layer TCP sender when one or more links become congested. TCP will also continue to resend a segment until the receipt has been acknowledged, which is not well matched to some applications needs (can tolerate some data loss).
- No connection establishment. UDP does not introduce any delay to establish a connection.
- No connection state. No buffers, congestion-control parameters and sequence and acknowledgement number parameters. A server devoted to a particular application can typically support many more active clients when the application runs over UDP.
- Small packet header overhead. UDP has only 8 bytes of overhead (TCP = 20 bytes).
It is possible for an application to have reliable data transfer when using UDP. This can be done if reliablity is built into the application itself.
3.3.1 UDP Segment Structure

3.3.2 UDP Checksum
UDP performs the 1s complement of the sum of all the 16-bit words in the segment, with any overflow encountered during the sum being wrapped around. The result is put in the checksum field of the UDP segment.
Although UDP provides error checking, it does not do anything to recover from an error. Some implementations of UDP simply discard the damaged segment; others pass the damaged segment to the application with a warning.
3.4 Principles of Reliable Data Transfer
3.4.1 Building a Reliable Data Transfer Protocol
Over a Perfectly Reliable Channel
- Nothing can go wrong
- Sender simply accepts data from upper layer, creates a packet and sends it into the channel;
- Receiver receives a packet, removes the data from the packet and passes the data up to the upper layer.
Over a Channel with Bit Errors
Assume the channel only has bit errors, and will NOT lose packets.
- Positive acknowledgements and negative acknowledgements
- ARQ (Automatic Repeat reQuest) protocols
Three capabilties are required in ARQ protocols to handle errors:
- Error detection.
- Receiver feedback.
- Retransmission.
The stop-and-wait protocols:
- The sender sends the data with a packet checksum and then waits for an ACK or NAK packet from the receiver. If ACK is received, then the packet has been received correctly and the sender waits for next data. Otherwise, the protocol retransmits the last packet and repeat. When the sender is waiting for ACK or NAK, it cannot get more data from the upper layer.
- The receiver just replies with either an ACK or a NAK when the packet arrives.
The problem in the above method is that if an ACK or NAK is corrupted, the sender has no way of knowing whether or not the receiver has correctly received the last data.
A simple solution is to add a new field to the data packet and have the sender number its data packets by putting a sequence number into this field. The receiver then need only check this sequence number to determine whether or not the received packet is a retransmission. For stop-and-wait protocol, a 1-bit sequence number will suffice.
Over a Lossy Channel with Bit Errors
Suppose that the sender transmits a data and either the data or ACK is lot (no reply from receiver). If the sender is willing to wait long enough so that it is certain that a packet has been lost, it can simply retransmit the data packet.
If a packet experiences a particulary large delay, the sender may retransmit the packet even though neither the packet nor its ACK have been lost. This introduces the possibility of duplicate data packets.
Implementing a time-based retransmission mechanism requires a countdown timer that can interrupt the sender after a given amount of time has expired. The sender will thus need to be able to (1) start the timer each time a packet is sent, (2) respond to a timer interrupt and (3) stop the timer.
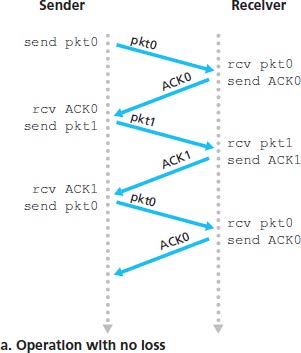
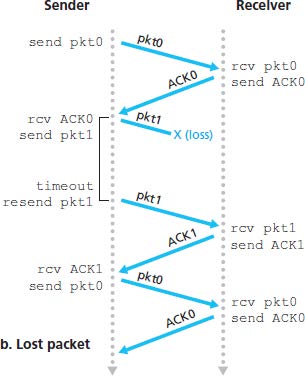
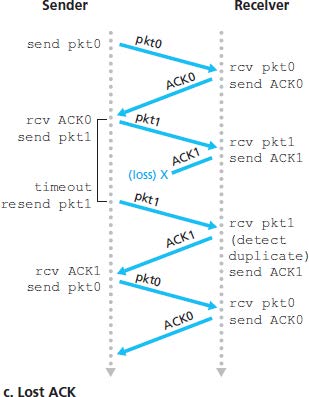
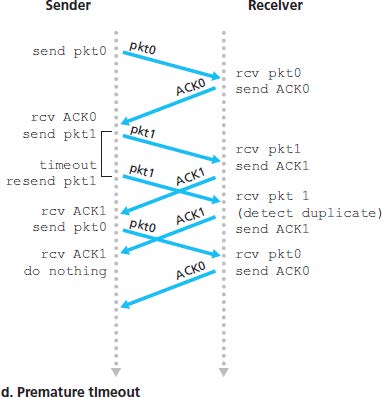
3.4.2 Pipelined Reliable Data Transfer Protocols
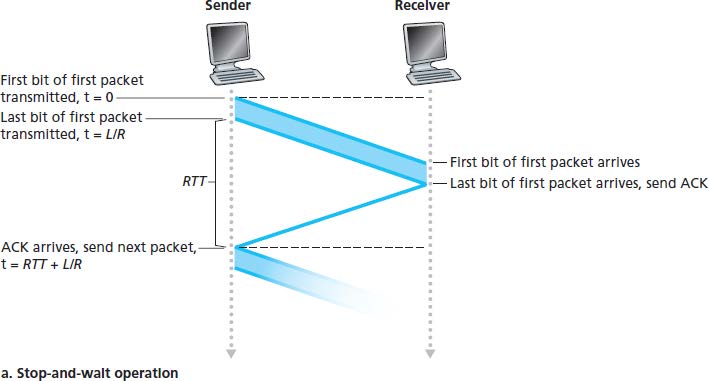
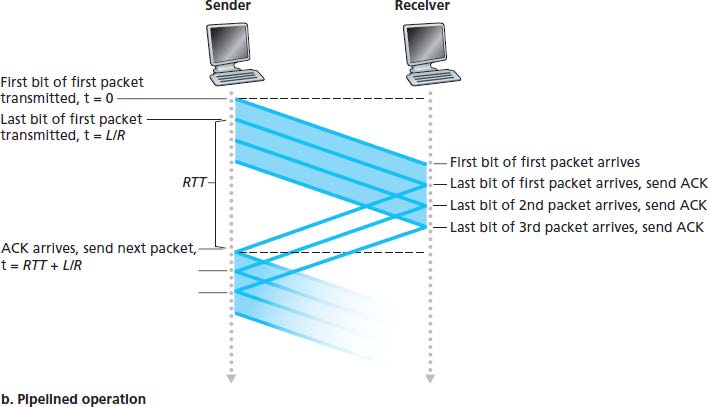
Pipelining has the following consequences for reliable data transfer protocols:
- The range of sequence numbers must be increased.
- The sender and receiver sides of protocols may have to buffer more than one packets.
- The range of sequence numbers needed and the buffering requirements will depend on the manner in which a data transfer protocol responds to lost, corrupted and overly delayed packets.
Two basic approaches: Go-Back-N and selective repeat.
3.4.3 Go-Back-N (GBN)

In GBN, the sender is allowed to transmit multiple packets without waiting for an acknowledgement, but is constrained to have no more than some maximum allowable number NNN of unacknowledged packets in the pipeline.
NNN is refereed to as the window size and the GBN protocol is a sliding-window protocol. If kkk is the number of bits in the packet sequence number field, the range of sequence numbers is thus .
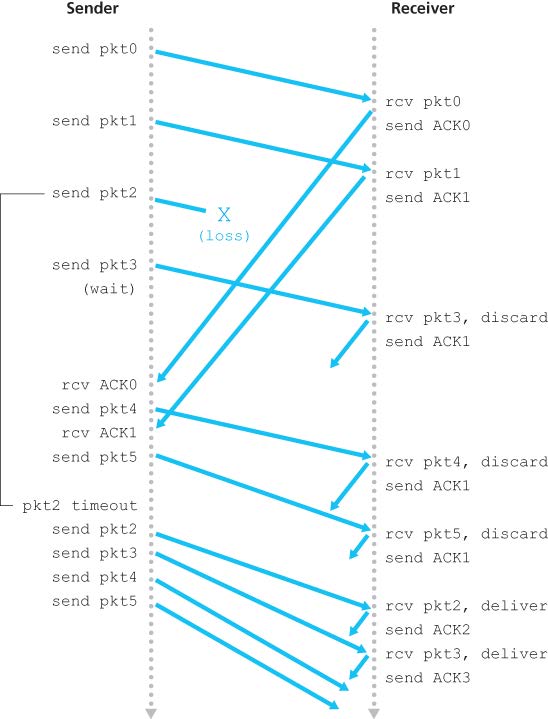
The GBN sender must respond to three types of events:
- Invocation from above. When the above layer sends some data, the sender first checks to see if the window is full. If the window is not full, a packet is created and sent and the sender updates the variables; otherwise the sender would either buffer this data, or have a synchronization mechanism (a semaphore or a flag) that would allow the upper layer to send data only when window is not full.
- Receipt of an ACK. An acknowledgement for a packet with sequence number nnn will be taken to be a cumulative acknowledgement, indicating that all packets before nnn have been correctly received.
- A timeout event. If timeout occurs, the sender resends all packets that have been previously sent but not yet acknowledged.
The receiver’s action is simple: if a packet with sequence number nnn is received correctly and is in order, the receiver sends an ACK for packet nnn and pass the data to upper layer. (The receiver discards out-of-order packets for simplicity of receiver buffering, but may need more retransmissions.) In all other cases, the receiver discards the packet and resends an ACK for the most recently received in-order packet.
3.4.4 Selective Repeat (SR)
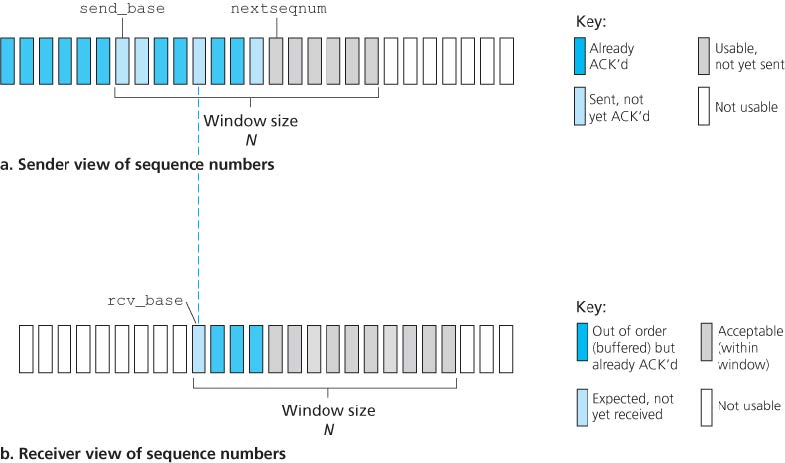
Retransmission will require that the receiver indicidually acknowledge correctly received packets. The SR receiver will acknowledge a correctly received packet whether or not it is in order. Out-of-order packets are buffered until any missing packets are received.
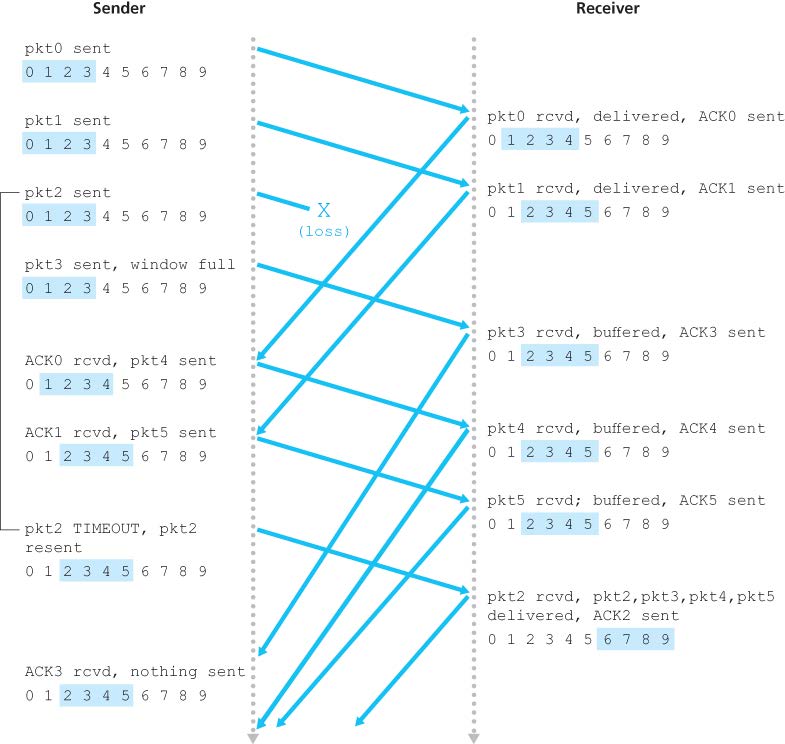
Problem of SR with a too large window: a packet can be new data or a retransmission (an example with window size = 4):
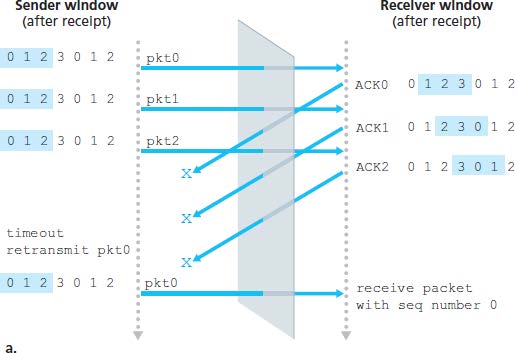
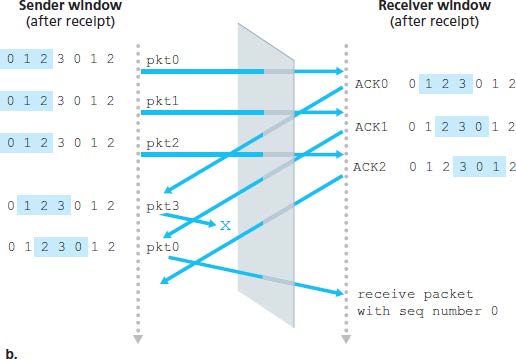
Window size of SR must be less than or equal to half the size of the sequence number space. (.
3.5 Connection-Oriented Transport: TCP
3.5.1 The TCP Connection
TCP is connection-oriented because two processes must first handshake with each other before one process can send data to another. As part of TCP connection establishment, both sides of the connection will initialize many TCP state variables associated with the TCP connection.
A TCP connection provides a full-duplex service: if there is a TCP connection between process AAA and process BBB on another host, then application-layer data can flow from AAA to BBB at the same time as application-layer data flows from BBB to AAA.
A TCP connection is also always point-to-point between a single sender and a single receiver. Multicasting (one to many) is not possible with TCP.
When establishing a TCP connection, the client first sends a special TCP segment; the server responds with a second special TCP segment; and finally the client responds again with a third special segment. The first two segments carry no payload; the third of these segments may carry a payload. This connection-establishment procedure is often referred to as a three-way handshake.
Once a TCP connection is established, the two application processes can send data to each other. Once the data passes through the socket, the data is in the hands of TCP running in the client and TCP redirects this data to the connection’s send buffer. From time to time, TCP will grab chunks of data from the send buffer and pass the data to the network layer.
The maximum amount of data that can be grabbed and placed in a segment is limited by the maximum segment size (MSS). The MSS is typically set by first determining the length of the largest link-layer frame that can be sent by the local sending host (maximum transmission unit (MTU)) and then setting the MSS to ensure that a TCP segment plus the TCP/IP header length (40 bytes) will fit into a single link-layer frame. Both Ethernet and PPP link-layer protocols have an MTU of 1500 bytes, thus a typical value of MSS is 1460 bytes.
MSS is the maxium amount application-layer data in the segment, not the maximum size of the TCP segment including headers. (While MTU includes all headers.)
3.5.2 TCP Segment Structure

TCP header is 20 bytes long.
- The 32-bit sequence number field and 32-bit acknowledgement nmber field are used by sender and receiver in implementing a reliable data transfer service.
- The 16-bit receive window is used for flow control, indicating the number of bytes that a receiver is willing to accept.
- The 4-bit header length field specified the length of the TCP header (including options field, which is typically empty thus the length is 20 bytes).
- The flag field contains 8 bits.
- The ACK bit is used to indicate that the value carried in the acknowledgement filed is valid.
- The RST, SYN, FIN bits are used for connection setup and teardown.
- The CWR and ECE are used in explicit congestion notification.
- Setting the PSH bit indicates that the receiver should pass the data to the upper layer immediately.
- The URG bit is used to indicate that there is data in this segment that the sending-side upper-layer entity has markes as urgent. The location of the last byte of this urgent data is indicated by the 16-bit urgent data pointer field. TCP must inform the receiving-side upper-layer entity when urgent data exists and pass it a pointer to the end of the urgent data.
Sequence Numbers and Acknowledgement Numbers
TCP views data as an unstructured, but ordered, stream of bytes. TCP’s use of sequence numbers reflects this view in that sequence numbers are over the stream of transmitted bytes and not over the series of transmitted segments. The sequence number for a segment is therefore the byte-stream number of the first byte in the segment. (序列号是当前字节在文件中的偏移量)
The acknowledgment number that Host A puts in its segment is the sequence number of the next byte Host A is expecting from Host B. (确认号是希望收到的下一个字节的偏移量)
Suppose that Host A has received all bytes numbered 0 through 535 from B and suppose that it is about to send a segment to Host B. Host A is waiting for byte 536 and all the subsequent bytes in Host B’s data stream. So Host A puts 536 in the acknowledgment number field of the segment it sends to B.
As another example, suppose that Host A has received one segment from Host B containing bytes 0 through 535 and another segment containing bytes 900 through 1,000. For some reason Host A has not yet received bytes 536 through 899. In this example, Host A is still waiting for byte 536 (and beyond) in order to re-create B’s data stream. Thus, A’s next segment to B will contain 536 in the acknowledgment number field. Because TCP only acknowledges bytes up to the first missing byte in the stream, TCP is said to provide cumulative acknowledgments.

Note that the acknowledgment for client-to-server data is carried in a segment carrying server-to-client data; this acknowledgment is said to be piggybacked (捎带) on the server-to-client data segment.
3.5.3 Round-Trip Time Estimation and Timeout
(几个RTT测算公式)
3.5.4 Reliable Data Transfer
- 发送数据,启动计时器
- 超时重发,重启计时器
- 收到ACK,更新确认计数器
三种丢包重传的情况:(注意图二中只重传第一个没有确认的包,后面的不会重传)
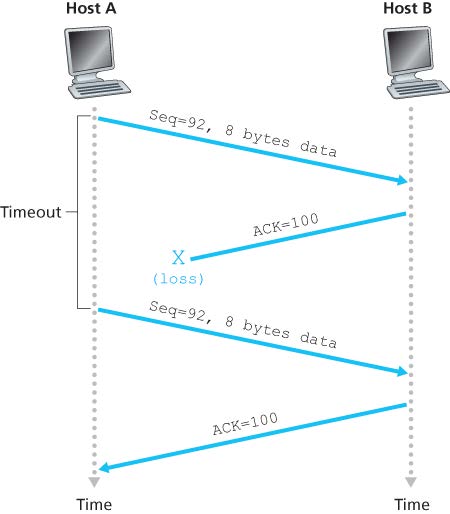
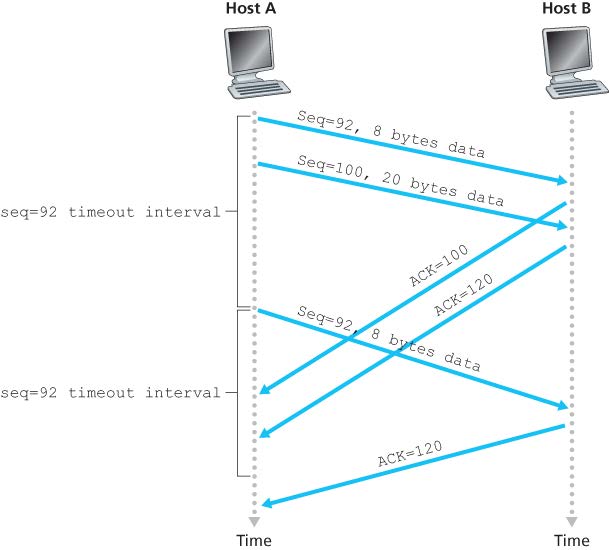
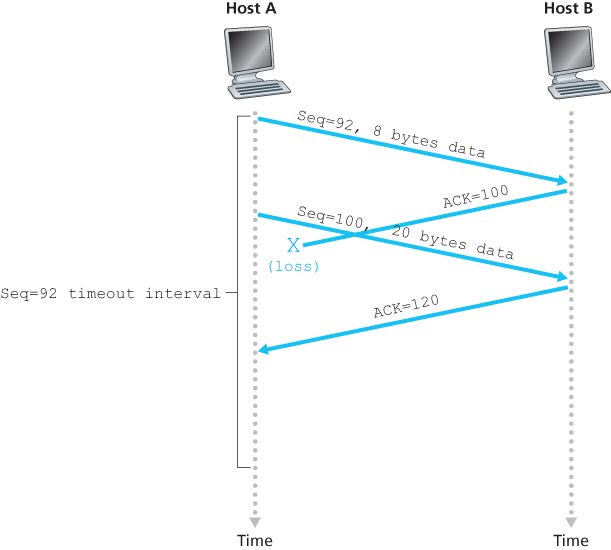
TCP Fast Retransmit (by detecting duplicate ACK -> packet loss)
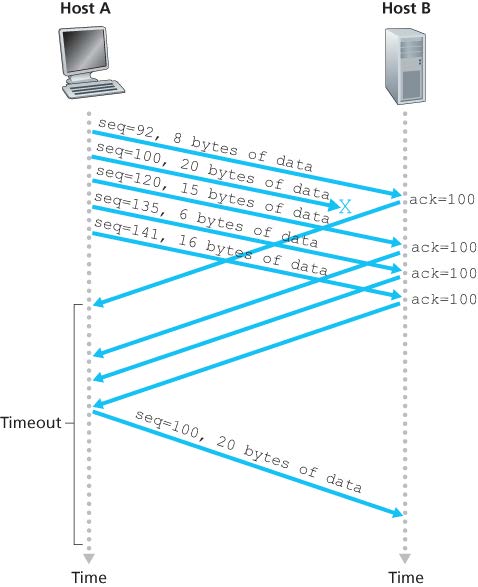
3.5.5 Flow Control

TCP provides flow control by having the sender maintain a receive window (rwnd). By keeping the amount of unacknowledged data less than the value of rwnd , Host A is assured that it is not overflowing the receive buffer at Host B.
3.5.6 TCP Connection Management

Connection establishment:
- Step 1: the client sends a TCP segment with SYN bit set to 1 (TCP SYN segment) to server. The segment contains a random initial sequence number.
- Step 2: the server allocates buffers and variables to the connection, and sends a connection-granted segment (SYNACK segment) to the client. The SYN bit is set to 1 and ACK number is set to client’s initial sequence number + 1. Server also chooses a random initial sequence number.
- Step 3: the client also allocates buffers and variables to the connection. Then sends another segment with SYN bit set to 0 and ACK number to server’s sequence number + 1. This segment may carry client-to-server data in payload.
Connection closement:
- Step 1: the client sends a segment with FIN bit set to 1.
- Step 2: the server sends an acknowledgement segment, and then sends its own shutdown segment with FIN bit set to 1.
- Step 3: the client acknowledges the server’s shutdown segment. And then it waits for 30 seconds before releasing resources (in case that ACK is lost).
- Step 4: the server receives ACK and releases all resources.
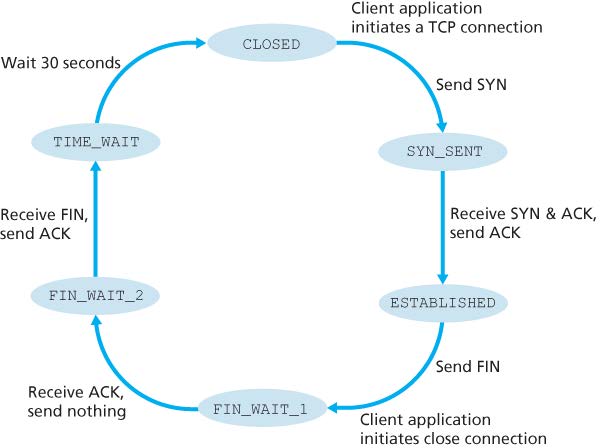
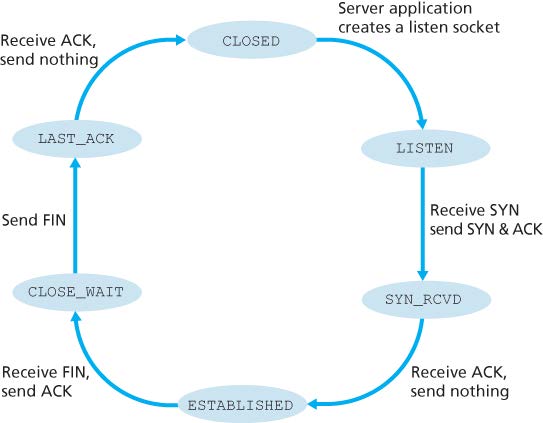
Port scanning: sending a TCP SYN segment
- Receives a TCP SYNACK segment: port is open
- Receives a TCP RST segment: port is not used
- Receives nothing: blocked by firewall or something else
SYN flood attack (DoS attack): send a large number of TCP SYN segments, but not completing the third handshaking step, exhausting the resources of the server.
3.6 Principles of Congestion Control
- 端到端拥塞控制
- 网络辅助的拥塞控制
3.7 TCP Congestion Control
加性增加,乘性减少


TCP congestion-control algorithm: (cwnd = congestion window, ssthresh = slow start threshold)
- slow start:(指数)
- 初始状态或出现超时时将发送窗口长度设置为1,此后每收到一个ACK则窗口长度+1(也就是每一轮之后翻倍)
- 若窗口大小达到慢启动阈值则进入拥塞避免
窗口1+1=2后,发送的数据数也变为2,于是会收到2个ACK,则该RTT下窗口长度2+2=4,实现指数增长
- congestion avoidance:(线性)
- 收到新ACK时 cwnd = cwnd + MSS/cwnd
MSS:最大报文段长度
- fast recovery:(三个重复ACK时进入,以窗口锐减为开始)
- 每收到一个重复的ACK则恢复1个发送窗口长度(指数)
- 收到了新的ACK则恢复拥塞避免
- 若超时则进入慢启动状态,阈值设为窗口的一半,窗口设为1
- Tahoe:有重复三个 ACK 时将窗口设置为1(旧版)
- Reno:有重复三个 ACK 时将阈值减半,窗口为阈值+3MSS(常用)
TCP 平均吞吐率:3 / 4 W,W 为拥塞窗口大小
TCP 公平性:

从 A 开始,到 B 时丢包,减半至 C(C 为 B 与原点的中点),如此反复不断逼近最优点
-->Chapter 4 - The Network Layer: Data Plane
4.1 Overview of Network Layer
4.1.1 Forwarding and Routing: The Data and Control Planes
Primary role of the network layer: to move packets from a sending host to a receiving host.
Two important network-layer functions to move packets:
- Forwarding (switching): when a packet arrives at a router’s input link, the router must move the packet to the appropriate output link. A packet might also be blocked from exiting a router, or might be duplicated and sent over multiple outgoing links.
- Routing: determine the route or path taken by packets as they flow from a sender to a receiver using routing algorithms.
Forwarding refers to the router-local action of transferring a packet from input link to output link, takes place at very short timescales, thus is typically implemented in hardware.
Routing refers to the network-wide process that determines the end-to-end paths that packets take, takes place on much longer timescales and often implemented in software.
Forwarding table: a router forwards a packet by examining the value of one or more fields in the arriving packet’s header, then using these header values to index into its forwarding table. The value in the forwarding table entry for thoes values indicates the outgoing link interface at that router to which the packet is to be forwarded.
Control Plane: The Traditional Approach
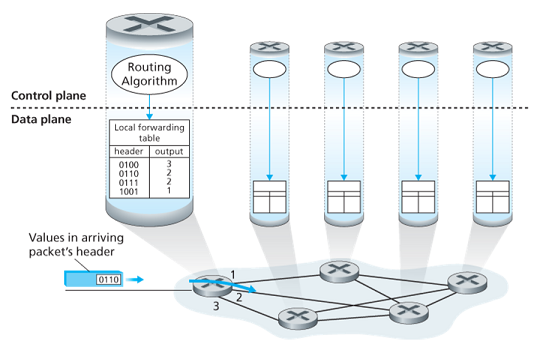
A routing algorithm runs in each and every router and both forwarding and routing function are contained within a router. The algorithm communicates with the routing algorithm in other routers to compute the values of its forwarding table.
The forwarding and routing functions can be configured directly by human network operators, and no routing protocols would be required.
Control Plane: The SDN Approach
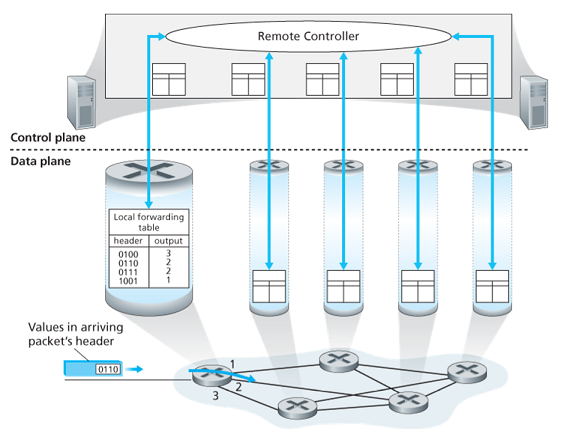
A physically separate (from the routers) remove controller computes and distributes the forwarding tables to be used by each and every router. The routing device performs forwarding only while the remote controller computes and distributes forwarding tables.
This control-plane approach is at the heart of software-defined networking (SDN), where network is software-defined because the controller that computes the tables and interacts with routers is implemented in software.
4.1.2 Network Service Model
The network service model defines the characteristics of end-to-end delivery of packets between sending and receiving hosts.
- Guaranteed delivery: guarantees that a packets sent by a source host will eventually arrive at the destination host.
- Guaranteed delivery with bounded delay: delivery within a host-to-host delay bound.
- In-order packet delivery: packets arrive in the order they were sent.
- Guaranteed minimal bandwidth: as long as the sending host transmits bits at a rate below the limit, all packets are eventually delivered to the destination host.
- Security: encrypt all datagrams at the source and decrypt them at the destination.
- Et cetera.
The Internet’s network layer provides a single service, known as best-effort service. Packets are neither guaranteed to be received in order nor is their eventual delivery even guaranteed. There is no guarantee on delay not there is a minimal bandwidth guarantee. (best-effort service = no service at all)
4.2 Virtual Circuit and Datagram Network
Virtual Circuit is a computer network that provides connectionless service, and Datagram Network is one provides connectivity service.
4.2.1 Virtual Circuit
Virtual-Circuit is used in ATM, which is dumped:)
The VC number of the packet might be changed. Why not keep the VC number as same? Cause that needs a rearrangement through the whole network.
4.2.2 Datagram Network
The address of the destination end system is stamped onto the packet in a datagram network.
虚电路:预先建立好路线;数据报:每个报文单独走
longest prefix matching 最长前缀匹配
| Prefix Match | Link Interface |
|---|---|
| 11001000 00010111 00010*** ******** | 0 |
| 11001000 00010111 00011000 ******** | 1 |
| 11001000 00010111 00011*** ******** | 2 |
| otherwise | 3 |
Ex:11001000 00010111 00011000 00011000 10101010 -> 1
一般而言,路由器仅需将部分地址转发至内网,其它的统统指向外网即可,于是不用记忆四十亿地址
4.3 What’s Inside a Router?
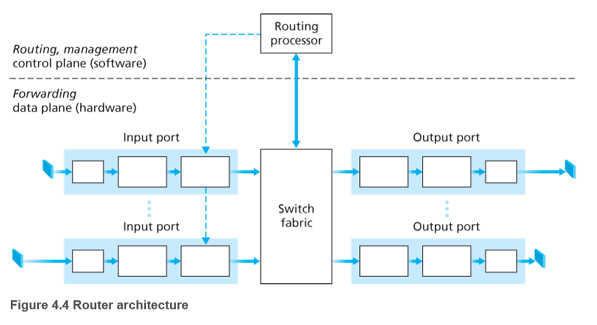
- Input ports
- Performs the physical layer function of terminating an incoming physical link at a router.
- Performs link-layer functions needed to interoperate with the link layer at the other side of the incoming link.
- Most crucially, a lookup function is also performed at the input port. Here the forwarding table is consulted to determine the router output to which the packet should be forwarded via the switching fabric. Control packets are forwarded from input port to the routing processor.
- Switching fabric: connects the router’s input ports to its output ports.
- Output ports: stores packets received from the switching fabric and transmits these packets on the outgoing link by performing the necessary link-layer and physical-layer functions.
- Routing processor: performs control-plane functions.
- In traditional routers, it executes the routing protocols, maintains routing tables and attached link state information, and computes the forwarding table for the router.
- In SDN routers, the routing processor is responsible for communicating with the remote controller in order to receive forwarding table entries and install these entries in input ports.
Input ports, output ports and switching fabric are almost always implemented in hardware. The control plane functions are usually implemented in software and execute on the routing processor.
4.3.1 Input Port Processing and Destination-Based Forwarding
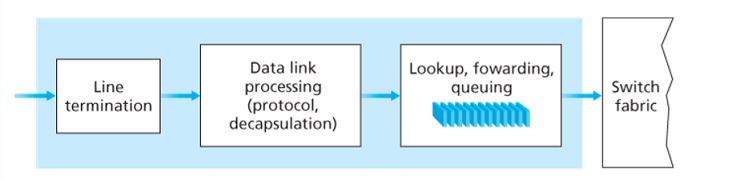
The router matches a prefix of the packet’s destination address with the entries in the table. When there are multiple matches, the router uses the longest prefix matching rule.
Once the output port has been determined, the packet can be sent into the switching fabric. In some designs, a packet may be temporarily blocked from entering the switching fabric if packets from other input ports are currently using the fabric. A blocked packet will be queued at the input port and then scheduled to cross the fabric at a later point.
Other important actions:
- physical and link-layer processing
- version number, checksum and time-to-live field must be checked and the latter two fields rewritten
- counters used for network management must be updated
| Line termination | Data link processing | Lookup, fowarding, queuing |
|---|---|---|
| 物理层 | 链路层 | --- |
4.3.2 Switching
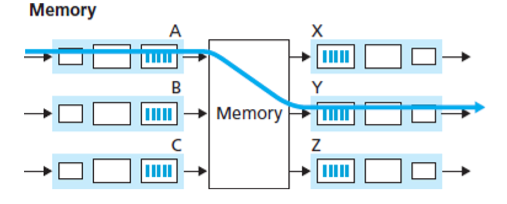
Switching via memory: simplest, earliest method, where input and output ports functioned as traditional I/O devices in a traditional operating system. If memory bandwidth allows a maximum of packets per second to be written into or read from memory, then the overall forwarding throughput must be less then . Two packets cannot be forwarded at the same time.(受限于内存速度)
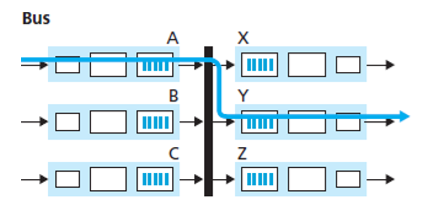
Switching via a bus: an input port transfers a packet directly to the output port over a shared bus, without intervention by the routing processor. This is typically done by having the input port pre-pend a switch a switch-internal label (header) to the packet indicating the local output port. All output port receive the packet, but only the port that matches the label will keep the packet. The label is then removed at the output port. Only one packet can cross the bus at a time.(受限于总线带宽)
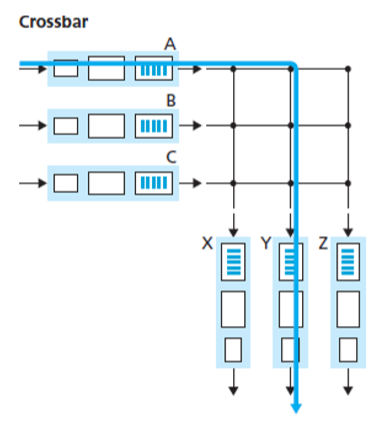
Switching via an interconnection network: A crossbar switch is an interconnection network consisting of buses that connect input ports to output ports. Crossbar switches are capable of forwardning multiple packets in parallel, which is non-blocking (not blocked as long as no other packet is being forwarded to the same output port).
4.3.3 Output Port Processing
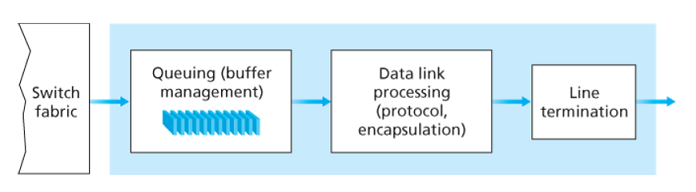
Output port takes packets from output port’s memory and transmits them over the output link. This includes selecting and de-queueing packets for transmission, and performing the needed link-layer and physical-layer transmission functions.
4.3.4 Where Does Queuing Occur?
Suppose input and output line speeds (transmission rates) all have an identical transmission rate of packets per seconds, and there are NNN input ports and NNN output ports.
All packets have the same fixed length and arrive to input ports in a synchronous manner (the time to send a packet on any link is equal to the time to receive a packet on any link, during this interval, either zero or one packets can arrive on an input link).
Define as the rate at which packets can be moved from input port to output port. If is times faster than , then only negligible queueing will occur at the input ports. (In the worst case input lines are receiving packets and all packets are to be forwarded to the same output port, each batch of packets can be cleared before the next batch arrives.)
Input Queueing
If switch fabric is not fast enough, packet queuing can also occur at the input ports as packets must join input port queues to wait their turn to cross the fabric.
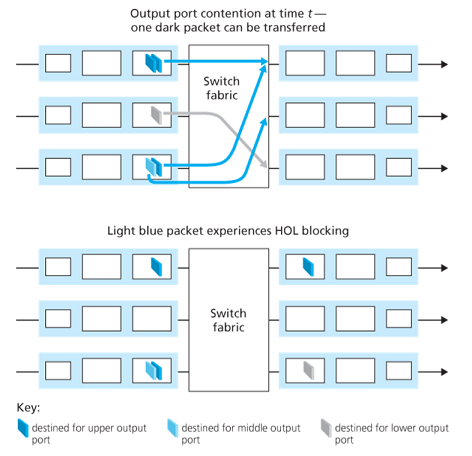
Head-of-the-line (HOL) blocking is a queued packet in an input queue must wait for transfer through the fabric (even though its output port is free) because it is blocked by another packet at the head of the line.
Output Queueing

When the output port cannot transmit all packets, the rest packets must be queued. The number of queued packets can grow large enough to exhaust available memory at the output port.
When there is no enough memory to buffer, a decision must be made to either drop the arriving packet (drop-tail) or remove one or more already-ququed packets to make room for new packet.
recommended buffer size with N flows:
4.3.5 Packet Scheduling
First-In-First-Out (FIFO)
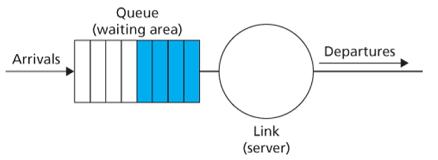
Also known as first-come-first served (FCFS), the output port delects packets for link transmission in the same order in which they arrived at the output link queue.
Priority Queueing

The priority queuing discipline will transmit a packet from the highest priority class that has a nonempty queue. The choice among packets in the same priority class is typically done in a FIFO manner.
Round Robin and Weighted Fair Queueing (WFQ)
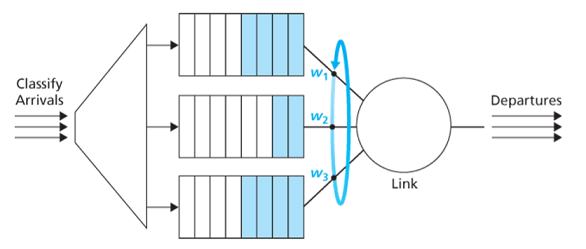
A round robin scheduler alternates service among priority classes. The work-conserving queuing discipline will never allow the link to remain idle whenever there are packets queued. A work-conversing round robin discipline looks for a packet of a given class but finds none will immediately check the next class in the round robin sequence.
WFQ differs from RR that each class may receive a differential amount of service in any interval of time. (partition of service equals to wi/∑wjw_i/\sum w_jwi/∑wj where wiw_iwi is the weight of class iii.)
4.4 The Internet Protocol (IP)
4.4.1 IPv4 Datagram Format

- Version number: IP protocol version of datagram.
- Header length: determine where in the IP datagram the payload actually begins (typical IP datagram has a 20-byte header).
- Type of service (TOS): allow different types of IP datagrams to be distinguished from each other.(告诉路由器该数据需要时间敏感或是可靠敏感)
- Datagram length: total length of IP datagram (header plus data), measured in bytes.
- Identifier, flags, fragmentation offset: related to fragmentation (IPv6 does not allow for fragmentation)
- Time-to-live (TTL): ensure that datagrams do not circulate forever in the network. This field is decremented by one each time the datagram is processed by a router. If TTL reaches 0, a router must drop that datagram.
- Protocol: used only when an datagram reaches its final destination. (6=TCP, 17=UDP) The protocol number is the glue that binds the network and transport layers together, whereas the port number is the glue that binds the transport and application layers together.
- Header checksum
- Source and destination IP addresses
- Options
- Data (payload)
头:
- TCP:20 字节(不含option)
- IP:20 字节(不含 option)
4.4.2 IPv4 Datagram Fragmentation
分片可能在任一个节点进行,还可能出现多次分片
The maximum amout of data that a link-layer frame can carry is called the maximum transmission unit (MTU).(硬件限制)
Because each IP datagram is encapsulated within the link-layer frame for transport from one router to the next router, the MTU of the link-layer protocol places a hard limit on the length of an IP datagram.

When a destination host receives a series of datagrams from the same source, it needs to determine whether any of these datagrams are fragments of some original, larger datagram. If some datagram are fragments, it must further determine when it has received the last fragment and how the fragments should be pieced back together. IPv4 put identification, flag and fragmentation offsets in the IP datagram header.
The sending host increments the identification number for each datagram it sends. When a router needs to fragment a datagram, each resulting fragment is stamped with the source address, destination address and identification number of the origin datagram. The last fragment has a flag bit set to 0, whereas all other fragments have this bit set to 1 (has more fragments). The offset field is used to specify where the fragments fits within the original IP datagram.
- length:含 ip 头 的字节长度
- id:同一个分组的分片有相同 id
- flag:是否还有后续片
- offset:之前的所有片的字节长度除以 8(不含 ip 头)
4.4.3 IPv4 Addressing
An IP address is technically associated with an interface, rather than with the host or router containing that interface.(地址分给网卡而不是主机)
Each IP address is 32 bits long (4 bytes), are written in so-called dotted-decimal notation. Each interface on every host and router in the global Internet must have an IP address that is globally unique (except behind NATs).
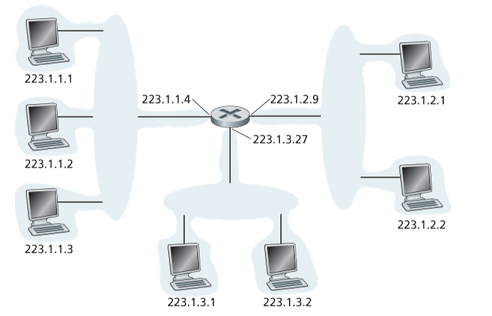
Interfaces interconnected to each other by a network that contains no routers (Ethernet switch or wireless access point) along with one router interface forms a subnet. For example, the upper-left subnet shares an address 223.1.1.0/24, where the /24 notation (subnet mask) indicates that the leftmost 24 btis define the subnet address. The 223.1.1.0/24 subnet consists of the three host interfaces and one router interface.
To determine the subnets, detach each interface from its host or router, creating islands of isolated networks, with interface terminating the end points of the isolated networks. Each of these isolated networks is called a subnet.
The Internet’s address assignment strategy is known as Classless Interdomain Routing (CIDR), the 32-bit address is divided into two parts and has the form a.b.c.d/x, where xxx indicates the number of bits in the first part of the address.
The xxx most significant bits of an address constitude the network portion of the IP address (referred to as prefix of the address). IP addresses of devices within the organization will share the common prefix. The remaining 32-x32-x32-x bits can be thought of as distinguishing among devices within the organization, all of which have the same prefix.

Before CIDR was adopted, the network portions of an IP address were constrained to be 8, 16, or 24 bits in length, an addressing scheme known as classful addressing. Subnets with 8, 16, and 24-bit subnet addresses were known as class A, B, and C networks respectively.
The IP broadcast address is 255.255.255.255. When a host sends a datagram with destination address 255.255.255.255, the message is delivered to all hsots on the same subnet.
A 类 126个,127专用;B 类 个;C 类主机号只有8位
-
主机全 0 为网络地址,路由器路由表现
-
全 0 为该网络的该主机
-
网络全 0 为本网络的某主机
-
主机全 1 为直接广播地址,某网络全部主机
-
全 1 为受限广播地址,本网络全部主机
-
127 开头为环回地址
-
子网:将主机位中的前几位设为子网号
-
子网掩码:将标准地址与掩码按位与得到子网号(故默认掩码为 255.255.255.0)
-
例如 255.255.240.0 (240=11110000)从B类网络的16位主机号借了4位作为子网号,即
-
子网号中全0全1保留,故子网至少要2位,主机号也至少2位

Addresses are loose by subnet
分子网只会减少能用的主机!子网只是方便路由器进行管理
VLSM:变长子网号。选取规模更大的子网的子网号时要注意不能与规模更小的子网号的头部相同。
CIDR:CIDR表示法: IP地址 ::= {<网络前缀>, <主机号>} / 网络前缀所占位数,例如128.14.35.7/20
Obtaining a Block of Addresses
A network administrator first contact its ISP, ISP divide its address block and give one of these blocks to organizations.
The Dynamic Host Configuration Protocol (DHCP)
DHCP allows a host to obtain an IP address automatically. A given host receives the same IP address each time it connects to the network, or a host may be assigned a temporaty IP address that will be different each time the host connects to the network.
DHCP is referred to as a plug-and-play or zeroconf protocol.
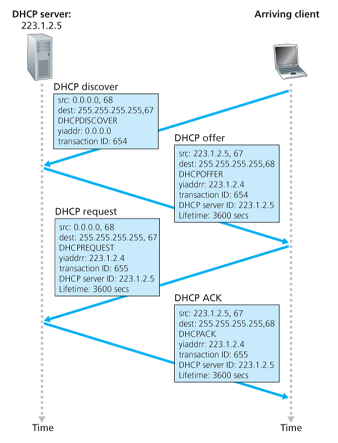
- DHCP server discovery: a newly arriving host finds a DHCP server using a DHCP discover message, which sends (broadcasts) within a UDP packet to port
67. - DHCP server offer: A DHCP server receiving a DHCP discover message responds to the client with a DHCP offer message that is broadcast to all nodes on the subnet, containing the transaction ID, the proposed IP address, network mask and an IP address lease time (the amount of time for which the IP address will be valid).
- DHCP request: the newly arriving client will choose from one or more offers and respond to its selected offer with a DHCP request message, echoing back the configuration parameters.
- DHCP ACK: the server responds with a DHCP ACK message confirming the requested parameters.
4.4.4 Network Address Translation (NAT)
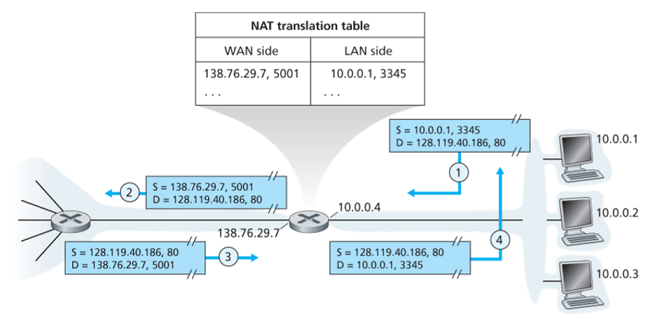
The NAT router behaves to the outside world as a single device with a single IP address.
When NAT router receives a datagram, it generates a new source port number for the datagram and replace the IP address and port number in it. When generating a new source port number, the NAT router can select any source port number that is not currently in the NAT translation table.
When NAT router receives a response, it indexes the NAT translation table using the destination IP address and port number to obtain the appropriate IP address and port in the NAT network, and rewrite the destination into the datagram.
用端口号表示内网连接
穿越NAT方法:
- 静态配置:绑定路由器某端口与内网设备的某端口
- UPnP:动态配置
- 中继:将NAT信息登记到应用提供商的服务器
4.4.5 ICMP
internet control message protocol,主要通知报错信息
ICMP 报文包含一个类型字段和一个编码字段
ICMP通常被认为是IP的一部分,但从体系结构看是在IP之上,是3.5层。
traceroute就基于ICMP

4.4.6 IPv6
IPv6 Datagram Format
- Expanded addressing capabilites: 128 bits of IP address, and introduced a new type of address called anycast address that allows a datagram to be delivered to any one of a group of hosts.
- A streamlined 40-byte header: a fixed-length header allows for faster processing by a router.
- Flow labeling: IPv6 has an elusive definition of a flow, allows labeling of packets belonging to particular flows for which the sender requests special handling.
in ipv4: Datagram: five turple: {ip_src, ip_des, port_src, port_des, protocol_transport}

- Version: value
6. - Traffic class: 8 bits, priority, like TOS in IPv4 but more precise.
- Flow label: 20 bits, identify a flow of datagrams.
- Payload length: 16 bits, giving the number of bytes of payload.
- Next header: identifies the protocol to which the contents in this datagram will delivered (TCP/UDP/etc.) like protocol field in IPv4.
- Hop limit: TTL.
- Source and destination address
- Data
Several fields in IPv4 are no longer present in IPv6 datagram:
- Fragmentation: IPv6 does not allow fragmentation. If an IPv6 datagram is too big, then the router drops the datagram and sends a “Packet Too Big” ICMP error message back to the sender.
- Header checksum: the checksum is redundant.
- Options: options is sotred in data, can be pointed to by next header field in IPv6.
Transitioning from IPv4 to IPv6
Tunneling:把ipv6的报文封装在ipv4的里,需要人工配置隧道
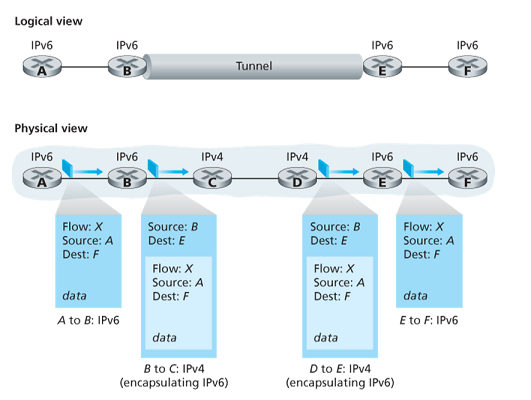
4.5 Generalized Forwarding and SDN
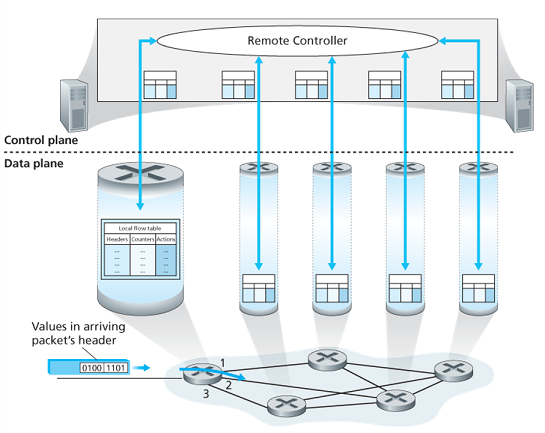
Packet switch contains a match-plus-action table (flow table) that is computed and distributed by a remote controller:
- a set of header field values
- a set of counters
- a set of actions to be taken:
- forwarding
- dropping
- modify-field
Chapter 5 - The Network Layer: Control Plane
5.1 Introduction
How to compute, maintain and install flow tables?
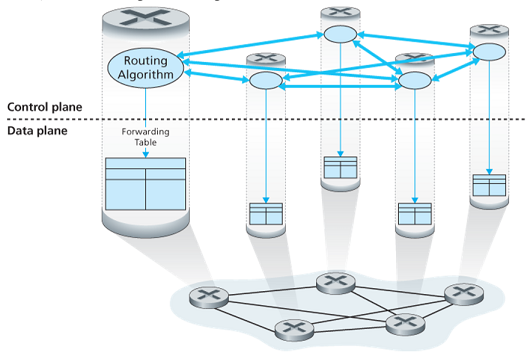
- Per-router control: a routing algorithm runs in each and every router, e.g. OSPF and BGP protocols
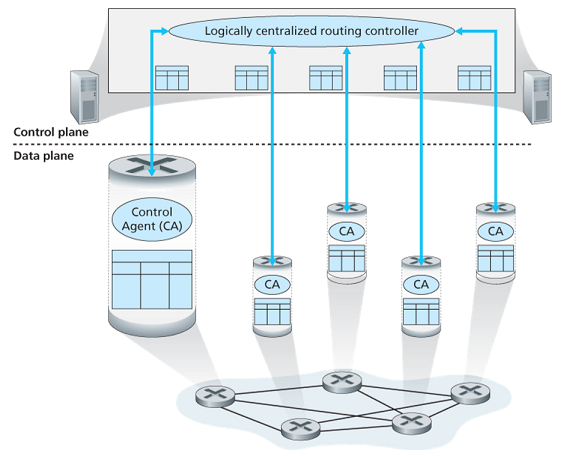
- Logically centralized control: a logically centralized controller computes and distributes the forwarding tables, interacts with a control agent (CA) in each of the routers via a well-defined protocol.
5.2 Routing Algorithms
The goal of routing algorithms is to determine good (with least cost) paths from senders to receivers, through the network of routers.
- A centralized routing algorithm computes the least-cost path using complete, global knowledge about the network. This requires the algorithm somehow obtain this information before calculating. Algorithms with global state information are often referred to as link-state (LS) algorithms, can be run at one site or be replicated in every router.
- A decentralized routing algorithm calculate the least-cost path in an iterative, distributed manner. Through iterative process of calculation and exchange of information with its neighboring nodes, a node gradually calculates the least-cost path to a destination. A decentralized routing algorithm is called distance-vector (DV) algorithm.
Another classification is whether the routing algorithm is static or dynamic.
- In static routing algorithms, routes change very slowly over time, often as a result of human intervention.
- Dynamic routing algorithms change the routing paths as the network traffic loads or topology change. A dynamic algorithm can be run periodically or in direct response to topology or link cost changes. They may suffer from problems as routing loops and route oscillation.
A third classification is according to whether they are load-sensitive or load-insensitive.
- In a load-sensitive algorithm, link costs vary dynamically to reflect the current level of congestion in the underlying link. If a high cost associated with a link that is congested, a routing algorithm will tend to choose other routes.
- Today’s routing algorithms (RIP, OSPF, BGP) are load-insensitive, as a link’s cost does not explicitly reflect its current level of congestion.
路由器只关心下一跳去哪,而不关心整体的路径。路由算法负责维护转发表。
把网络抽象为有权图,路由算法就在该图中求解最短路径。
-
全局路由算法:L-S
-
分布路由算法:D-V
-
静态路由算法:人工填写,若拓扑结构有变化(例如链路故障)就要人工及时修改
-
动态路由算法
5.2.1 The Link-State (LS) Routing Algorithm
Link-State Packet,链路状态报文,即路由器测量与其直接相连的路由器的链路状态(延时), 生成LS报文,并向所有路由器广播,由此每个路由器都获得了完整网络拓扑结构。
一个LS报文记录从路由器A到路由器B的链路状态,路由器每收到一个邻居发来的LS报文就要应答, 并向其他路由器发送新收到的这个报文
每个路由器会对每个已收到的LS报文贴上一个序号和生存期,此后只会记录序号更大的LS报文
获得完整网络拓扑结构后使用Dijsktra算法(每次选一个距离最近的点,用它更新其他点的距离,具体略)
考虑流量的时候,会出现链路负载振荡的现象
5.2.2 The Distance-Vector (DV) Routing Algorithm
DV algorithm is
- iterative
- asynchronous
- distributed: each node receives some information from neighbors, performs a calculation and then distributes the results to neighbors
Bellman-Ford equation:
Each node xxx maintains the following routing information:
- For each neighbor vvv, the cost from xxx to directly attached neighbor vvv,
- Node xxx's distance vector , containing xxx's estimate of its cost to all destinations yyy,
- The distance vectors of each of its neighbors .
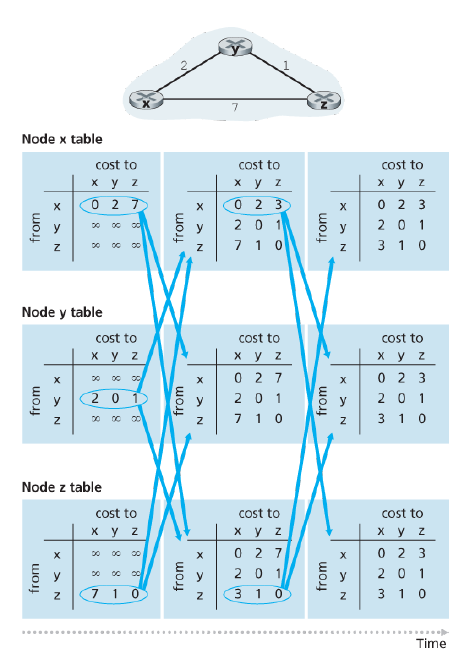
From time to time, each node sends a copy of its distance vector to each of its neighbors. When a node xxx receives a new distance vector from any of its neighbors www, it saves www's distance vector and then uses the Bellman-Ford equation to update its own vector.
Problem and technique:
- Link failure
- Routing loop
- Poisoned reverse
DV:Distance vector,距离向量
路由器A计算自身到C的成本(A-C不直连):获取邻居路由器B到C的成本,则A到C=A到B+B到C
当链路状态有变化时,将自己的DV发给邻居,邻居据此通过Bellman-Ford 算法重新计算,若有变化,则通知邻居
好消息更新快,坏消息更新慢:因为坏消息之前的状态会残留在邻居的通知内

出现路由黑洞,通过毒性逆转解决,即当C通过B选路到达A时,C告诉B C到A的成本为无穷大 (然而该协议在环路内失效)
Comparison of LS and DV Routing Algorithms
- Message complexity
- Speed of coverage: DV can converge slowly and can have routing loops and suffers from count-to-infinity problem
- Robustness
- 报文复杂性:DV仅在新的链路费用导致最优路径变化时才广播,而LS在任意变化下都广播
- 收敛速度:DV收敛慢,还有路由黑洞
- 鲁棒性:DV算法的一个不正确的节点计算值会扩散到整个网络
5.3 Intra-AS Routing in the Internet
One router is indistinguishable from another in the sense that all routers executed the same routing algorithm to compute routing paths through the network. This model is simplistic for two reasons:
- Scale: As number of routers becomes large, the overhead involved in communicating, computing and storing routing information becomes prohibitive.
- Administrative autonomy: an organization should be able to operato and administer its network as it wishes, while still being able to connect its network to other outside networks.
Both of these problems can be solved by organizing routers into autonomous systems (ASs) with each AS consisting of a group of routers that are under the same administrative control.
Routers within the same AS all run the same routing algorithm and have information about each other. The routing algorithm running within an autonomous system is called an intra-autonomous system routing protocol.
intra-AS Routing 也被称为 interior gateway protocols(IGP)
上述选路算法在大规模网络的迭代一定不会收敛,并且单个路由器不应受限于外部网络而被迫选用某种选路算法。
自治系统(Autonomous System,AS)用于解决这两个问题。
AS之间运行自治系统间选路协议(inter-AS routing,) 一个AS内部的路由器运行相同的选路算法(intra-AS routing),且拥有彼此之间的信息。 每个AS都有一个或多个负责连接外部网络,称为网关路由器。
AS routing 是要让 某个 AS 知道地址ip属于哪个 AS; 当这个地址属于两个AS时,还要在AS层面确定选哪条链路最优。(选路算法必须让每个ip只有一条路径)
5.3.1 RIP
Routing Information Protocol是基于DV的。
- RIP的成本计算是以跳数计,一跳就是1,最多支持15跳。
- 路由器每30秒与邻居打一次招呼(更新)
- 每次只能更新25个目的子网
路由器根据邻居发来的通告(即邻居自己的转发表)更新自身转发表。 若180秒未监听到邻居,就认为其不可达,并通告其他路由器。
路由器也可以使用RIP请求邻居到指定目的地的费用(以UDP的方式使用520端口)
5.3.2 OSPF
OSPF is a link-state protocol that uses flooding of link-state information and a Dijkstra’s least-cost path algorithm. With OSPF, each router constructs a complete topological map of the AS. Each router then locally runs Dijkstra’s shortest-path algorithm to determine a shortest-path tree to all subnets, with itself as the root node.
With OSPF, a router broadcasts routing information to all other routers in the AS, not just to neighbors. A router broadcasts link-state information whenever there is a change in a link’s state. It also broadcasts a link’s state perodically even if there is no change. The OSPF protocol must itself implement functionality such as reliable message transfer and link-state broadcast. The OSPF protocol also checks that links are operational (via a HELLO message) and allows an OSPF router to obtain a neighboring router’s database of network-wide link state.
Some of the advances embodied in OSPF:
- Security. Exchanges between OSPF routers can be authenticated.(可以借助MD5)
- Multiple same-cost paths.
- Integrated support for unicast and multicast routing.
- Support or hierarchy within a single AS. An OSPF autonomous system can be configured hierarchically into areas.
OSPF是RIP的后继者。RIP是DV类算法的典型代表,而OSPF是LS的代表协议核心是一个使用泛洪链路状态信息的协议和Dijkstra算法。
OSPF 通告包含在OSPF报文中,而报文直接承载在IP分组中,不依赖TCP、UDP。
OSPF 将AS再细分为了多个区域(area),其中有一个主干(backbone)区域,负责为其他区域之间的流量选路。
- 内部路由器:不属于主干,只执行 intra-AS
- 区域边界路由器:同时属于区域和主干
- 主干路由器(非边界路由器):内部路由器通过所在区域的主干路由器知晓通往其他区域的路由
- 边界路由器:与其它AS的路由器交流
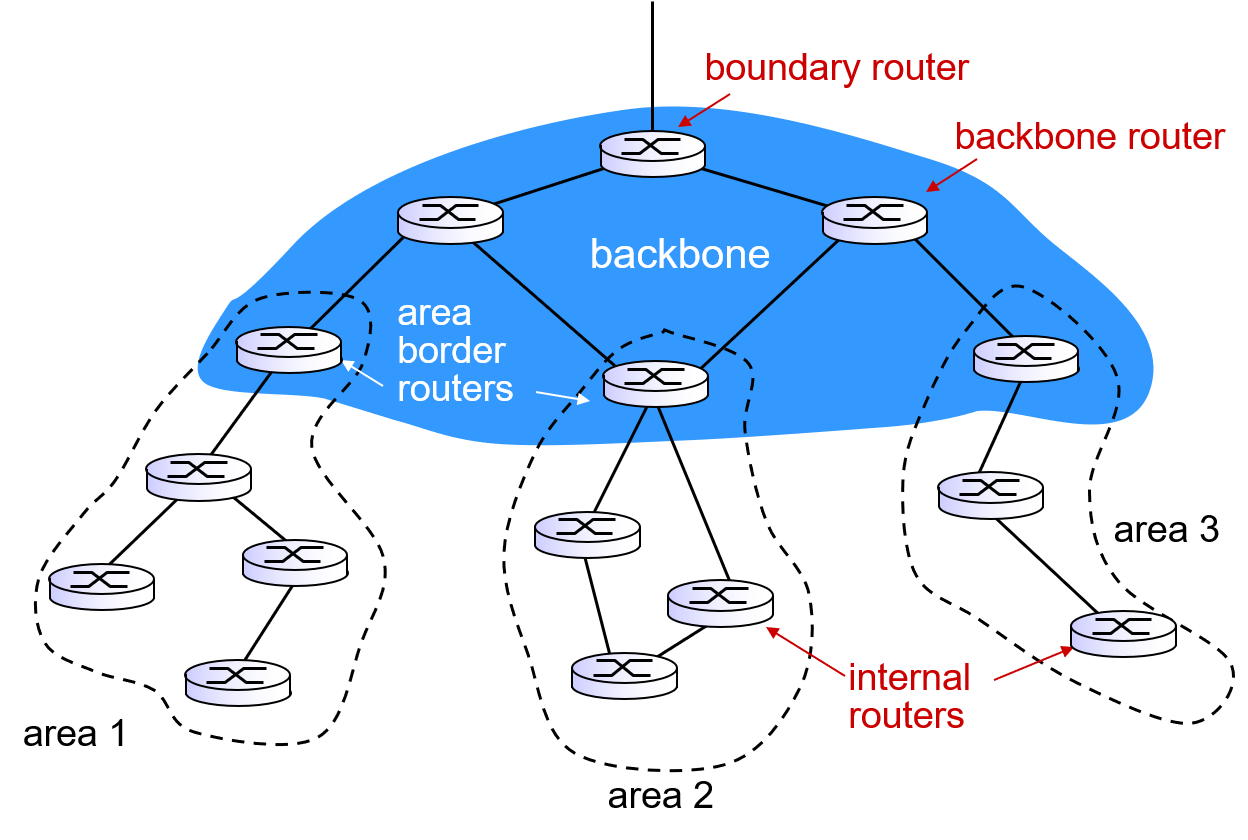
5.4 Routing Among the ISPs: BGP
In the Internet, all ASs run the same inter-AS routing protocol, called the Border Gateway Protocol, known as BGP.
5.4.1 The Role of BGP
In BGP, packets are routed to CIDRized prefixes, with each prefix representing a subnet or a collection of subnets. A router’s forwarding table has entries of the form , where xxx is a prefix and lll is an interface number for one of the router’s interfaces.
As a inter-AS routing protocol, BGP provides each router a means to:
- Obtain prefix reachabilitiy information from neighboring ASs. BGP allows each subnet to advertise its existence to the rest of the Internet.
- Determine the “best” routes to the prefixes. To determine the best route, a router will locally run a BGP route-selection procedure.
5.4.2 Advertising BGP Route Information
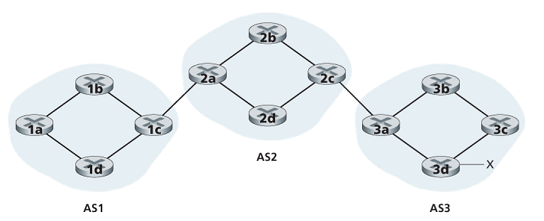
For each AS, each router is either a gateway router or an internal router. A gateway router is a router on the edge of an AS that directly connects to one or more routers in other ASs. An internal router connects only to hosts and routers within its own AS.
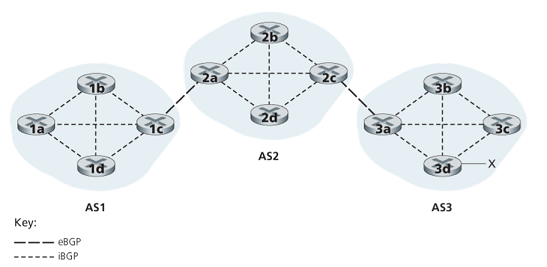
Pairs of routers exchange routing information over semi-permanent TCP connections using port 179. Each such TCP connection, along with all the BGP messages sent over the connection, is called a BGP connection. Furthermore, a BGP connection that spans two ASs is called an external BGP (eBGP) (vice versa, internal BGP (iBGP)). In order to propagate the reachability information, both iBGP and eBGP sessiona re used.
- eBGP:在AS之间传播可达信息,网关路由器用eBGP向其他网关路由器通告所在网络能够到达的其他网络
- iBGP:在AS内部传播可达信息,网关路由器用iBGP向所在网络的其他路由器通告eBGP获得的信息
eBGP 需要直接连接,iBGP不需要(TCP报文可以经过多跳)
5.4.3 Determining the Best Routes
prefix + attribute = route
When a router advertises a prefix across a BGP connection, it includes with the prefix serveral BGP attributes. In BGP jargon, a prefix along with its attributes is called a route. Two of the more important attributes are AS-PATH and NEXT-HOP.
prefix:CIDR化的ip地址,指代一个子网或者多个子网
The AS-PATH attribute contains the list of ASs through which the advertisement has passed. BGP routers also use the AS-PATH attribute to detect and prevent looping advertisements. If a router sees that its own AS is contained in the path, it will reject the advertisement.
The NEXT-HOP is the IP address of the router interface that begins the AS-PATH.
AS-PATH:当AS收到一个 prefix 时,就将自己的ASN添加到 prefix 中,以便于其它路由器检测和防止循环通告。
NEXT-HOP:记录了要路由到下一跳的AS所要通过的AS内部的路由器
若路由器知道了到达目的AS的多条路径,则通过以下方式来选择路径:
- 最短 AS-PATH
- 最近 NEXT-HOP 路由器:hot potato routing
- 附加准则
BGP报文有四种格式:
- OPEN:建立一个到邻居或认证发送方的TCP连接
- UPDATE:广播新路径(或撤销旧路径)
- KEEPALIVE:在没有更新时保持TCP连接,同时也作为OPEN的ack
- NOTIFICATION:通报先前信息的错误,也用于关闭TCP连接
e.g.: a update msg: prefix:138.16.64/22; AS-PATH: AS3 AS131; NEXT-HOP: 201.44.13.125
BGP routing policy
policy分为inport和outport,即对入口的过滤和出口的过滤。
inport policy:
若一个用户网络同时连接两个提供商网络,则称其为 双选(dual-homed)网络。
双选网络(x)通常不会告诉其提供商网络(B)它自身与另一个提供商网络(C)相连, 否则就有可能有从B到C的流量通过双选网络转发,这对x毫无意义(除非给钱)。
同理,B也不会告诉C其与A相连,否则有可能C会通过B到A,而非直连A。
甚至可以设置夜间走B,日间走C。
outport policy:
B告知A可以从B到x,A也可以不信任之,忽略该通告
intra-AS不支持任何policy,只关注性能
BGP Notes
BGP 只计算 AS 跳数,不计算路由器跳数,即:BGP选择的是AS-path最短的路径,与路由器个数无关
Next-Hop 不会保留源路由器的端口号,而是改为发布者的端口号,便于回溯
Hot Potato Routing

In hot potato routing, the route chosen is that route with the least cost to the NEXT-HOP router beginning that route.
Hot potate routing is a selfish algorithm - it tries to reduce the cost in its own AS while ignoring other components of the end-to-end costs outside its AS.
In pratice, BGP uses an algorithm that is more complicated than hot potato routing. For any given destination prefix, the input into BGP’s route-selection algorithm is the set of all routes to that prefix that have been learned and accepted by the router. If there are multiple routes to same prefix, then BGP sequentially invokes the following elimination rules until one route remains:
- A route is assigned a local reference value as one of its attributes. The local preference could have been set by the router or could have been learned from another router in the same AS. The value of the local preference attribute is a policy decision that is left entirely up to the AS’s network administrator. The routes with the highest local preference values are selected.
- From the remaining routes, the route with shortest AS-PATH is selected.
- From the remaining routes, the route with the closest NEXT-HOP router is selected (hot potato).
- If more than one route still remains, the router uses BGP identifiers to select the route.
5.4.4 IP-Anycast
BGP is often used to implement the IP-anycast serice, which is commonly used in DNS.
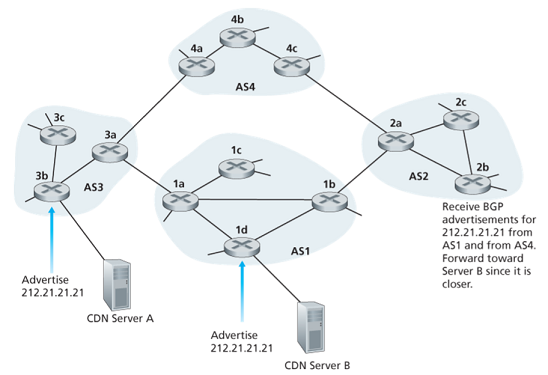
During the IP-anycast configuration stage, the CDN company assigns the same IP address to each of its servers and uses standard BGP to advertise this IP address from each of the servers.
When a BGP router receives multiple route advertisements for this address, it treats these advertisements as providing different paths to the same physical location (different actually). Each router will locally use the BGP route-selection algorithm to pick the best route to that IP address.
5.4.5 Routing Policy
(一些设置策略,略)
5.4.6 Putting the Pieces Together: Obtaining Internet Presence
- IP addressing
- Domain name and DNS
- BGP propagation

广播和多播选路
广播
源不必把一个报文发多次,每次设定不同目的,而是只要发一次,在路由时广播。
节点转发过就不必再转发,节点通过序号来辨别,即转发的报文只递增不递减。
用生成树的形式实现,源作为树的根。
组播(多播)
地址为D类,即1110开头。组播地址需要申请。
保留的组播地址:224.0.0.x
- x = 1:本子网所有系统
- x = 2:本子网所有路由器
- x = 4:本子网所有DVMRP路由器
- x = 5:本子网所有OSPF路由器
- x = 6:本子网所有OSPF指派路由器
- x = 9:本子网所有RIPv2路由器
- x = 13:本子网所有PIM路由器
组播范围利用 TTL 来实现(过一次路由器TTL-1)
|范围|TTL|地址范围|描述|
|---|---|---|---|
|链路|1|224.0.0.0~224.0.0.255|只在局域网内传送
|部门|32|239.255.0.0~239.255.255.255|只在部门内传送
|组织|64|239.192.0.0~239.195.255.255|只在组织内传送
|全局|255|224.0.1.0~238.255.255.255|可在Internet内传送
IP组播地址到MAC组播地址的映射:IP的后23位直接映射到MAC地址的后23位(IP前4位固定,中间5位未映射)
由于有未映射的字段,因此可能出现 IP 不同,MAC 相同的异常情况
IGMP
Internet Group Management Protocol,互联网组管理协议,既不属于传输层,也不属于网络层
IGMP 管理路由器上的组播组,并维护状态表来进行转发。
组播路由
组播主机向ICANN申请组播组,然后其它想加入的计算机向自己的路由器请求加入改组。
拓扑结构上会形成一个~~以组播源为根的~~树。
- 共享树:所有的广播源都在该树内
- SPT:最短路径树(Dijkstra,OSPF原生支持)
- RPF:反向道路传递(Reverse Path Forwarding)
- 若组播报文从某一返回中心的最短链路输入,则将该报文向所有输出链路广播,否则忽略该报文
- 剪枝(prune):若一个路由器发现所在局域网无人收听,则向上游路由器发送剪枝报文
- 过一段时间后重复 flood,prune 操作
- 不依赖全局信息
- 基于源的树:基于发送方生成的树
- minimal spanning tree:最小生成树。复杂度太高
- CBT:Center Based Tree
- 合理选择一个中心(center)
- 边界路由器发送接枝报文给上游路由器,然后完成接枝或成为中心
- 若组播源更改为组内的另一主机,就要重新生成树,但共享树不用
DVMRP
DVMRP:Distance Vector Multicast Routing Protocol
在 OSPF 上加上剪枝:每隔一段时间重复 flood,prune 操作,即忽略之前剪枝过的区域
隧道
有些路由器不支持组播,就打包在单播报文里穿透之。
5.5 The SDN Control Plane
Four key characteristics of an SDN architecture:
- Flow-based forwarding. Packet forwarding by SDN-controllered switches can be based on any number of header field values in the transport-layer, network-layer or link-layer header.
- Separation of data plane and control plane.
- Network control functions: external to data-plane switches.
- A programmable network. The network is programmable through the network-control applications running in the control plane.
5.5.1 SDN Controller and SDN Network-control APplications
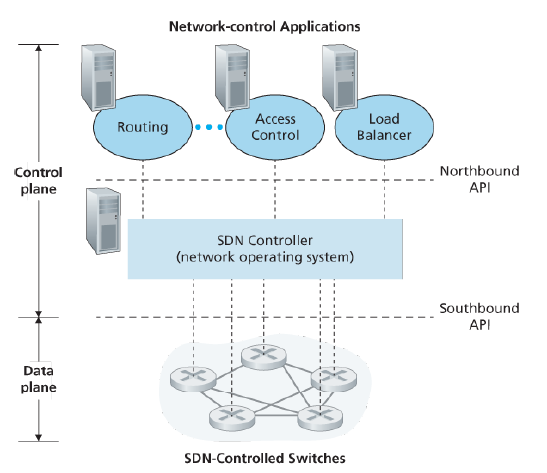
A SDN controller’s functionality can be broadly organized into three layers.
- A communication layer: communicating between the SDN controller and controlled network devices. SDN controller controls the operation of a remote SDN-enabled switch, host or other devices. A device must be able to communicate locally-observed events to the controller. These events provide the SDN controller with an up-to-date view of the network’s state.
- A network-wide state-management layer.
- The interface to the network-control application layer. The northbound API allows network-control applications to read/write network state and flow tables within the state-management layer.
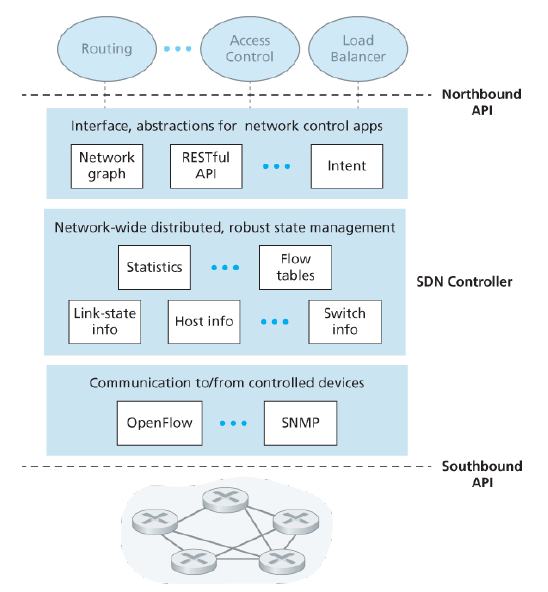
5.5.2 OpenFlow Protocol
The OpenFlow protocol operates between an SDN controller and an SDN-controlled switch or other device implementing the OpenFlow API. The OpenFlow protocol operates over TCP, with a default port number of 6653.
Among the important messages flowing from the controller to the controlled switch are the following:
- Configuration. Allows the controller to query and set a switch’s configuration parameters.
- Modify-State. Used by a controller to add/delete or modify entries in the switch’s flow table.
- Read-State. Collect statistics and counter values from the switch.
- Send-Packet. Send a specific packet out of a specified port at the controlled switch.
Among the messages flowing from the switch to the controller are the following:
- Flow-Removed. Inform the controller that a flow table entry has been removed.
- Port-Status. Inform the controller of a change in port status.
- Packet-in. A packet arriving and not matching any flow table entry is sent to the controller for additional processing. (Matched packets may also be sent as an action taken on a match.)
An example in link-state change:

5.5.4 SDN: Past and Future
(略)
5.6 ICMP: The Internet Control Message Protocol
ICMP is used by hosts and routers to communicate network-layer information to each other. The most typical use of ICMP is for error reporting.
ICMP is often considered part of IP, but architecturally it lies just above IP, as ICMP messages are carried inside IP datagrams. When a host receives an IP datagram with ICMP as the upper-layer protocol, it demultiplexes the datagram’s contents to ICMP.
ICMP messages have a type and a code field, and contain the header and the first 8 bytes of the IP datagram that caused the ICMP message to be generated in the first place.
The well-known ping program sends an ICMP type 8 code 0 message to the specified host. The destination host, seeing the echo request, sends back a type 0 code 0 ICMP echo reply.
Source quench message is designed to perform congestion control - to allow a congested router to send an ICMP source quench message to a host to force that host to reduce its transmission rate.
Traceroute is implemented with ICMP messages. According to the rules of the IP protocol, the router observes that the TTL of datagram (is set to nnn originally) has just expired, the router discards the datagram and sends an ICMP warning message to the source (type 11 code 0). This warning message includes the name of the router and its IP address.
One of the datagrams will eventually arrive the destination host, with a UDP segment with an unlikely port number, the destination host sends a port unreachable ICMP message (type 3 code 3) back to the source. The source would know it does not need to send additional probe packets.
5.7 Network Maganement and SNMP
Network management includes the deployment, integration, and coordination of the hardware, software, and human elements to monitor, test, poll, configure, analyze, evaluate, and control the network and element resources to meet the real-time, operational performance, and Quality of Service requirements at a reasonable cost.
- MIB = Management Information Base
- SNMP = Simple Network Management Protocol
- PDU = Protocol Data Unit
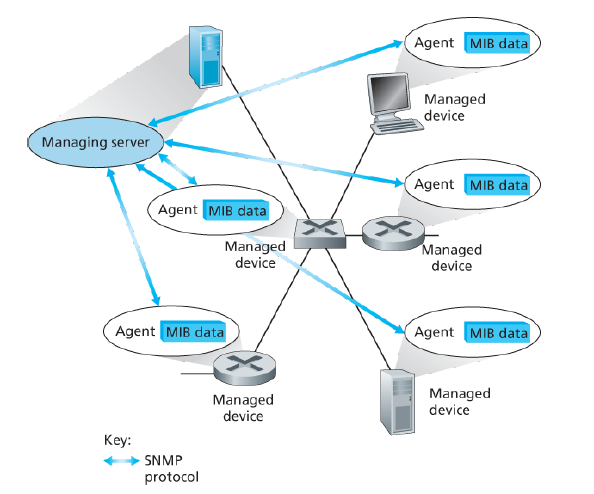
The Simple Network Management Protocol version 2 (SNMPv2) is an application-layer protocol used to convey network-management control and information messages between a managing server and an agent executing on behalf of that managing server.
The most common usage of SNMP is in a request-response mode in which an SNMP managing server sends a request to an SNMP agent, who receives the request, performs some action, and sends a reply to the request. Typically, a request will be used to query (retrieve) or modify (set) MIB object values associated with a managed device. A second common usage of SNMP is for an agent to send an unsolicited message, known as a trap message, to a managing server. Trap messages are used to notify a managing server of an exceptional situation (e.g., a link interface going up or down) that has resulted in changes to MIB object values.
第6章 - 链路层和局域网
6.1 链路层概述
- 运行链路层协议的任何设备均称为节点(node)
- 沿着通信路径连接相邻节点的通信信道称为链路(link)
- 在经过特定的链路时,传输节点将数据报封装在链路层帧中,并将该帧传输到链路中
链路层提供的服务
- 成帧(framing):有帧头帧尾,故又称帧定界
- 链路接入(媒体访问控制协议/MAC)
- 可靠交付(相邻节点间可靠,不保证端到端可靠,因为可能在节点被抛弃)
- 流量控制
- 差错检测和纠正
- 半双工和全双工
链路:加上可靠性控制的电路
链路层在何处实现
- 主体部分:网络适配器(network adapter)/网络接口卡(Network Interface Card, NIC)
- 网络适配器核心是链路层控制器,一个实现了许多链路层服务的专用芯片
- 链路层功能大多是硬件实现的,但部分是在运行于主机CPU上的软件中实现的
链路层是硬件和软件的结合体,即是协议栈中软件和硬件交接的地方。
0.5层:驱动,在软件做;1.5层:网卡,在硬件做。
源到目的可能经过多种链路层协议
6.2 差错检测和纠正
- 差错检测和纠正比特(Error-Detection-and-Correction, EDC)
- 未检出比特差错(undetected bit error)
3种技术(具体见数据通信笔记):
- 奇偶校验
- 加上校验位后共有奇数个 1 or偶数个 1
- 二维:在纵向也进行奇偶校验,如此能够实现差错纠正
- 最短校验和:一般在将数据排成接近正方形的格式能实现最短校验和
- 检验和(checksum,适用于运输层)、因特网检验和
- 切成16位一段,取二进制补码,求和,把进位加回最低位
- 循环冗余检测(CRC,适用于适配器中的链路层):多项式编码、生成多项式
- 数据 D,r+1 位的生成多项式 G(最高次为r),G 的最高位须为1
- 发送方选择 r 个附加比特 R,附加到 D 之后,使得得到的 d+r 能够用模2算术被 G 整除
- 接收方若发现不能整除,则出错
- R 实际就是 (D<<r)/G 的余数(此处除法每步是异或,不是减法!)
- codeword:D后接R
若 G 中 的系数非0,则可以检测所有 1 比特差错
若 G 中含有 至少三项的因式~~()~~,则可以检测所有 2 比特差错
若 G 中含因式 x+1,则可以检测所有奇数比特差错
可以检测长度不大于 r 的差错,大于 r 的不一定能检测到
G 的各项系数为 1 或 0,所有运算均模 2
6.3 多路访问链路和协议
两种类型的网络链路:点对点链路和广播链路。
- 点对点链路
- 由链路一端的单个发送方和另一端的单个接收方组成
- 点对点协议(point-to-point protocol, PPP)、高级数据链路控制协议(HDLC)
- 广播链路
- 多个发送和接收节点都连接到相同的、单一的、共享的广播信道上
- 任何一个节点传输一个帧,信道广播该帧,每个其他节点都收到一个副本
- 以太网、无线局域网
多路访问问题(multiple access problem):如何协调多个发送和接收节点对一个共享广播信道的访问?
- 多路访问协议(multiple access protocol):节点通过这些协议来规范它们在共享的广播信道上的传输行为,并且不需要一个单独的信道进行管理。又称介质访问控制协议。
- 碰撞(collide):多个节点同时传输帧,所有节点同时接到多个帧,没有一个节点能够有效的获得任何传输的帧。
- 3种类型的协议:
- 信道划分协议(channel partitioning protocol):借助频分、时分、码分划分信道
- 随机接入协议(random access protocol):允许冲突,协议负责从冲突中恢复
- 轮流协议(taking-turns protocol):轮流让信道担任管理者
在理想情况下,对于速率为 bps的广播信道,多路访问协议应该具有以下所需要的特性:
- 当仅有一个节点发送数据时,该节点具有RRR bps的吞吐量;
- 当由MMM个节点发送数据时,每个节点(平均)吞吐量为 bps;
- 协议是分散的,不会因为某主节点故障导致系统崩溃;
- 协议是简单的,实现不昂贵。
信道划分协议
前两种详见数据通信笔记。
用户数固定
- 时分多路复用(TDM)
- 时间帧(time frame)、时隙(slot)
- 完全避免碰撞
- 两个主要缺陷:
- 节点被限制于 bps的平均速率
- 节点必须总是等待它在传输序列中的轮次
- 频分多路复用(FDM)
- 具有TDM同样的优点和缺点
- 限制一个节点只能使用 bps的带宽
- 码分多址(Code Division Multiple Access, CDMA)
- 每个节点分配一种不同的编码
- 技术细节见
第7章
随机接入协议
随机接入协议中,一个传输节点总是以信道的全部速率进行发送。当有碰撞时,涉及碰撞的每个节点反复地重发它的帧(分组),直到该帧无碰撞的通过为止。
但是当一个节点经历一次碰撞时,它不必立刻重发该帧,而是等待一个随机时延(独立地选择随机时延)。
常见的随机接入协议:
- ALOHA:纯 ALOHA 和 时隙 ALOHA
- 载波侦听多路访问(CSMA)(以太网)
ALOHA 是夏威夷语里的问候语,世界上第一个无线网络 ALOHA 就是为了解决夏威夷群岛之间的通信问题
纯 ALOHA
- 当一帧首次到达(一个网络层数据报在发送节点从网络层传递下来),节点立刻将该帧完整地传输进广播信道。
- 如果帧的传输经历了碰撞,该节点立即(完全传输后)以概率 重传该帧。
- 否则,该节点等待一个帧传输时间。在此等待后,以概率 传输该帧,或者以概率 再等待一个帧传输时间。
成功传输要求其他节点在2个时间间隔内不传输(即只要与其它帧有部分重叠,就判定为冲突),因此一个节点成功传输的概率是 ,纯ALOHA协议的最大效率为 ,其中 N 为节点总数。
时隙 ALOHA
作出假设:
- 所有帧都是比特长
- 一个时隙等于传输一帧的时间
- 结点只在时隙起点开始传输帧
- 结点是同步的,每个节点都知道时隙何时开始
- 如果一个时隙中有两个或更多个碰撞帧,则所有节点在该时隙结束之前检测到碰撞事件
令是一个概率,则每个节点中时隙ALOHA的操作为:
- 当节点有一个新帧要发送时,它等到下一个时隙开始并在该时隙传输整个帧;
- 如果没有碰撞,该节点成功传输,不需要考虑重传;
- 如果有碰撞,则该节点在时隙结束之前检测到碰撞。该节点以概率在后续的每个时隙中重传它的帧,直到该帧被无碰撞地传输出去。
优点:
- 当某节点是唯一活跃的节点时,允许以全速连续传输。
- 分散的:每个节点检测碰撞并独立地决定什么时候重传(但仍然需要对时隙同步,即各节点时钟同步)。
- 极为简单。
效率:当有大量的活跃节点并且每个节点总有大量的帧要发送时,长期运行中成功时隙(刚好有一个节点传输的时隙)的份额。
假设有个节点,则一个给定节点成功传送的概率是,任意一个结点成功传送的概率是。因此,时隙 ALOHA 的效率是 。协议的最大效率为 。
载波侦听多路访问(CSMA)
载波侦听多路访问(CSMA)和具有碰撞检测的CSMA(CSMA/CD)协议族中包括两个规则:
- 载波侦听(carrier sensing):一个节点在传输前先侦听信道。如果来自另一个节点的帧正向信道上发送,节点则等待直到检测到一小段时间没有传输,然后开始传输。
- 碰撞检测(collision detection):当一个节点在传输时一直在侦听信道,如果检测到另一个节点正在传输干扰帧,就停止传输并等待一段随机时间。
由于信道传播时延,即使在侦听当前信道,仍然可能导致碰撞发生。传播时延越大,载波侦听节点不能侦听到网络中另一个节点已经开始传输的机会就越大。
具有碰撞检测的载波侦听多路访问(CSMA/CD)
- 适配器从网络层获得一条数据报,准备链路层帧,并将帧放入适配器缓存中;
- 如果适配器侦听到信道空闲,它开始传输帧。否则则等待直到侦听到没有信号能量时才开始传输帧。
1-persist CSMA,1 指等待的概率为 1,也有概率为 0 或 p 的。为 0:信道忙就睡一会再来看看
- 在传输过程中,适配器监视来自其他使用该广播信道的适配器的信号能量的存在。
- 如果适配器传输整个帧而未检测到来自其他适配器的信号能量,则传输成功;否则中止传输,等待一个随机时间然后重复第二步骤(等待信道空闲)。
- 二进制指数后退(binary exponential backoff)算法:当传输一个给定帧并经历了一连串的次碰撞后,均匀地随机地从 中选择一个间隔时间长度 。对于以太网,一个节点等待的实际时间量是 比特时间, 能取的最大值在10以内。
比特时间:传1bit所需时间
CSMA/CD效率:当有大量的活跃节点,每个节点有大量帧要发送时,帧在信道中无碰撞地传输的那部分时间在长期运行时间中所占的份额。
无线信道里无法进行 CD ,因此 802.11 选用的是 CSMA/CA(冲突避免)
轮流协议
- 轮询协议(polling protocol)
- 主站点以循环的方式轮询(poll)每个节点
- 优点:消除了碰撞与空时隙,效率更高
- 缺点:引入了轮询时延、主节点故障则信道不可操作
- 令牌传递协议(token-passing protocol,击鼓传花)
- 一个称为令牌的小的特殊帧在节点之间以某种固定的次序进行交换
- 一个节点收到令牌时,仅当它有一些帧要发送时它才持有这个令牌;否则它立即向下一个节点转发该令牌
- 缺点:一些节点的故障会导致整个信道崩溃;一个节点忘记释放令牌会使循环阻塞
DOCSIS:电缆因特网接入的链路层协议
- 数据经电缆服务接口(CMTS)规范定义了电缆数据网络体系结构机器协议
- 使用FDM将下行和上行网络划分为多个频率信道,均为广播信道;下行为单路访问,上行为多路访问
- CMTS在下行信道上通过发送称为MAP报文的控制报文,指定哪个电缆调制解调器能够在时隙中传输由报文指定的时间间隔,避免碰撞
- 电缆调制解调器在一组特殊的时间间隙内向CMTS发送时隙请求帧来向CMTS报告有数据要发送,采用随机接入方式传输,可能相互碰撞;如果在下一个MAP报文中没有收到对请求分配的响应,则可推断出遇到碰撞,采用二进制指数回退等待一段时间后重新请求
6.4 交换局域网
链路层寻址和ARP
MAC地址
- 主机和路由器不具有链路层地址
- 它们的适配器(网络接口)具有链路层地址
- 具有多个网络接口的主机具有与之相关联的多个链路层地址
- 链路层交换机并不具有与接口相关联的链路层地址(交换机交换是透明的)
链路层地址有不同的称呼:LAN地址、物理地址、MAC地址。
MAC地址长度为6字节(48位),有 个可能的MAC地址。此处假设某个适配器的MAC地址是固定的,没有两块适配器具有相同的地址(可以软件重写)。
- 适配器要发送一个帧时,将目的适配器的MAC地址插入到该帧中,并将该帧发送到局域网上。
- 若适配器需要让局域网上的其他适配器来接收并处理它打算发送的帧,将插入一个特殊的MAC广播地址
ff:ff:ff:ff:ff:ff。 - 一台交换机偶尔将一个入帧广播到它的所有接口,适配器可以接收一个并非向它寻址的帧。
- 适配器接收到一个帧时,将检查该帧中的目的MAC地址是否与它自己的MAC地址匹配。如果匹配,该适配器提取出封装的数据报并向上传递;否则丢弃该帧。
ARP 地址解析协议
网络层地址(因特网中的IP地址)和链路层地址(MAC地址)需要进行转换,对于因特网而言,这是地址解析协议(Address Resolution Protocol, ARP)的任务。ARP协议是一个跨越链路层和网络层边界两边的协议。
下面是在ARP表中添加一条记录的过程,TTL一般为20分钟。假设交换机会广播所有帧。
- 发送方构造一个称为ARP分组(ARP packet)的特殊分组,一个ARP分组有几个字段:发送、接收IP地址以及MAC地址。ARP查询分组的目的时查询子网上所有其他主机和路由器,以确定对于要解析的IP地址的MAC地址。
- 适配器封装ARP分组,用广播地址作为帧的目的地址,将帧传输进子网中。
- 目标主机给查询主机发送回一个带有所希望映射的响应ARP分组(使用标准帧而不是广播地址),然后查询主机更新ARP表,并发送IP数据报。
发送数据报到子网以外
- 每台主机仅有一个IP地址和一个适配器
- 一台路由器对它的每个接口都有一个IP地址
- 路由器的每个接口都有一个ARP模块和一个适配器
- 网络中每个适配器都有自己的MAC地址
假设子网1的网络地址为111.111.111/24,子网2的网络地址为222.222.222/24。
- 发送数据报不能使用子网2适配器的MAC地址,因为子网1没有任何适配器与之匹配
- 发送主机使用ARP获得路由器接口的MAC地址,然后创建一个帧将该帧发送到子网1中
- 子网1的路由器适配器看到该链路层是向它寻址的,将这个帧传递给路由器的网络层
- 路由器通过转发表得知转发的子网2接口,并将数据报告诉子网2的适配器,该接口使用ARP获取目标MAC地址
- 子网2接口用目标MAC地址重新封装成一个新的帧发送到子网2中
这是“缺省网关地址”方式,还有“代理ARP”方式
以太网
- 第一个广泛部署的高速局域网
- 实现简单、廉价
- 以太网的数据速率不断提高
- 以太网硬件便宜
集线器(hub):物理层设备,作用于各个比特而不是帧。收到一个bit之后重新生成(放大)并向所有接口传输出去。基于集线器的星形拓扑的以太网是一个广播局域网,同时只能有一台设备发送信息。
以太网帧结构
- 前同步码 preamble(8字节):前7字节都为
10101010,最后字节为10101011,用于唤醒接受适配器并同步时钟 - 目的MAC地址(6字节)
- 源MAC地址(6字节)
- 类型字段 type(2字节):让适配器知道需要将内容传递给哪个网络层协议(分解):IP,IPX,Apple Talk
- 数据字段(46-1500字节):承载IP数据报,若为空,则以太会强制加入46字节的PAD,凑满64字节的最小帧长度
- CRC(4字节)
使用曼彻斯特编码,包含时钟信息。用锁相环进行时钟同步。
不会有人没学过通信电子线路吧,不会吧不会吧
以太网技术向网络层提供:
- 无连接服务:发送数据报帧无需事先握手
- 不可靠服务:接收器进行CRC校验,不管是否通过都不返回确认(ACK)/否定确认(NEG)帧
最小帧长度:64字节(确保冲突检测,512bit在10Mbps下传输需要51.2μs),最大帧长度:1518字节
以太网技术
- 10BASE-T
- 10BASE-2
- 100BASE-T
- 1000BASE-LX
- 10GBASE-T
其中10:10Mbps;BASE:基带以太网(媒体仅承载以太网流量);T/2/LX:物理媒体,T为双绞铜线。
转发器(repeater):物理层设备,能够在输入端接收信号并在输出端再生该信号。
| 参数 | 10Mbps | 100Mbps | 1Gbps | 10Gbps |
|---|---|---|---|---|
| 比特时间 | 100ns | 10ns | 1ns | 0.1ns |
| 冲突窗口 | 51.2μs | 5.12μs | 4.096μs | |
| 帧间间隔 | 9.6μs | 0.96μs | 0.096μs | |
| 冲突重发次数 | 16 | 16 | 16 | |
| 冲突回退限制 | 10 | 10 | 10 | |
| 阻塞帧(冲突信号) | 4字节 | 4字节 | 4字节 | |
| 最大帧长度 | 1518字节 | 1518字节 | 1518字节 | 1518字节 |
| 最小帧长度 | 64字节 | 64字节 | 416字节(载波扩展) | 64字节 |
10Gpbs使用专线,交换机间不存在多路通信,无需CSMA
吉比特以太网(802.3z):
- 使用标准以太网帧格式
- 允许点对点链路以及共享的广播信道
- 使用CSMA/CD来共享广播信道,节点之间的最大距离必须严格限制
- 对于点对点信道,允许在两个方向上都已40Gbps全双工操作
链路层交换机
- 过滤(filtering):决定一个帧应该转发到某个接口还是应当将其丢弃
- 转发(forwarding):决定一个帧应该被导向哪个接口,并把该帧移动到哪些接口
- 交换机表:包含某局域网上某些主机和路由器的(不是全部)的MAC地址、通向该MAC的交换机接口、时间
假定目的地址为dd:dd:dd:dd:dd:dd,从接口 到达:
- 交换机表没有目的地址表项,此时交换机向除 以外的所有接口转发该帧的副本(广播)
- 交换机表有一个表项与接口 连接起来,执行过滤功能
- 交换机表有一个表项将接口 连接起来,该帧被转发到与接口 相连的局域网网段
自学习:
- 交换机表初始为空
- 对于每个接口收到的每个入帧,交换机存储源地址、接口、时间(雁过拔毛,A从1口发来数据,那以后发给A就走1口)
- 对于未知端口的目标MAC地址,交换机向除发送端口外的端口做广播(同一端口的收发不需要通过交换机)
- 如果在一段时间(老化期(aging time))后,交换机没有接收到该地址作为源地址的帧,就在表中删除这个地址
交换机是即插即用设备(plug-and-play device),因为他们不需要网络管理员或用户的干预。交换机也是双工的,任何交换机接口可以同时发送和接收。
链路层交换机的性质:
- 消除碰撞:没有因碰撞而浪费的带宽
- 异质的链路:交换机将链路彼此隔离,局域网中的不同链路能够以不同的速率运行并且能够在不同的媒体上运行
- 管理:除了提供强化的安全性,交换机也易于进行网络管理(如从内部断开异常适配器)
交换机毒化(switch poisoning):向交换机发送大量的具有不同伪造源MAC地址的分组,用伪造表项填满了交换机表,没有为合法主机留下空间。
交换器 v.s. 路由器:
- 交换机
- 即插即用,自学习
- 相对高的分组过滤和转发效率
- 必须处理高至第二层(链路层)的帧
- 对于广播风暴不提供任何保护措施
- 路由器
- 需要人为地配置IP地址,通过路由算法学习
- 当网络中存在冗余路径时,分组通常不会通过路由器循环
- 必须处理高至第三层(网络层)的帧
- 对第二层的广播风暴提供防火墙保护
通常路由器在交换机的上层,连接多个交换机
- 集线器 hub
- 一个口收到的信号,原封不动的发送给所有其他的口。
- 工作在物理层。
- 网桥 bridge
- 与 hub 相比,网桥会过滤 mac,只有目的mac地址匹配的数据才会发送到出口。
- 工作在链路层
- 交换机 switch
- 可以看做多个网桥的集成,但是也有三层交换机,即实现了部分路由功能的交换机
- 工作在链路层
- 路由器
- 基于 IP 做转发
- 工作在网络层
虚拟局域网 VLAN
- 物理位置不固定,但所属网络不变
- 大型局域网内做 ARP 或 DHCP 时会引起广播风暴,需要缩小广播范围
支持VLAN的交换机允许经一个单一的物理局域网基础设施定义多个虚拟局域网,即把交换机下的一个局域网分为多个,在一个VLAN内的主机彼此通信。 在一个基于端口的VLAN中,交换机的端口由网络管理员划分为组,每个组构成一个VLAN,在每个VLAN的端口形成一个广播域。
跨 VLAN 通信:必须经过路由器,即便这两个 VLAN 属于同一交换机。或者使用特殊的三层交换机
VLAN干线连接(VLAN trunking):(跨交换机 VLAN)
每台交换机上的一个特殊端口被配置为干线端口,以互联这些VLAN交换机。该干线端口属于所有VLAN,发送到任何VLAN的帧经过干线链路转发到其他交换机。
802.1Q帧:在以太网帧中插入了VLAN标识符(type 前)
6.5 PPP 协议
Point to Point Data Link Control
- 没有多个用户,就不需要 MAC 和 MAC 地址
- 异步传输,两帧间隔随意
- 全双工、拨号都支持
- Point to Point Protocol 或 HDLC
PPP 需求
- 成帧:把网络层报文封装到链路层帧,并且能够解封装到不同的高层协议
- 比特传输:若用户数据出现了和帧头帧尾一样的数据,需要能检测出并正确传输
- 差错检测:但是不用纠错
- 链接活性:能检测链路层的故障,并向网络层通知
- 能支持网络层的协商,自动配置 IP 地址
PPP 帧格式
套用了HDLC的帧格式
- 帧头帧尾各 1 字节:都是 01111110(7e)
- 地址全 1:点到点了你要啥地址啊
- 控制字段固定:不实现差错控制
- 协议字段 1 或 2 字节:高层协议
- 用户数据
- CRC:2 或 4 字节
字节插入
为了允许用户发送 01111110,在用户发送的 01111110 前无条件插入 01111101(7d)。
为了允许用户发送 01111101,在用户发送的 01111101 前无条件插入 01111101(7d)。
接收方看到一个 7d,就把其看作转义字符,而其后的是用户数据。
PPP Data Control Protocol
- LCP(Link Control Protocol):配置 PPP 连接
- NCP(Network Control Protocol)
PPP 认证
PPPoE:PPP over Ethernet
6.6 链路虚拟化:网络作为链路层
- 多协议标签交换
- 标签交换路由器
- 流量工程
- 虚拟专用网
将不同的物理层的网络连接起来的技术,IP over Everything

ATM 异步传输模式
Asynchronous Transfer Mode,目标是取代 TCP/IP 和有线电视等等,现在只是一种链路层
使用固定报文长度 cell switch,加速硬件处理
由于 ATM 目标过于雄伟,QoS要求太高,成本异乎寻常的高
MPLS 多协议标签交换
Multiprotocol Label Switching,2.5 层,现在用于加快 IP 转发的查找速度
在 PPP 头 和 IP 头 之间增加一个 MPLS 头
- label 20字节:为了正确转发
- Exp 3字节
- S 1字节
- TTL 5字节
支持 MPLS 的路由器
- 原有 IP 转发:若目的地址一样,则路径一样
- MPLS:不仅根据目的地址选择路径,还根据源地址选择不同的路径——流量工程
- 修改 link-state 等路由协议
- 还要使用资源预约协议
MPLS 转发表:
| in label | out label | dest | out interface | 解释 |
|---|---|---|---|---|
| 10 | A | 0 | 接收到label为10的数据,送往0号端口 | |
| 9 | A | 1 | ||
| 8 | 6 | B | 2 | 接收到label为8的数据,将其label替换为6,送往2号端口 |
就不用最长前缀匹配了
6.7 数据中心网络
- 数据中心网络
- 刀片(blade)
- 机架顶部(Top of Rack, TOR)交换机
- 边界路由器
- 数据中心网络设计
- 负载均衡器
- 路由器和交换机体系结构
- 全连接拓扑
- 模块化数据中心
6.8 回顾:Web页面请求的历程
- DHCP、UDP、IP、以太网
- DNS、ARP
- 域内路由选择到DNS服务器
- TCP、HTTP
- DHCP:获取 IP
- 客户端:dst:255.255.255.255:67, src:0.0.0.0:68
- 服务器:dst:255.255.255.255:68
- DHCP->UDP->IP->Eth->Phy
- 路由器根据以太网帧里的type,取出 IP 报文,做转发
- 根据 IP 报文里的 protocol,取出 UDP 报文
- DHCP discover, offer, request, ACK
- ARP:从 IP 到 MAC
- DNS:域名到 IP
- 目标MAC为缺省网关的
- 建立 TCP 连接
- HTTP request / reply
网页
模电小结
1 晶体二极管
直流通路:信号源短路,耦合电容开路
交流通路:直流电源短路,耦合电容短路
1-1 半导体物理基础知识
热平衡载流子浓度值
热平衡条件:
电中性方程:掺杂低价离子时:为掺杂浓度
空穴,自由电子
电场:漂移电流;浓度差:扩散电流
1-2 PN结
内建电位差:,其中热电压,室温下约为26mV
伏安特性:,S:反向饱和(Saturate),I、V在二极管中常有下标D(Diode)
此处
-1或变换后的+1常忽略
1-3 晶体二极管电路的分析方法
伏安特性曲线在导通电压后以的斜率上升
小信号模型-交流模型:串联一个微变电阻(增量结电阻/肖特基电阻)====,与静态工作点有关,此模型下的电流
1-4 晶体二极管的应用
轮流假设各管导通或截止
1-5 其它二极管
齐纳二极管
又称稳压二极管,工作在反向击穿区
相当于小信号模型中的电阻
可将波动的输出范围视作源
可靠击穿即电流足够大
2 晶体三极管
2-1 晶体三极管的工作原理
共基极直流电流放大系数:
共射极直流电流放大系数:
穿透电流:
- 放大模式:发射结加正向电压,集电结加反向电压,
- 饱和模式:均正偏,(掺杂浓度不同)
- 截止模式:均反偏
基区宽度调制效应:集射电压变化导致基极电流变化
2-2 晶体三极管模型
共射大信号电路
放大模式:只考虑发射结电压,其余按电流关系
饱和模式:考虑发射结电压和集电结电压()
- 放大模式:输入端接正向电压源(相当于半导体大信号模型中的电压源。即正向导通电压),输出端接正向受控电流源(相当于EM模型中的电流源),发射极为负端
- 饱和模式:输入端、输出端都接正向电压源,都约为正向导通电压
- 截止模式:输入端、输出端都断路
小信号-混合π型微变等效电路
简化:
- 忽略、
- 低频时:忽略、
:反映三极管的放大能力
跨导
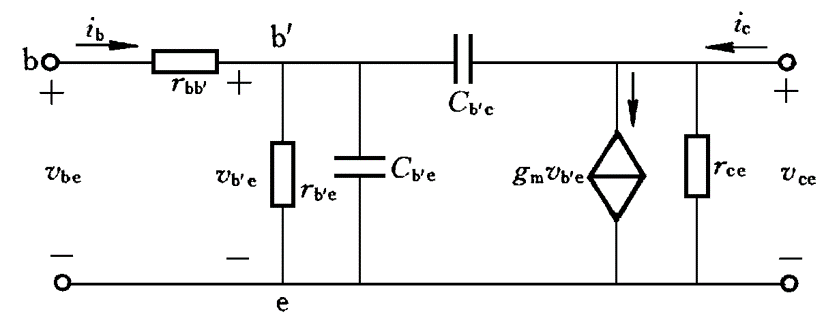
NPN和PNP的小信号模型一样
频率参数
特征频率:β为1时对应的频率
截止频率:β为最大时的0.707时对应的频率
2-3 三极管电路分析方法
先假设为放大模式,然后求证明成立
2-4 三极管应用原理
分压式偏置电路
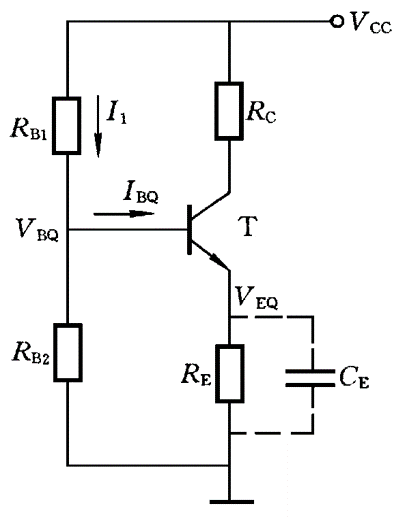
放大模式:
- (由戴维宁)
- (由戴维宁)
跨导线性环电路
偶数个BE结环状相接,其中一半按顺时针方向,另一半按逆时针方向,则所有环中顺时针集电极电流之积等于逆时针集电极电流之积。
,i为集电极电流,S为发射结面积
3 场效应管
3-1 绝缘栅场效应管MOSFET
N:箭头向内。箭头方向:PN结正偏时正向电流方向
衬偏效应:衬底和源极间有电压差
EMOS(Enhancement)
N沟道:;P沟道相反
DMOS(Depletion)
N沟道:;P沟道相反
在生产时已经制作了沟道,因此时就有沟道
非饱和区:
- 很小时:
- 计及沟道长度调制效应时:(源漏电压差导致漏极电流变化)
 计及沟道调制效应
计及沟道调制效应
饱和区:
饱和区小信号电路模型:,在ds间接一个电阻
非饱和区小信号电路模型:
| N沟道 | P沟道 | |
|---|---|---|
| 非饱和区 | ||
| 饱和区 |
n沟道中所有不等号取反即是p沟道
3-2 结型场效应管
非饱和区:
饱和区:
饱和区计及沟道长度调制效应:
截止区:
击穿区:随着增加,近漏端PN结发生雪崩击穿,越负,越小
电路模型与MOS管一致
3-3 场效应管应用原理
有源电阻
N沟道EMOS:GD相连
交流阻值:
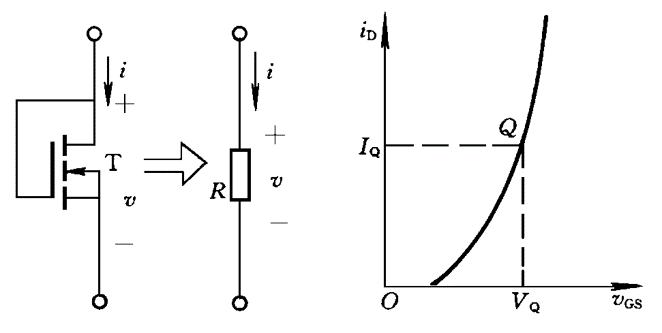
N沟道DMOS:GS相连
交流阻值:
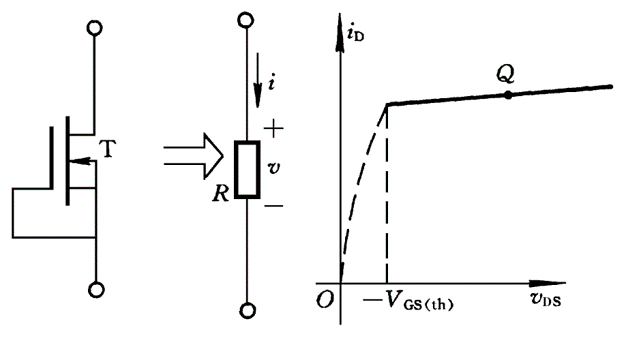
逻辑门电路
N沟道MOS等效为栅压高时闭合的开关
P沟道MOS等效为栅压高时打开的开关
4 放大器基础
增益方向!
4-1 放大器的基本概念
负载开路时
负载短路时
源增益:,必须用分压算!
输入电阻:输入电压除以输入电流考虑负载)
输出电阻:移除信号源,不考虑负载从负载看到的等效电阻
:不考虑等与负载并联的电阻
有时考虑用电流增益算电压增益
能利用三极管放大就用
vt:三极管;:三极管自身电压增益
4-2 基本放大器
| 性能 | 共源 | 共栅 | 共漏 |
|---|---|---|---|
| 性能 | 共射 | 发射极接电阻的共射 | 共基 | 共集 |
|---|---|---|---|---|
共基:发射极为输入端正极,基极接地
共集:基极作为输入端正极
要点:电流源两端不能接信号源
共射放大器
基本共射放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
有源负载放大器
- 电压增益:
发射极接电阻的共射放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
集成MOS放大器
E/E和E/D MOS放大器:只用N型,负载实质为纯电阻
- E/E:放大器和负载均为EMOS
- E/D:放大器为EMOS,负载为DMOS
4-3 差分放大器
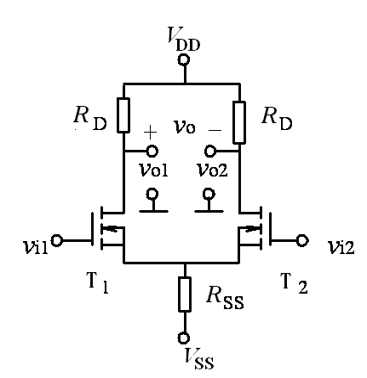
共模信号:两信号和的一半,即均值
差模信号:两信号差
为两端输入之差,因此差模输入电阻要算两倍
差模等效电路
对差模信号而言,可视为短路。
性能指标定义
- 双端增益
- 单端输出时差模电压增益
- 差模输入电阻(常为两倍)
- 差模输出电阻:单端输出时,为放大器任一输出端到地的输出电阻,而双端输出电阻则是以两端向放大器看过去的输出电阻,即为两放大器输出电阻之和。(将输入电压短路)
- 共模增益
- 共模抑制比:
指标计算
- ,即差模输入的一半的峰值必须保证管子仍处于放大
| 差模 | 共模 |
|---|---|
共模等效电路
对共模信号而言,相当于接入。
双端共模增益为零
双极型差模增益
4-4 电流源电路及其应用
镜像电流源
基本镜像电流源电路
T1接成二极管,T2接成电流源
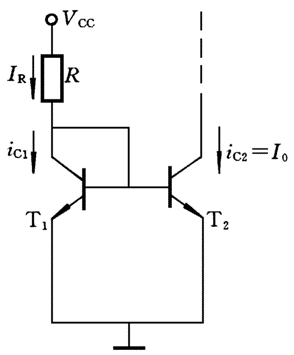
4-5 多级放大器
划分为多个常见电路模型
4-6 放大器的频率响应
复频域分析方法
一个独立电抗元件对应一对极零点
幅频:波特图为20lg
真实:s换为jω
波特:近似为20dB
遇到零点则斜率加,遇到极点则斜率减,最后叠加/求和
相频:
从开始非0,单极点斜率为-45°
中频增益:将传递函数写为一极一零连乘形式,利用高低通特性将传递函数化为常数
上限频率:
- 根据定义:
- 多极无零系统:,主极点是n重极点时:
- 重极点:,n为极点个数
- 用主极点近似求解
主极点:
- 低频主极点:比其它极点值都大4倍以上
- 高频主极点:比其它极点值都小4倍以上,又称主极点
共源、共发放大器的频率特性
密勒定理
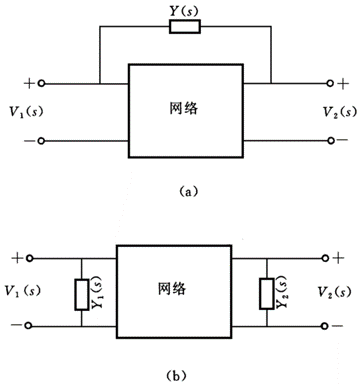
图(a)为输入输出端跨接阻抗Z(s)(或Y(s)=1/Z(s))的网络,它可以用图(b)来等效: ,其中A(s)=V2(s)/V1(s),即Y(s)可以用分别并接在输入输出端的导纳Y1(s),Y2(s)来代替
中频增益即小信号等效电路的电压增益(20lg)
| 放大器 | CS | CE |
|---|---|---|
| 密勒效应D因子 | ||
| 单向化近似条件 | ||
| 电容 | ||
| 电阻 |
5 放大器中的负反馈
5-1 反馈放大器的基本概念
输出信号
反馈系数
误差信号
反馈放大器的增益(闭环增益):
环路增益,反馈深度
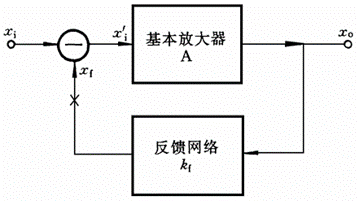
反馈网络的输入端在原输出端侧
四种类型负反馈放大器
电压型:输出端并联;电流型:输出端串联
并联型:输入端并联,接电流源;串联型:输入端串联,接电压源
反馈信号类型一定与输入信号类型一致。
类型判别
分别短路输入输出
- 短路输入时,若反馈网络的输出对放大器产生影响,如,则为串联
- 短路输出时,若反馈网络有输入,则为电流
简化:
- 与输出连:电压
- 与输入连:并联
极性判别
极性主要指增益的正负
削弱净输入信号的为负反馈,增强净输入信号的为正反馈,即的正负
在闭合环路的任一处断开,并在此处假定信号极性,而后不考虑信号源,按顺时针判定信号流经该闭合环路时电压极性的转换,直到返回断开点。 若此时极性与假设相同,则为正反馈。
顺时针指先经过放大器输入,到输出,再到反馈网络输入,到输出。
经过 地 时反相,经过 * 电阻* 时不变
5-2 负反馈对放大器性能的影响
串联负反馈:输入端是基本放大器的输入与反馈网络的输出串联连接,故输入电阻增加到基本放大器输入电阻的F倍
增益及其稳定性
源电压增益:
增益灵敏度:
输出电阻
- 输出阻抗低适合输出电压
- 输入阻抗低适合输入电流
失真和噪声
| 反馈类型 | 输入阻抗 | 输出阻抗 | 类型 |
|---|---|---|---|
| 电压串联负反馈 | 电压增益 | ||
| 电压并联负反馈 | |||
| 电流串联负反馈 | |||
| 电流并联负反馈 | 电流增益 |
5-3 负反馈放大器的性能分析
拆环方法:
- 考虑反馈放大器输入时,将反馈网络的输出
- 电压:短路
- 电流:开路
- 考虑反馈放大器输出时,将反馈网络的输入
- 并联:短路
- 串联:开路
电压:假设输出电流 电流:假设输出电压 并联:假设输入电流 串联:假设输入电压
假设网络的输入、输出电流,并用电压来表示之,最后将电流搬回放大器,得到反馈系数
深度负反馈
深度负反馈条件
或
6 集成运算放大器及其应用电路
6-1 集成运算电路
6-2 集成运放应用电路的组成原理
理想化条件
虚短虚断
基本应用电路
- 反相放大器,为负向端到地间电阻
- 同相放大器,时构成同相跟随器
闭环应用
加法和减法电路
| 反相加法器 | 同相加法器 |
|---|---|
,其中、、、并联 | |
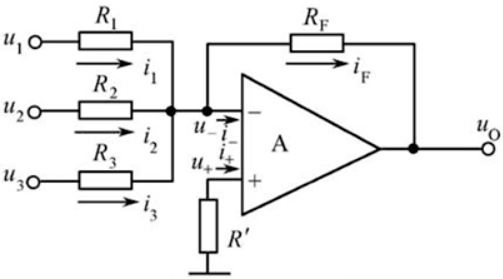 | 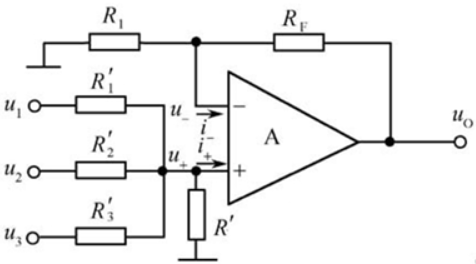 |
| 加法器实现的减法器 | 差动减法器 |
|---|---|
当时, | |
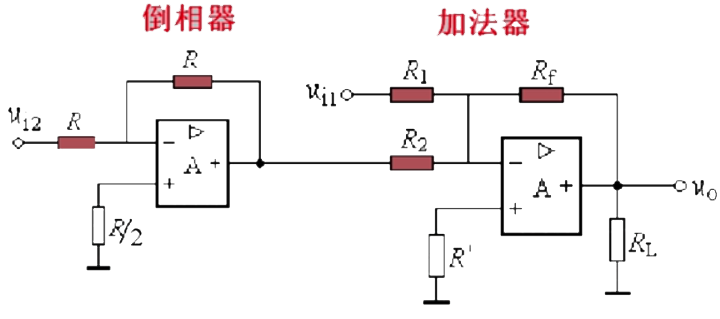 | 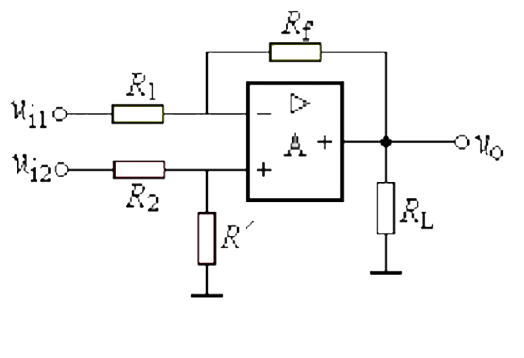 |
| 积分运算电路 | 微分运算电路 |
|---|---|
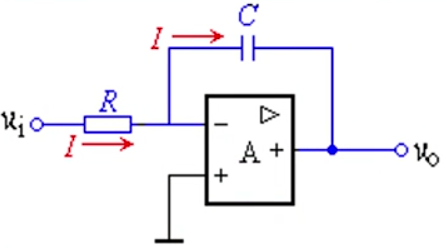 |  |
| 对数运算电路 | 指数运算电路 |
|---|---|
| ,其中 | |
 |  |
有源滤波器
可以带负载,可以提供增益
| 带通 | 带阻 |
|---|---|
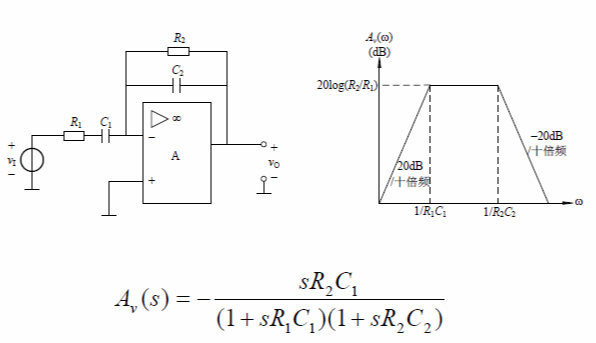 | 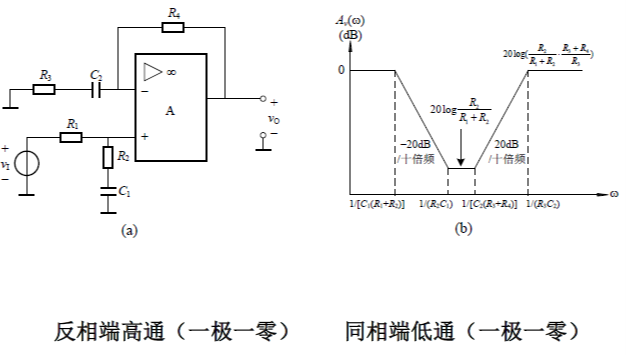 |
开环应用
| 电压比较器 | 单限电压比较器 |
|---|---|
| 时输出高电平 | |
 | 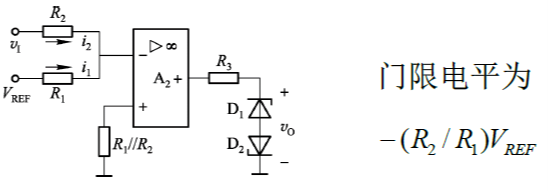 |
迟滞比较器
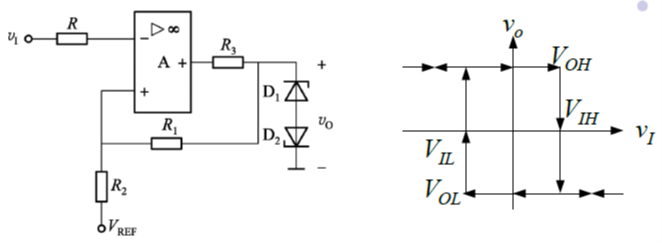
先求输出范围,再通过电路求输入范围
输入接电容:方波发生器
电流方向
模电 上
1 晶体二极管
1-1 半导体物理基础知识
热平衡载流子浓度值
热平衡条件:
电中性方程:掺杂低价离子时:为掺杂浓度
N型半导体(Negative)
在本征半导体中掺入5价杂质原子形成,空穴浓度远高于电子浓度
- 多数载流子(多子):自由电子,由杂质原子提供,因此此处杂质原子又称施主杂质(Donor)
- 少数载流子(少子):空穴,由热激发形成
P型半导体(Positive)
在本征半导体中掺入3价杂质原子形成,电子浓度远高于空穴浓度
- 多子:空穴,易俘获电子,使杂质原子成为负离子,因此此处杂质原子又称受主杂质(Acceptor)
- 少子:电子
1-2 PN结
本征半导体两侧分别形成P、N型半导体
{% mermaid %} graph TB A[浓度差] --> B[多子扩散]; B --> C[由杂质离子形成空间电荷区]; C --> D[空间电荷区形成内电场]; D --> E[内电场促使少子漂移]; D --> F[内电场阻止多子扩散] {% endmermaid %}
多子扩散(浓度差)和少子漂移(电场力)形成动态平衡,离子薄层形成空间电荷区,由于缺少多子,又称耗尽层、阻挡层、势垒区
内建电位差:,其中热电压,室温下约为26mV
阻挡层宽度:,N为多子浓度
-
正偏:加正向电压,P区电位高于N区
-
反偏:加反向电压,P区电位低于N区
-
正偏时,内电场被削弱,扩散运动加剧,漂移电流可忽略,PN结呈低阻性,导通
-
反偏时,内电场被增强,扩散运动减弱,扩散电流可忽略,PN结呈高阻性,截止
伏安特性
==伏安特性:==
正向特性:
- 导通电压:小于该电压时电流几乎为0,大于该电压时电流按指数增长
反向特性:
- 反向击穿电压(为负):大于该电压时电流几乎为0,小于该电压时二极管被击穿
反向恢复过程(导通->截止):截止前电流会突然反向,,该段时间称为存储时间,随后电流逐渐归零,称为渡越时间,总称反向恢复时间
减小存储时间的方法:
- 结面积尽可能小
- 正向电流不要过大,防止积累过多载流子
- 反向电压大一些,只要不超过击穿电压
二极管开通时间(截止-导通):忽略不计
电击穿
逐步增大反向电压至足够大时,会使反向电流急剧增加
可恢复击穿:
- 齐纳击穿:掺杂浓度较高,耗尽层较窄时形成,此时较低的反向电压即可形成强电场破坏空穴对
- 雪崩击穿:耗尽层较宽时形成,此时高电压形成电子-空穴对,使载流子雪崩式倍增
温度特性
温度每升高10℃,约增加一倍
正偏时,近似于温度每升高10℃,约减小2.5mV
温度升高时,雪崩击穿电压变高,齐纳击穿电压变低
电容效应
势垒电容:离子薄层的变化,导致存储电量变化
扩散电容:多子扩散后,在PN结的另一侧积聚而成
正偏时,势垒电容可忽略;反偏时,扩散电容可忽略
开关特性
1-3 晶体二极管电路的分析方法
结构:PN结+引线+管壳,正极为P区,负极为N区
主要参数
- 最大整流电流
- 反向击穿电压
- 最大反向工作电压:一般按反向击穿电压的一半计算
- 反向电流:一般时最大反向工作电压下的反向电流值,又称反向饱和电流
- 最高工作频率
- 结电容
- 正向压降
- 动态电阻:交变信号下的等效电阻,与工作电流大小有关
- 静态电阻
数学模型
电路模型
理想模型-直流模型:不考虑开启电压、导通电压等。全黑或戴框的二极管表示理想。电源电压远比二极管的压降大时适用。
恒压降模型-直流模型:导通后管压降视为恒定。理想二极管串接一个电压源。二极管电流不小于1mA时适用。一般认为压降为0.7V
折线模型-直流模型:串接一个等效于门槛电压的电池和一个等效于管压降随电流线性增加的电阻
小信号模型-交流模型:串联一个微变电阻(增量结电阻/肖特基电阻),与静态工作点有关,此模型下的电流
分析方法
图解分析法:
- ,其中为直流电源
- 作出两方程所对应的曲线,求其交点
等效电路分析法:使用对应的电路模型
1-4 晶体二极管的应用
整流电路
即:仅选通正向电流
稳压电路
使用反向击穿后的二极管,即稳压二极管,使得不管电流多少,电压始终稳定在
限幅电路
上门限
下门限
钳位电路
用于将周期性信号的峰值固定在某直流电位上
正峰钳位电路
与门
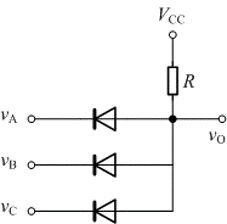
或门
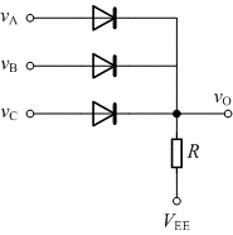
1-5 其它二极管
齐纳二极管
又称稳压二极管
工作在反向击穿区
主要参数:
- 稳定电压:与反向击穿电压相等
- 动态电阻:该电阻越小,稳压特性越好
- 最大耗散功率:反向工作时有
- 最大稳定电流:取决于最大耗散功率
- 最小稳定电流:取决于最小工作电压
- 稳定电压温度系数α:稳压管工作电流不变时,每升高一度所引起的稳定电压变化的百分比,
- 稳定电压值时,α为正,反向击穿为雪崩击穿
- 稳定电压值时,α为负,反向击穿为齐纳击穿
- 稳定电压值时,α接近0,稳压管可作为标准稳压管使用
使用小信号模型分析输入电压变化量对输出电压的影响
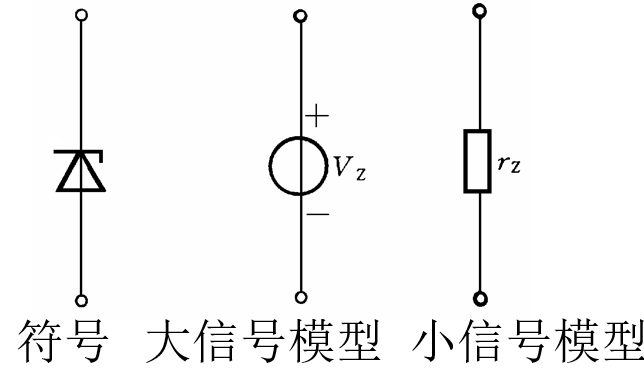
光电二极管
符号:箭头入射
发光二极管
符号:箭头出射
2 晶体三极管
2-1 晶体三极管的工作原理
双极性半导体三极管:简称三极管,有两种载流子参与导电,由两个PN结组合而成,是CCCS器件
场效应半导体三极管:简称场效应管,仅有一种载流子参与导电,又称单极性器件,是VCCS器件
三极管结构
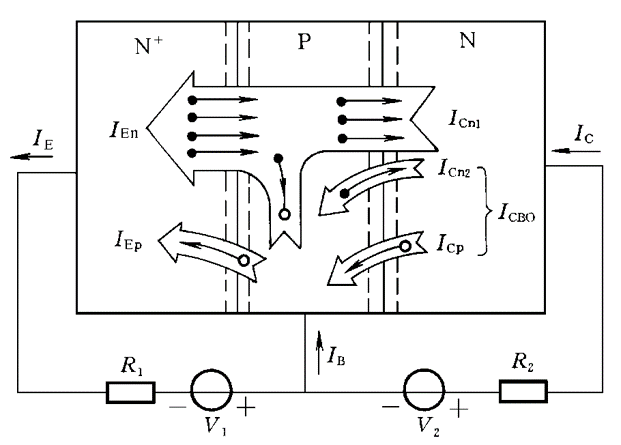
发射极Emitter,基极Base,集电极Collector
NPN型
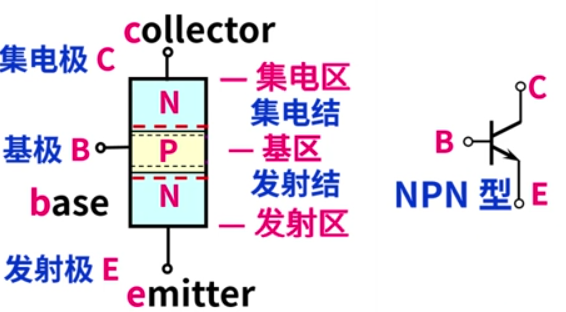
PNP型
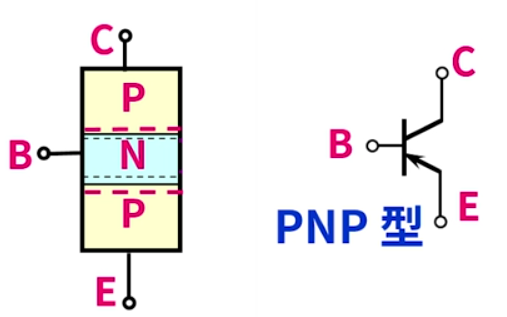
发射区掺杂浓度大,集电区掺杂浓度小,且基区很薄,集电结面积大,
工作时一定要加上适当的直流偏置电压
-
放大模式:发射结加正向电压,集电结加反向电压
-
饱和模式:均正偏,
-
截止模式:均反偏
-
发射区发射载流子
-
基区传送载流子(扩散和复合)
-
集电区收集载流子
电流关系
组态:三极管必有一个输入,一个输出,一个公共(既输出又输入),由此有三种组态
- 共发射极接法CE:发射极作为公共电极,发射极同时存在于输入、输出端口,基极为输入
- 共基极接法CB:基极作为公共电极,发射极为输入
- 共集电极接法CC:集电极作为公共电极,基极为输入
只有发射极和基极可作输入,只有发射极和集电极可作输出,公共端除外
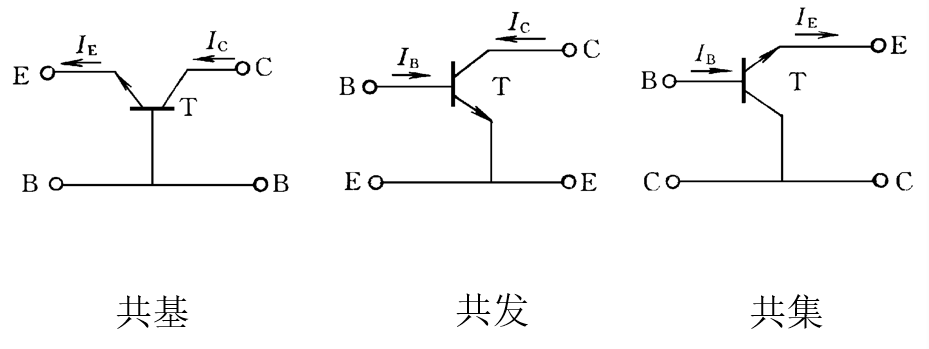
==令==,称为共基极直流电流放大系数,表示转化为的能力,有但接近1
同理,====,称为共发射极直流电流放大系数,有
可知
穿透电流:每升高一度,穿透电流增大一倍。O:第三极开路
2-2 晶体三极管模型
认为基极和发射极间电压差为0.7V
埃伯尔斯-莫尔模型(Ebers-Moll)
把两个PN结分别看作一个二极管与一个受控电流源的并联,其中一个PN结的α为另一个PN结的放大系数,电流源大小为
(Forward)表示(与发射极电流同向的)流过发射结的电流,(Reverse)表示(反向的)流过集电结的电流
饱和模式:三极管两个结均正偏,此时保留所有等效元件
放大模式:发射结正偏,集电结反偏,此时仅保留发射结对应的二极管和集电结对应的电流源
截止模式:三极管两个结均反偏,此时所有等效元件断路
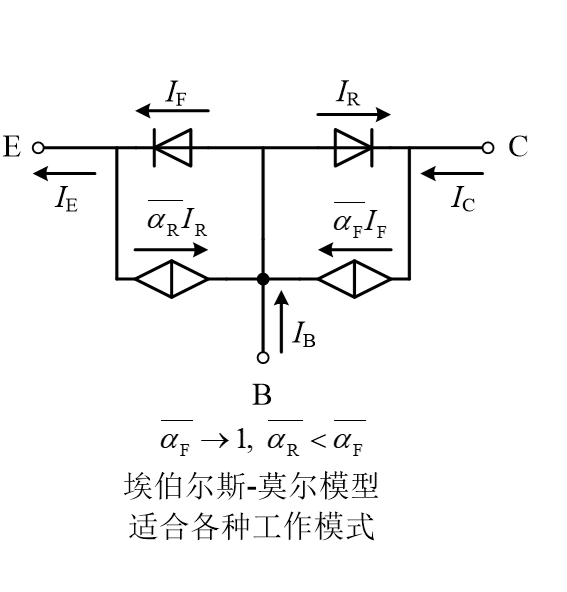
共射等效电路大信号模型
- 放大模式:输入端接正向电压源(相当于半导体大信号模型中的电压源。即正向导通电压),输出端接正向受控电流源(相当于EM模型中的电流源),发射极为负端
- 饱和模式:输入端、输出端都接正向电压源,都约为正向导通电压
- 截止模式:输入端、输出端都断路
交流小信号模型-线性模型
- 直流量:大写字母,大写下标
- 交流量:小写字母,小写下标
- 总瞬时量:小写字母,大写下标
放大模式:输入端接输入电阻,输出端接正向受控电流源
跨导:反映三极管的放大能力
有
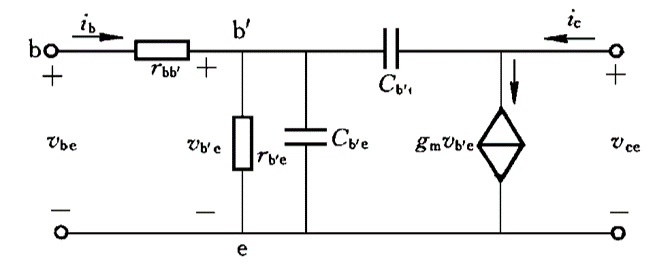
即π型等效电路
只有高频工作时要考虑结电容,否则电容视作断路
若不考虑基极引线电阻和基区体电阻时
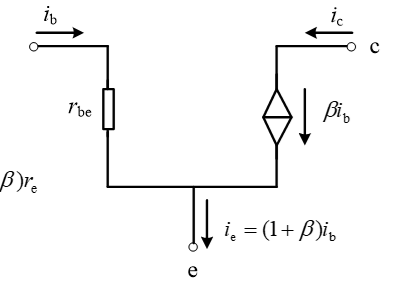
NPN和PNP的小信号电路模型一样
混合π型微变等效电路
简化:
- 忽略、
- 低频时:忽略、
参数计算
:基区的体电阻,b'为假想点
:发射结电阻
:归算到基极回路的电阻
:发射结电容,又作
:集电结电阻
:集电结电容,又作
以下以NPN共射组态为例
输入特性曲线
- 时,与二极管特性相近
- 时,集电结进入反偏状态,三极管处于放大状态,特性曲线将略向右移(右移是由于基区宽度调制效应:集电结阻挡层宽度增大,基区宽度减小)
输出特性曲线
- 时,集电极无收集作用,,饱和区
- 稍增大时,与之正相关,线性放大区
- 再增大时,不再明显变化,体现基区宽度调制效应,截止区
为厄尔利电压
开关特性
截止状态、饱和状态可模拟开关
集电极饱和电流:
基极临界饱和电流:
开通时间:
关闭时间:
2-3 三极管电路分析方法
先假设为放大模式,然后求证明成立
图解分析法
将电路分为
- 晶体三极管
- 输入端管外电路
- 输出端管外电路
直流分析:分别在三极管输入、输出特性曲线上作管外电路方程代表的输入、输出负载线,交点即为直流工作点。
交流分析
等效电路分析法
求三极管基极开路电压和短路电阻
:相当于把折算到基极
交流分析:
- 先求工作点电流
直流参数
直流电流放大系数:
- 共射接法直流电流放大系数:在放大区基本不变。
- 共基接法直流电流放大系数
极间反向电流:
- 集电极基极间反向饱和电流
- 集电极发射极间反向饱和电流
交流参数
交流电流放大系数:
- 共射接法交流电流放大系数:在放大区基本不变,近似等于直流β,故后续只考虑交流β。β随频率变化
- 共基极接法交流电流放大系数
特征频率:β为1时对应的频率
频率参数
- 为特征角频率
极限参数
集电极最大允许电流:集电极电流增加时β会下降,当β达到线性放大区β值的2/3时所对应的集电极电流即为集电极最大允许电流
集电极最大允许功耗
反向击穿电压:
- :Breakdown、集电极、基极、发射极开路
- :基极开路时集电极和发射极间的击穿电压
2-4 三极管应用原理
电压源
放大器

偏置电路
- 输入工作点偏低:截止失真——信号最小值低于0V
- 输入工作点偏高:饱和失真——信号最大值高于VCC
分压式偏置电路
跨导线性环电路
偶数个BE结环状相接,其中一半按顺时针方向,另一半按逆时针方向
TTL电路
3 场效应管
按参与导电的载流子,可分为:N沟道器件、P沟道器件
按结构分:结型场效应绝缘管JFET,绝缘栅型场效应管IGFET/MOSFET
判断:
- N沟道:(为形成源到漏的电流)
- MOS:极性相同
3-1 绝缘栅场效应管MOSFET
增强型-EMOS、耗尽型-DMOS分别有N、P沟道两种
增强型:虚线;耗尽型:实线
箭头方向:PN结正偏时正向电流方向
栅极靠近源极
源极/漏极可互换
栅长:l;栅宽:w
EMOS工作原理
N型:漏源电压为正;P型:漏源电压为负
源极、漏极接N+,栅极接N沟道
为正,使得电子被吸附到P衬底,最终将部分P型转为N型,形成沟道
为正,使得沟道中靠近漏极的电压较小,靠近漏极的沟道较窄,易夹断
栅源电压的控制作用:时,沟道才形成,MOS管才导通,称为开启电压。
- 越大,导电沟道越深
- N区掺杂浓度越高,衬底掺杂浓度越低,越小
漏源电压对漏极电流的控制作用:
- 且固定时,当增加到使时,沟道截止,预夹断区加长,DS间电流趋于饱和
- 时,继续减小,最终DS间电流为0,此时称为夹断电压,用表示
EMOS特性
伏安特性(P、N均成立)
- 非饱和区:
- 饱和区:
==== - 截止区:
- 击穿区:过大引起雪崩击穿和穿通击穿,过大引发栅极击穿
- 亚阈区:极小
转移特性曲线:漏源电压固定时,漏极电流与栅源电压间的关系。其斜率反映了栅源电压对漏极电流的控制作用,称为跨导
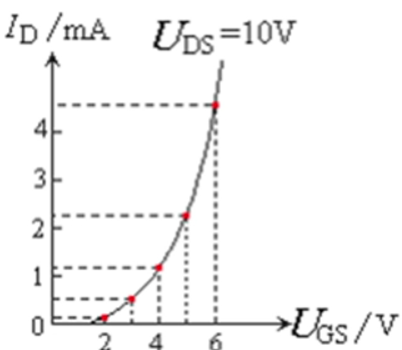
衬底效应
若源极不在电路的最低电位,则源极与衬底无法在沟道夹断后相连,其间就会有负的,P型硅衬底中的空间电荷区将向衬底底部扩展,相应增大。在一定时,就减小。可见也可控制故又称衬底电极为背栅极,不过它的控制作用很小。
DMOS
在生产时已经制作了沟道,因此时就有沟道
伏安特性
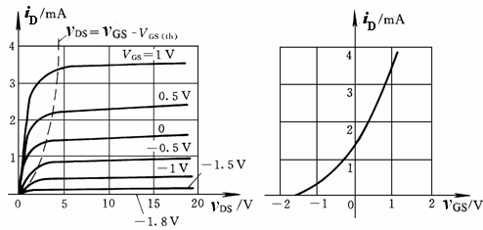
主要参数
开启电压:是MOS管的参数
夹断电压:是JFET的参数
饱和漏极电流:是耗尽型场效应管的参数
输入电阻
低频跨导
最大漏极功耗
常量
电路模型
大信号:
- 非饱和区:
- 饱和区:,λ:沟道长度调制效应参数,不考虑时取0
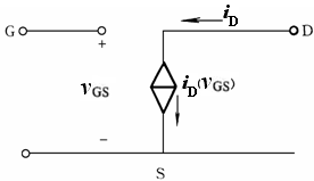
小信号模型
-
饱和区小信号模型:
-
计及沟道长度调制效应:在ds间接一个i而电阻
-
考虑衬底效应:在上一个模型的基础上在ds间接的电流源,方向与原有的相同,
-
高频小信号模型:
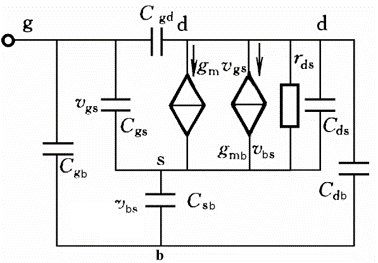
- 源极与衬底相连时:
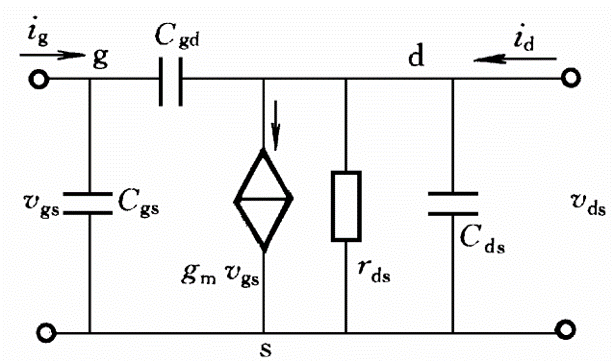
MOS管截止频率:
非饱和区小信号模型:
3-2 结型场效应管原理
结型场效应三极管的结构
N、P互换,成为P沟道场效应管,箭头从P到N
- g:gate
- d:drip
- s:source
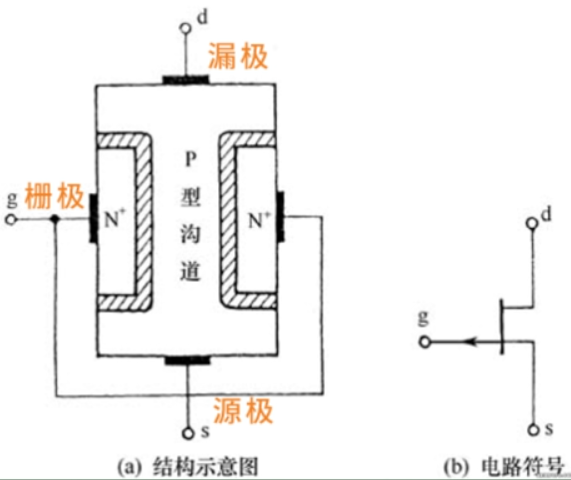
结型场效应三极管的工作原理
栅源电压对沟道的控制作用:越小,(沟道的)耗尽层越厚,最终将沟道全部耗尽,三极管截止
漏源电压对沟道的控制作用:时,靠近漏端的沟道耗尽,但靠近源极的沟道并没有,继续增大,沟道继续耗尽,漏极电流趋于饱和
结型场效应三极管的特性曲线
漏极输出特性曲线
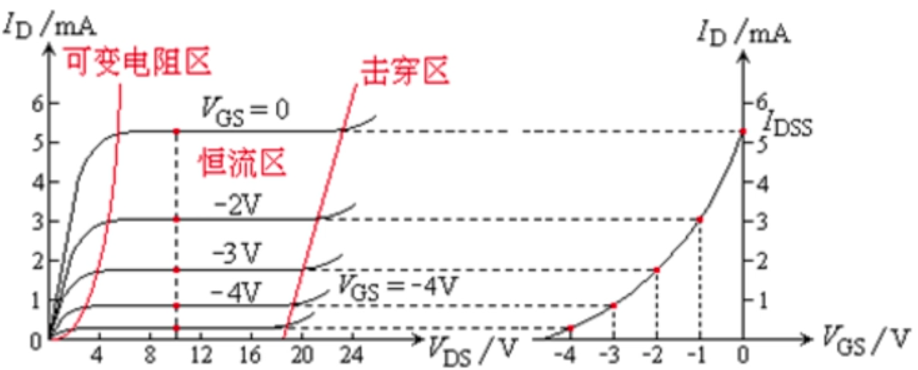
非饱和区:
饱和区:
饱和区计及沟道长度调制效应:
截止区:
击穿区:随着增加,近漏端PN结发生雪崩击穿,越负,越小
比较
| 晶体三极管 | 场效应三极管 | |
|---|---|---|
| 结构 | NPN型、PNP型 | 结型耗尽型 N/P |
| ^ | C与E一般不可互易 | 绝缘栅增强型 N/P |
| ^ | ^ | 绝缘栅耗尽型 N/P |
| ^ | ^ | 有的型号D与S可以互易 |
| 载流子 | 多子扩散,少子漂移 | 多子漂移 |
| 输入量 | 电流输入 | 电压输入 |
| 控制 | CCCS,β | VCCS, |
| 噪声 | 较大 | 较小 |
| 温度特性 | 受温度影响大 | 较小,可有零温度系数点 |
| 输入电阻 | 几十到几千欧姆 | 几兆欧姆以上 |
| 静电影响 | 不受静电影响 | 易受静电影响 |
| 集成工艺 | 不易大规模集成 | 易大规模/超大规模集成 |
3-3 场效应管应用原理
有源电阻
N沟道EMOS:GD相连
交流阻值:
N沟道DMOS:GS相连
交流阻值:
有源电阻组成的分压器:
MOS开关
NMOS开关:
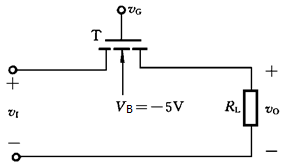
CMOS开关:
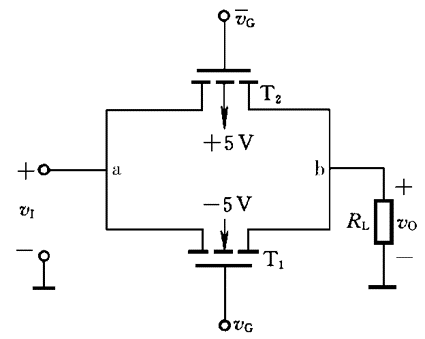
逻辑门电路
NMOS看作栅极高时断开的开关,PMOS看作栅极低时断开的开关。
CMOS反相器:

CMOS或非门:

CMOS与非门:

CMOS传输门:

锁存器:

模电 中
4 放大器基础
由一个三极管与相应库组成的基本组态放大电路
4-1 放大器的基本概念
字母小写,下标大写:瞬时信号,即交流信号+直流信号
放大的原理和实质
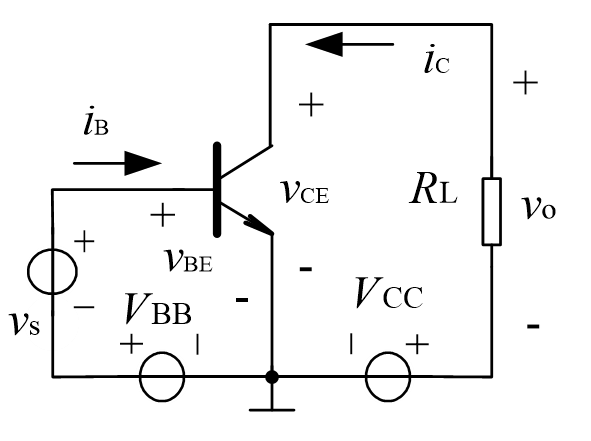
小信号:变化幅度足够小,可以看作在工作点处呈线性
放大对象:微弱、变化的信号,又称交流小信号
放大的实质:由直流能转为交流能
功能分类:电压增益、电流增益、跨阻增益、跨导增益
放大器的性能指标
输入电阻:若放大器之前为另一级放大器,则该输入电阻为前一级的负载
输出电阻:
开路电压:,短路电流:
小信号放大器电路一般模型:为移除负载的输出电压,为负载短路的输出电流
对输入、输出电阻的要求:尽量使输入、输出不变
- 输入电压时,
- 输入电流时,
- 输出电压时,
- 输出电流时,
增益
- 电压增益
- 电流增益
- 互导增益
- 互阻增益
- 增益转换
不可用增益间互相推导
负载开路时
负载短路时
源增益:
频率响应
具有电抗元件的放大器的增益是频率的复函数:
失真
中频区增益下降到倍或3dB所对应的频率分别称为上限频率和下限频率,并把差值称为通频带
线性失真:频率失真
- 幅度失真
- 相位失真
线性失真:瞬变失真:由于电抗元件电压电流无法突变而引起的失真
非线性失真:由半导体的伏安特性非线性引起,产生了新的频率分量
4-2 基本放大器
分类:
- 双极型:共发射极、共集电极、共基极
- 场效应:共源极、共漏极、共栅极
区别:
- 双极型有源极电流,必须用戴维宁定理
- 场效应管没有栅极电流,直接分流
:不考虑
共源放大器
- 输入电阻:
- 输出电阻:
- 电压增益:
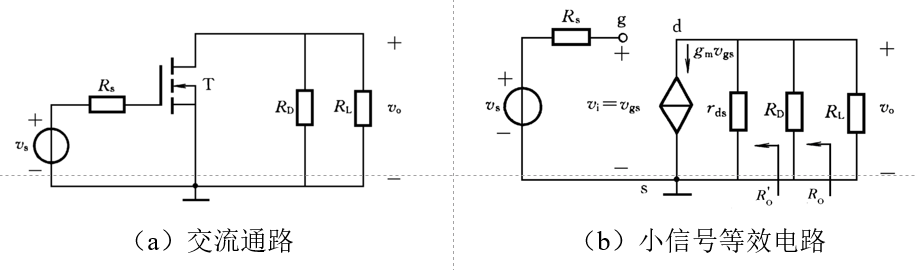
- 静态工作点:直流通路,电容断路。用于求跨导
- 电路性能:交流通路,电容短路,直流电压接地。用于求输入、输出电阻和增益
共栅放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
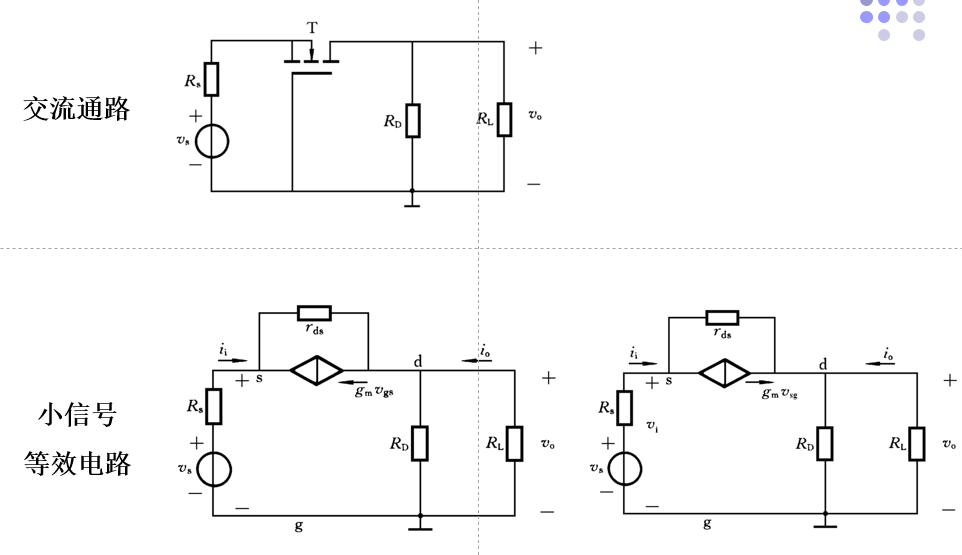
共漏放大器
- 输入电阻:
- 输出电阻:
- 电压增益:
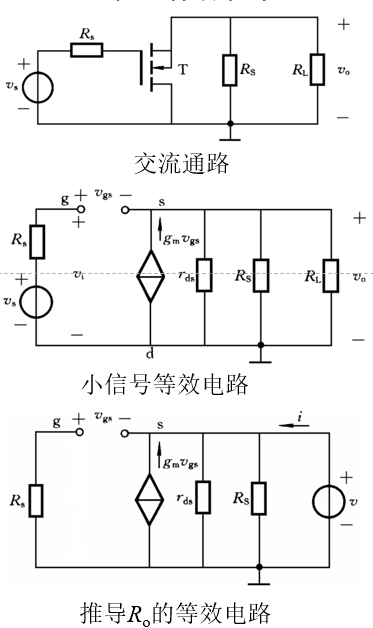
小结
| 性能 | 共源 | 共栅 | 共漏 |
|---|---|---|---|
共射放大器
基本共射放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
有源负载放大器
- 电压增益:
发射极接电阻的共射放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
共基放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
共集放大器
- 输入电阻:
- 输出电阻:
- 电流增益:
- 电压增益:
小结
| 性能 | 共射 | 共基 | 共集 |
|---|---|---|---|
集成MOS放大器
只有源极不与衬底相连时要考虑衬底效应,即源漏间的
E/E和E/D MOS放大器:只用N型
- E/E:放大器和负载均为EMOS
- E/D:放大器为EMOS,负载为DMOS
CMOS放大器
- 电流源负载CMOS放大器
- NMOS做放大管,PMOS接成电流源作负载管
- 信号加在PMOS栅极,NMOS栅极接偏置电压作负载管
- 推挽CMOS放大器
- 将电流源负载放大器中的NMOS与PMOS栅极相接作输入端
共栅放大器
共漏放大器
组合放大器
共集-共射放大器
共集-共基放大器
达林顿连接
- 同一种导电类型的BJT构成复合管时,前一只BJT的发射极接至后一只BJT的基极,以实现两次电流放大作用;等效为同一类型的BJT
- 不同导电类型的BJT构成复合管时,前一只的集电极接至后一只的基极,以实现两次电流放大作用;等效为与第一只BJT相同类型的BJT
- 要求:
- 两个BJT的电流方向必须统一,内部电机的电流流向不能冲突
- 第二只BJT的发射极必须单独引出,作为相同导电类型等效BJT的发射极,或不同导电类型等效BJT的集电极
复合管电参数
- 电流放大系数:
- 输入电阻:
- 相同类型:
- 不同类型:
复合管的改进
为提高复合管的热稳定性,一般在第二只管的基极与发射极间连接一个穿透电流泄发电阻
4-3 差分放大器
由于电路中往往噪声一致,故用差分放大器来消除噪声
4-3-1 电路结构
4-3-2 性能特点
共模信号:两信号和的一半,即均值
差模信号:两信号差
差模等效电路

电路两边对称,所以在差模输入电压作用下,两管产生等值反向的增量电流,当它们共同流入时,两管增量电流相消,流经的电流不变,因而对差模信号而言,可视为短路。
性能指标定义
- 双端增益: 双端差模输出电压对差模输入电压的比值
- 单端输出时差模电压增益:单端差模输出电压对差模输入电压的比值
- 差模输入电阻
- 差模输出电阻:单端输出时,为放大器任一输出端到地的输出电阻,而双端输出电阻则是以两端向放大器看过去的输出电阻,即为两放大器输出电阻之和。(将输入电压短路)
- 共模增益
- 共模抑制比:
指标计算
共模等效电路
电路两边对称,所以在共模输入电压作用下,两管产生等值同向的增量电流,当它们共同流入时,流经的电流翻倍,因而对共模信号而言,相当于接入。
输入共模信号时输出始终为零,所以双端共模增益为零
性能指标定义
- 共模输出电阻:单端输出电阻是任一输出端到地的输出电阻
指标计算
双极型差分放大器
4-3-3 电路两边不对称对性能的影响
双端输出时的共模抑制比
此时两输出电压不相等,故输出电压包含差模分量
,是差模输入电压转换为差模输出电压的增益,是共模输入电压转换为差模输出电压的增益
失调及其温漂:
- 输入失调电压:
- 输入失调电流:
- 输入基极电流:
失调模型和调零电路
失调电压电流的温漂
调零电路无法消除温漂
4-3-4 差模传输特性
双极性差放的差模传输特性
用理想电流源代替
时,
时,差模传输特性曲线近似为直线。时,差放进入限幅区,其中一管导通,一管截止,但要限制。
MOS差放的差模传输特性
很小时,差模传输特性斜率为常数
4-4 电流源电路及其应用
4-4-1 镜像电流源
双极性晶体管镜像电流源
基本镜像电流源电路
T1接成二极管,T2接成电流源
减小β影响的镜像电流源电路
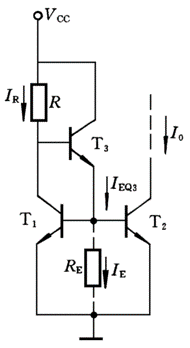
比例式镜像电流源
集电极电流与发射极电阻成反比
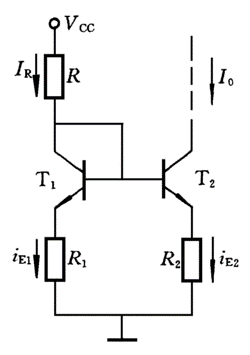
微电流源
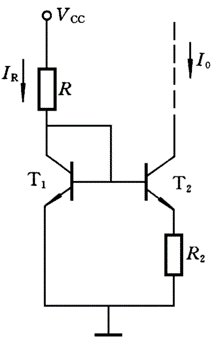
MOS镜像电流源电路
基本镜像电流源电路
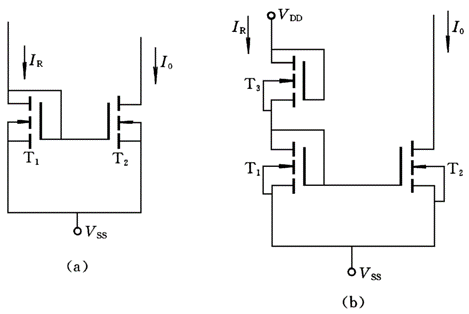
动态电流镜
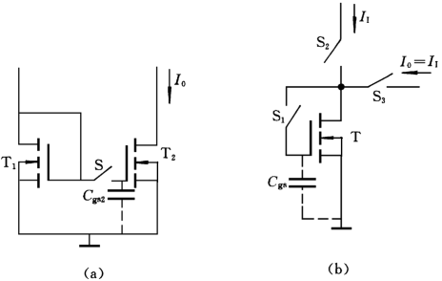
开关电流电路
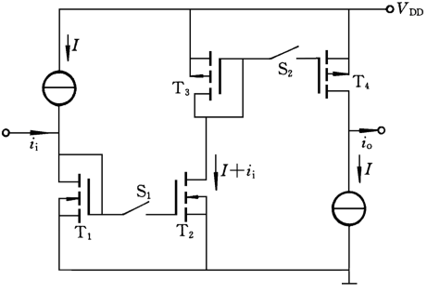
4-4-2 其它改进型电流源电路
级联型电流源电路
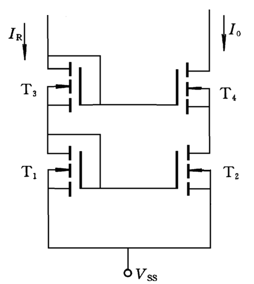
威尔逊电流镜
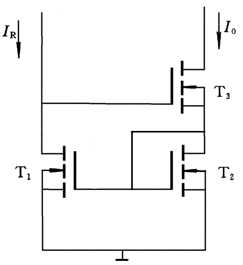
4-4-3 电流源的应用
有源负载差分放大器

差模电压作用
4-5 多级放大器
4-5-1 多级放大器的基本问题
换能器的接入:
- 将换能器的输出有效地输入放大器
- 不影响放大器的静态工作点
级间连接:
- 隔直流连接:电容耦合
- 直接连接
4-5-2 多级放大器的性能指标计算
划分为多个常见电路模型
4-6 放大器的频率响应
4-6-1 复频域分析方法
传递函数法
常用复频率s进行分析,求出放大电路的电压增益、电流增益、输入阻抗和输出阻抗等关于s的方程
系统传递函数
称为标尺因子,z为零点,p为极点
一个独立电抗元件对应一对极零点
频率特性:A;频率响应:Y=AX
实数极零点的波特图和渐进波特图
常数因子:,与频率无关
极零点在原点的因子:-20log(ω)
一阶因子:
极点:,其中前一项并入标尺因子,后一项称作一阶因子的标准形式
- 时,或0dB,
- 时,或-3dB,
- 时,或,
零点:
用折线逼近的波特图,称为渐近波特图。
每个极零点的幅频特性用两条渐近线逼近:一条为零分贝水平线;一条为按描述的直线,在半对数坐标轴上这条直线的斜率是-20dB/10倍频。这两条直线在上转折。
每个极零点的相频特性用三条渐近线逼近,一条是通过点、且斜率为-45°/10倍频的直线;另两条是0°和-90°的水平线,它们分别在处转折。
起始水平线:常数因子的对数乘以20
遇到零点则斜率加,遇到极点则斜率减
相频:从开始非0,单极点斜率为-45°
计算真实增益:s替换为jω
中频增益和上下限频率
中频增益
- 方法一:直接作出幅频特性渐近波特图,图中最高幅值平坦部分的值为中频增益。
- 方法二:将传递函数直接分解成一极一零连乘形式,根据极零点位置确定其具有低通或高通特性,若具有高通特性则令s→∞,若具有低通特性则令s→0,再将各系数连乘即为中频增益。
上下限频率
- 根据定义:
- 多极无零系统:
- 重极点:,n为极点个数
- 用主极点近似求解
考虑上下限截止频率时零点往往不及极点,可以忽略
主极点:
- 低频主极点:比其它极点值都大4倍以上
- 高频主极点:比其它极点值都小4倍以上,又称主极点
波特图:
- 幅频特性:以中频段为基准,低频段+20dB/dec,高频段-20dB/dec
- 相频特性:第一个极点相移±45°,第二个极点相移±135°,以此类推
4-6-2 共源、共发放大器的频率特性
密勒定理
图(a)为输入输出端跨接阻抗Z(s)(或Y(s)=1/Z(s))的网络,它可以用图(b)来等效: ,其中A(s)=V2(s)/V1(s),即Y(s)可以用分别并接在输入输出端的导纳Y1(s),Y2(s)来代替
中频增益即小信号等效电路的电压增益(20lg)
密勒倍增因子
5 放大器中的负反馈
反馈:输出信号被送回输入端
负反馈:使得实际输入信号减小
正反馈无用(振荡器),会使得放大器自激。故反馈信号不能和输入信号同向。
5-1 反馈放大器的基本概念
5-1-1 反馈放大器的组成
输出信号
反馈系数
误差信号
反馈放大器的增益(闭环增益):
环路增益,反馈深度
反馈网络的输入端在原输出端侧
5-1-2 四种类型负反馈放大器
电压型:输出端并联;电流型:输出端串联
并联型:输入端并联,接电流源;串联型:输入端串联,接电压源
反馈信号类型一定与输入信号类型一致。
5-1-3 反馈放大器的判别
分别画出输入和输出回路
反馈元件有两种:
- 输入和输出回路共用(不认为是反馈元件)
- 跨接在输入输出之间
类型判别
分别短路输入输出
- 短路输入时,若反馈网络的输出对放大器产生影响,如,则为串联
- 短路输出时,若反馈网络有输入,则为电流
简化:
- 与输出连:电压
- 与输入连:并联
极性判别
极性主要指增益的正负
削弱净输入信号的为负反馈,增强净输入信号的为正反馈,即的正负
在闭合环路的任一处断开,并在此处假定信号极性,而后不考虑信号源,按顺时针判定信号流经该闭合环路时电压极性的转换,直到返回断开点。 若此时极性与假设相同,则为正反馈。
顺时针指先经过放大器输入,到输出,再到反馈网络输入,到输出。
经过 地 时反相,经过 * 电阻* 时不变
断开点选取:尽量使分析简化为从放大器输入端看到输出端
5-2 负反馈对放大器性能的影响
5-2-1 输入电阻
不考虑输出方式,故将输出端统一用表示
串联负反馈:输入端是基本放大器的输入与反馈网络的输出串联连接,故输入电阻增加到基本放大器输入电阻的F倍
5-2-2 增益及其稳定性
源电压增益:
增益灵敏度:
5-2-3 输出电阻
- 输出阻抗低适合输出电压
- 输入阻抗低适合输入电流
5-2-4 失真和噪声
| 反馈类型 | 输入阻抗 | 输出阻抗 | 类型 |
|---|---|---|---|
| 电压串联负反馈 | 电压增益 | ||
| 电压并联负反馈 | |||
| 电流串联负反馈 | |||
| 电流并联负反馈 | 电流增益 |
5-3 负反馈放大器的性能分析
5-3-1 负反馈放大器的分析方法
分解为基本放大器和反馈网络,须考虑反馈网络对放大器的负载效应
拆环方法:
- 考虑反馈放大器输入时,将反馈网络的输出
- 电压:短路
- 电流:开路
- 考虑反馈放大器输出时,将反馈网络的输入
- 并联:短路
- 串联:开路
电压:假设输出电流 电流:假设输出电压 并联:假设输入电流 串联:假设输入电压
假设网络的输入、输出电流,并用电压来表示之,最后将电流搬回放大器,得到反馈系数
5-3-3 深度负反馈
深度负反馈条件
或
此时:或
有:输入、输出电阻趋近于零或无穷(根据反馈类型)
虚短虚断
5-4 负反馈放大器的稳定性
5-4-1 判别稳定性的准则
自激条件:
稳定裕量:反馈放大器远离自激的程度
- 相位裕量:,为正时不自激
- 增益裕量:,为正时不自激,越大越稳定
综上,更大的相位裕度,系统更稳定,但时域响应速度也越慢。所以,工程上一般选取为45°~ 60°,此时放大器稳定且响应速度也可接受。
稳定裕量的确定
将写成,做出对应水平线:反馈增益线,其与增益波特图交点即为。
反馈增益线与幅频特性交点处的相位与180°相位的差值的绝对值越大,放大器越稳定;绝对值为0时,取到最大反馈系数。
在多极点系统中,若,则上的相角绝对值恒小于或等于135°。
5-4-2 集成运放的相位补偿技术
相位补偿技术:在基本放大器或反馈网络中添加电阻、电容等元件,修改环路增益的波特图,使得增大时能获得所需的相位裕量。
基本出发点:保证中频增益不变的情况下,增大波特图上第一和第二个极点角频率的间距。
简单电容补偿技术:
将一只补偿电容并接在集成运放中产生第一个极点频率的节点上,使第一个极点角频率自降低到。
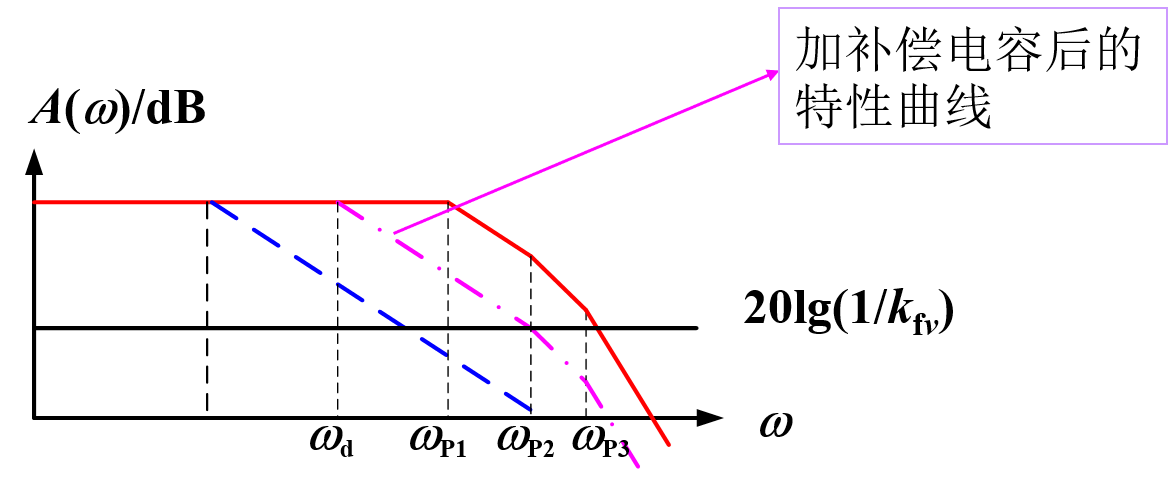
用密勒倍增效应实现相位补偿技术
6 集成运算放大器及其应用电路
6-1 集成运算电路
6-1-1 集成运放概述
6-1-2 MOS运放核心电路
6-2 集成运放应用电路的组成原理
理想化条件
虚短虚断
分类
基本应用电路
- 反相放大器,为负向端到地间电阻
- 同相放大器,时构成同相跟随器
6-3 集成运放应用电路
6-3-1 闭环应用
闭环:反馈电路
针对不同信号,一个个分别分析
简单电路直接套模型,不能套模型的用虚短虚断
加法和减法电路
反相加法器
优点:
- 要改变权值,只要改动对应支路
- 虚地,共模小
同相加法器
,其中、、、并联
缺点:
- 结果复杂
- 调试不便
- 不虚地
加法器实现的减法器
差动减法器
当时,
缺点:
- 不虚地
- 共模大
- 要选共模抑制比大的运放
积分、微分、指数、对数电路
积分运算电路
微分运算电路
对数运算电路
,其中
通常用三极管解成二极管,以增大工作区域
指数运算电路
仪器放大器
特点:
- 高共模抑制比
- 高输入阻抗
- 高放大倍数
作用:调节增益
电流-电压变换器
负载电阻不变时可视为电流放大电路
电压-电流变换器
- 负载不接地
- 负载接地 ,其中须避免分母为0。
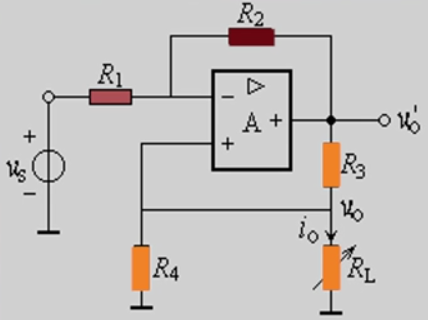
电流传输器
有源滤波器
可以带负载,可以提供增益
带通
带阻
6-3-2 开环应用
电压比较器
时输出高电平
单限电压比较器
迟滞比较器
先求输出范围,再通过电路求输入范围
输入接电容:方波发生器
6-3-2 混合应用
整流电路
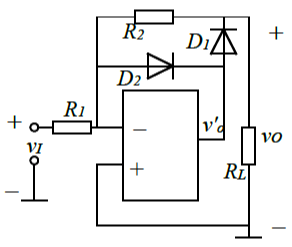
工作原理:利用运放开环的过零比较和闭环的线性运用,有效克服二极管导通电压的影响。
F007
单位增益频率,增益为n倍时,带宽就为1/n倍
模电 下
7 振荡器
变压器的交流通路仍是变压器
起振时可认为是小信号状态
振幅起振条件:开环增益
二反相放大器增益>3
相位起振条件:
稳定条件:,
7-2 LC正弦波振荡器
7-2-1 变压器耦合振荡电路
变压器特性:同名端极性相同
7-2-2 三点式振荡电路
三极管的三个电极分别与并联谐振回路的三个引出端点相连
- 电容三点式振荡电路:两串联电容与电感并联
- 电感三点式振荡电路:两串联电感与电容并联
BE和CE间为同性质电抗,BC为异性质,电路以发射极所接电抗类型命名
有时可以利用晶体管的等效阻抗:等效阻抗或,但其值极小,一般仅在原电路中无该类型电抗时才能使用
- LC串联电路:电路频率高于自谐振频率时呈感性
- LC并联电路:电路频率低于自谐振频率时呈感性
先画出电路的交流通路,再断开闭合环路
常将负载电阻以外的部分折算为谐振网络,以此利用谐振时谐振网络的特性来简化计算
相位起振条件常被简化为,即三电抗之和为0
振幅起振条件被简化为,其中
自给偏置
振幅增大时,发射结偏执电压将向截止方向移动,使放大器增益下降,提高了振荡的稳定性
直流偏置
注意直流时的电感的短路和电容的断路
7-2-3 差分对管振荡电路
一管趋向截止而使差模传输特性进入平坦区
正反馈从一管的输出接至同一管的输入
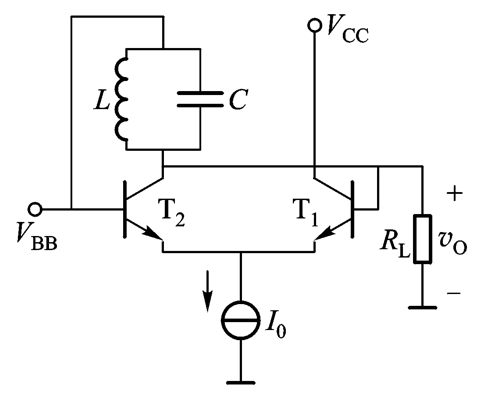
7-3 LC振荡器的频率稳定性
7-3-3 克拉泼振荡电路

7-4 石英晶体振荡器
电压与形变形成正反馈

有串联、并联两个谐振点,串联谐振:短路;并联谐振:断路
,为石英静态电容、支架、引线组成的电容,,其两者之间的频率中的石英呈感性
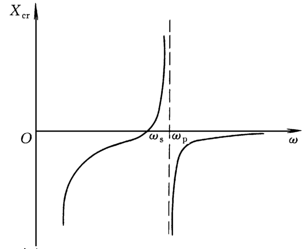
7-4-3 晶体振荡电路
并联型、串联型:由三点式振荡电路加上晶体得到
并联型:晶体呈断路用来替换电感(需注意直流通路)
串联型:晶体呈短路用来替换电容
7-5 RC正弦波振荡器
一级RC电路实际能提供的最大相移不到90°
外稳幅文氏电桥振荡电路。集成运放接同相放大器,提供零相移。
开路增益:

RC串并联选频电路应与同相放大器相连
移相为0的电路的虚部为0
 以上电路:
以上电路:
8 功率电子线路
实质是能量转换器
8-1 功率电子线路概述
8-1-1 功率放大器
性能要求
集电极效率,其中为输出功率,为直流功率,为管耗
- 甲类:全周导通,集电极效率最低
- 甲乙类:大于半周导通但不全通
- 乙类:半周导通
- 丙类:小于半周导通,集电极效率最高
8-1-2 电源变换电路
- 整流器:AC-DC
- 斩波器:DC-DC
- 逆变器:DC-AC
- 交流-交流变换器:AC-AC
8-1-3 功率器件
- 热阻:
- 最大耗散功率:
- 集电结与周围环境的热阻:,jc:结与管壳,ca:管壳与环境
- 装散热器后总热阻:
- 二次击穿:不限制电流的击穿会迅速由高压小电流转为低压大电流,且不可逆
- 功率MOS管
- 绝缘栅双极型功率管
8-2 功率放大器的电路组成和工作特性
8-2-2 甲类、乙类功率放大器的电路组成及其功率性能
甲类变压器耦合功放
直流负载线:
直流工作点Q:直流负载线与静态电流的三线交点
信号振幅只能取左侧以保证不失真,电流振幅只能取上侧,以保证不失真
交流负载线:过Q的斜率为
直流功率:
集电极管耗:
集电极效率:
要使输出信号功率最大,Q须在交流负载线中点:
乙类推挽功放
工作原理: 未输入信号时,两管截止,输出电压为0。 加信号后,两管轮流导通。 正半周期,导通,截止,;负半周期,截止,导通,。通过负载的电流为完整的正弦波。
此处为正负电源供电!若只有一个电源则所有VCC÷2,ξ×2(即)
电源电压利用系数:
总直流功率:
集电极效率:
集电极管耗:
总功率:
8-2-3 乙类互补推挽放大器实际电路
交叉失真
管子存在导通电压
须在BE间加正偏
二极管偏置
倍增偏置电路
准互补推挽电路
复合管类型由第一个管的类型决定。例如图中T2类型与T1一致。

保护电路
为保护管
输入激励电路
8-3 集成功率放大器
8-3-2 功率运算放大器
强烈建议用思维导图来记忆各公式间的联系~
| 傅里叶变换 | 拉普拉斯变换 | Z变换 | |
|---|---|---|---|
| 定义 | (t换为k,jω换为得DTFT) | ||
| 正变换 | |||
| 反变换 | |||
| 性质 | |||
| 线性 | |||
| 延时特性 | 增序: | ||
| 移频特性 | 减序: | ||
| 尺度变换 | |||
| 奇偶虚实性 | |||
| 对称特性 | |||
| 时域微分 | |||
| 时域积分 | |||
| 频域微分 | |||
| 频域积分 | |||
| 卷积定理 | |||
| 初值定理 | 等 | ||
| 终值定理 | 等 | ||
| 常用变换 | 傅里叶变换 | 拉普拉斯变换 | Z变换 |
|---|---|---|---|
| 鼠: | 1 | ||
| 牛: | |||
| 虎: | |||
| 兔: | |||
| 龙: | |||
| 蛇: | |||
| 马: | |||
| 羊: | |||
| 猴: | |||
| 鸡: | |||
| 狗: | |||
| 猪: | |||
电路
1 电路模型和电路定律
1-1 电路模型
-
实际电路:为完成预期目的而由电路部件和电路器件相互连接而成的电流通路装置。
- 电源:电能和电信号的发生器
- 负载:用电设备
- 激励:一般称电源为激励
- 响应:由激励在电路中产生的电压、电流
-
电路模型:电路模型是由理想电路元件相互连接成的一个系统。
- 理想元件:由具有确定电磁性质并用精确数学定义表示。各理想元件的端子是用理想导线连接起来的。理想元件分为二端,三端,四端元件等。
-
建模:用理想电路元件或它们的组合模拟实际器件就是建立其模型,简称建模。 > 建模时必须考虑电路工作条件。
具有相同电磁性能的实际电路部件,可用同一电路模型表示。 > 例如:线圈需考虑电阻效应。
1-2 电流、电压、电功率和能量
电流:单位时间内流过的电荷量
电压:单位点电荷从一点移动到另外一点所做的功
功率:单位时间内做的功p=ui
求得功率必须标注吸收or发出
已知为吸收,则答案为负
能量:
1-3 电流和电压的参考方向
规定正电荷运动方向为电流的实际方向
-
指定电流参考方向:任意假定一个正电荷运动的方向为电流的参考方向
-
参考方向与实际方向的关系:一致为正,相反为负
-
参考方向的表达方式:
- 用箭头表示(在图中)
- 用双下标表示,例:表示电流的参考方向是由A到B
-
规定电压的实际方向从高电位指向低电位,即电位降低方向。
-
用正极性(+)表示高电位,负极性(-)表示低电位,正极指向负极就是电压的参考方向。
-
参考方向与实际方向的关系:一致为正,相反为负
-
电压参考方向的三种表示方法:
- 用箭头表示(在图中)
- 用正负极性表示(在图中+—)
- 用双下标表示:(从A指向B)
关联参考方向:元件或支路的u,i采用相同参考方向称为关联参考方向。反之,称为非关联参考方向。(指电压电流方向是否一致)
电压源:电流从+到-为关联
特别注意:
- 分析电路前必须指定电压和电流的参考方向。
- 参考方向一经指定,必须在图中相应位置标注(包括方向和符号)
- 参考方向不同时,其表达式相差一个符号,但电压、电流的实际方向不变
电功率和电流电压参考方向的关系:元件吸收能量时为关联参考方向,反之元件释放能量。
为关联参考方向时:ui表示元件吸收的功率,p>0表示实际吸收功率,p<0表示实际发出功率。
为非关联参考方向时:ui表示元件发出的功率,p>0表示实际发出功率,p<0表示实际吸收功率。
对完整电路,发出功率=吸收功率
1-4 电阻
电阻元件的元件特性:u与i的代数关系f(u,i) = 0。
线性电阻元件:在电压与电流取关联参考方向时,两端的电压和电流服从欧姆定律 u = Ri,R为电阻元件的参数,称为电阻。
-
电阻的单位为Ω(欧姆,简称欧)。
-
-
称为电阻元件的电导,单位是S(西门子,简称西)
-
若电压、电流参考方向取非关联参考方向,则u = -Ri或i = -Gu
-
电阻元件的特性称为伏安特性,是一条通过原点的直线。
注意:
- 欧姆定律:只适用于线性电阻(即R为常数)
- 电压与电流参考方向非关联时,欧姆定律表示为u = -Ri或i = -Gu
- 线性电阻是无记忆、双向性的元件
公式和参考方向必须配套使用,有关电压单流的表达式都是在指定参考方向下给出的
-
电阻元件的吸收功率为
- 表明电阻元件在任何时刻总是吸收功率。
- 线性电阻是耗能元件。
-
电阻元件从到t时间内吸收的电能为
开路和短路:
- i = 0, u ,称此段电路处于开路;
- u = 0, i ,称此段电路处于短路。
1-5 电压源和电流源
电源有两种:电压源和电流源
电源与电路关联则吸收功率,非关联则发出功率
电压源:提供电压的电源,如电池,发电机等
-
电压源通用符号:⚪、竖线、正负极(参考电压)
-
电压源的特点:
- 电压由自身确定,电流由外电路确定
- 不能短路
电流源:提供电流的电源
-
电流源通用符号:⚪、横线、箭头(参考电流)
-
电流源的特点:
- 电压流由自身确定,电压由外电路确定
- 不能开路
1-6 受控电源
受控电源:电压或电流受其它电压或电流控制的电源
独立电源:其电压或电流由自身产生,不受其它电压电流控制
常见受控电源:变压器、三极管、运放
受控电源分为受控电压源与受控电流源,通用符号为将原有⚪改为菱形
受控源有四种类型:(括号中为符号旁注)
- 电压控制电压源VCVS(ku,常数k)
- 电流控制电压源CCVS(ki,常数k单位为Ω)
- 电压控制电流源VCCS(ku,常数k单位为西门子)
- 电流控制电流源CCCS(ki,常数k)
理想变压器可视为一个电压控制电压源和一个电流控制电流源
1-7 基尔霍夫电流定律(KCL)
流入电流 = 流出电流
电路上任一结点上电流代数和为0
广义结点:任意封闭曲线;对于任意封闭曲线,流入流出电流和为0
在同一个电路中,x个结点的KCL方程中,只有x-1个KCL方程是独立的。
1-8 基尔霍夫电压定律(KVL)
升压 = 降压 > 电场力做功与路径无关
- 在电路中,任一时刻,沿任一回路绕行,各支路电压的代数和等于零。
- 降压取+,升压取-
- 电流从高电压至低电压为正
KVL也适用于电路中任一假想的回路(其中补的电路需假设电阻),即非闭合电路
1-9 KCL和KVL的综合运用
KCL和KVL是电路基石 > 一般来说,每增加一个受控源,就要增加一个关于控制量的表达式
2 电阻电路的等效变换
2-1电路的等效变换
等效变换的主要作用是简化电路分析
等效变换:将电路中某一部分进行变换,变换后该部分外部端口的电压电流值都保持不变,或者说外部端口的电压电流关系都保持不变。 > 可能有多个端口
等效变换的特点:
- 对外等效
- 对内不等效
Y形电阻和Δ形电阻的等效变换
- Y形电阻 = Δ形相邻电阻的乘积 ÷ Δ形电阻之和
- Δ形电阻 = Y形电阻两两乘积之和 ÷ Y形电阻不相邻电阻
2-2 电阻的串联和并联
2-3 电压源、电流源的串联和并联
电压源串联:
电压源并联:
只有相同的理想电压源才能并联
电流源并联:
电流源串联:
2-4 实际电源的两种模型
实际电压源:理想电压源和电阻(内阻)串联
实际电流源:理想电流源和电阻(内阻)并联
两种电源进行等效变换时:
- 电流源等效为电压源:
- 电压源等效为电流源:
方向为非关联
等效时电阻通常保持不变,但其上电压、电流变化
方程不够时,可设被替换的电路原电压为u,构建假想回路列式
与电压源并联、与电流源串联的电阻对于外电路来说均可忽视
3 电阻电路的一般分析方法
3-1 回路电流法
支路:每一个二端元件称为一个支路,多个二端元件串联也可视为一条支路
结点:支路与支路的连接点称为结点。多个等电位的结点可视为一个结点
路径:从一个结点到另一个结点所经过的支路的集合
回路:起点与终点相同的闭合路径。要求中间经过的结点只能经过一次
网孔:不含有支路的回路称为网孔,KVL独立方程数=网孔数量
树:包含图G的全部结点且不包含任何回路的连通子图。树中包含的支路称为树支,而其它支路则称为该树的连支
基本回路:一个树加入一个连支后形成的回路
回路电流:将单一网孔中的回路电流单独设出,这样就不再需要列写KCL方程(结点被拆分)
回路电流的标准方程:
- 自阻:某一回路中所有电阻之和,永远取正号
- 互阻:两个回路共同所有的电阻(一般同时被自阻计算在内),互阻上两回路电流同向取正,反向取负
- 右端电源电压:某一回路中所有电源之和,非关联取正,关联取负(因为移项~)
- 标准方程:
若在互阻上两电流方向相反,则互阻项前加负号
遇到受控源时,用回路电流表示控制源作为附加方程
遇到无伴电流源时:将无伴电流源两端电压作为求解变量列入方程,其所在回路不列方程
3-2 结点电压法
结点电压:任意选择某一结点为参考结点,其它结点为独立结点,那么结点电压即独立结点与参考结点间的电压差
参考极性:独立结点为正,参考结点为负
结点电压方程:以结点电压为独立变量,列写独立结点的KCL方程(共n-1个)
在方程中用结点电压表示支路电流
自电导:接在该结点上所有支路的电导之和,总为正
互电导:两结点间所有支路电导之和,总为负
结点电压法的一般步骤:
- 选定参考结点,标定n-1个独立结点编号
- 对n-1独立结点,以结点电压为独立变量,列结点电压方程(设出各支路电流)
- 求解结点电压方程,得到n-1个结点电压
- 通过结点电压求各支路电流
- 其它分析
遇到无伴电压源时
- 方法一:将无伴电压源的电流作为附加变量列入KCL方程,每引入这样的一个变量,同时也增加了一个结点电压与无伴电压源电压的约束关系;
- 方法二:将连接无伴电压源的两个结点的结点电压方程合并为一个,即取一个包含这两结点的封闭面的KCL,同时添加结点电压与无伴电压源的约束关系,其所在结点不列方程。
遇到受控源时,用结点电压表示受控源控制量
3-3 回路电流法和结点电压法的对比
| 本质 | 自动满足 | 列写形式 | 正负号 | 受控源处理 | |
|---|---|---|---|---|---|
| 回路电流法 | KVL | KCL | KVL方程 标准方程 | 自阻正 互阻有正负 右端电源电压 关联负,非关联正 | 用回路电流表示控制量 |
| 结点电压法 | KCL | KVL | KCL方程 标准方程 | 自导正 互导负 右端电源电流 流入正,流出负 | 用结点电压表示控制量 |
回路电流法适用于独立回路较少的电路
结点电压法适用于独立结点较少的电路
4 电路定律
4-1 叠加定理
叠加定理:线性电路中,任一支路的电压或电流都等于各独立电源单独作用在此支路所产生的电压或电流的叠加
- 电压源用短路代替
- 电流源用断路代替
线性:
4-2 替代定理
替代定理:对于任一电路,若某支路电压为、电流为,那么这条支路就可以用一个电压等于的独立电压源替代,或者用一个电流等于的独立电流源替代,或者用的电阻来替代,替代后电路中全部电压和电流均保持原有值
替代定理既适用于线性电路,也适用于非线性电路
4-3 戴维宁定理
等效电阻:若一端口网络中仅含线性电阻(和受控源),则可以等效为一个电阻,可以为负
求等效电阻方法:在端口加电压源,求电源电压和电流的比值
戴维宁定理:一个含独立电源、线性电阻和受控源的一端口,对于外电路来说,可以用一个电压源和电阻的串联来等效。此电压源电压等于端口的开路电压,记为,电阻等于端口内全部独立电源置零后(电压源变为短路,电流源变为开路)的等效电阻(即输入电阻),记为
4-4 戴维宁等效电路的求解
先求开路电压,再求等效电阻
求等效电阻:外加电源法和短路电流法
- 外加电源法:将一端口内所有独立源置零,在端口外加电压源,则等效电阻等于外加电压源的电压和电流的比值(取非关联)
- 短路电流法:将一端口短路,有受控源时须用此法
4-5 诺顿定理
诺顿定理:任一含源线性一端口电路,对外电路来说,可以用一个电流源和电阻并联组合来等效置换。电流源的电流等于该一端口的短路电流,电阻等于该一端口的输入电阻
注意:
- 若一端口网络的等效电阻为0,则该一端口网络只有戴维宁等效电路,无诺顿等效电路
- 若一端口网络的等效电阻为∞,该一端口网络只有诺顿等效电路,无戴维宁等效电路
短路电流既可求等效电阻,又可用于诺顿定理
将各源分别作用(叠加定理)
4-6 最大功率传输定理
时取得最大功率
此时R中电流为
注意
- 最大功率传输定理用于一端口电路给定,负载电阻可调的情况;
- 计算最大功率问题结合应用戴维宁定理或诺顿定理最方便
- 分母上的4!
5 动态电路的时域分析
5-1 电容元件
电容元件:储存电能的两端元件。任何时刻其存储的电荷q与其两端的电压u能用q-u平面上的一条曲线来描述。
串并联:等同于电导
线性时不变电容元件:任何时刻,电容元件极板上的电荷q与电压u成正比。
q = Cu
C = ∝ tanα
单位:F(法拉)
电容的电压电流关系:称为电容元件VCR的微分形式,其中u、i取关联方向
某一时刻i的大小取决于u的变化率,而与该时刻电压u的大小无关。
电容是动态元件
当u为常数(直流)时,i=0。
电容相当于开路,电容有隔断直流作用。
实际电路中通过电容的i为有限值,u必定为时间的连续函数。
> 某一时刻的u(t)值与-∞到该时刻的所有电流值有关
电容元件有记忆电流的作用,称电容元件为记忆元件。
研究某一以后的u(t),需要知道时刻开始的电流i和时刻电压u()
注意:
- 当电容的u,i为非关联参考方向时,电容元件VCR表达式前要加负号:
- 上式中称为电容电压的初始值,也称为初始状态。
电容的功率: 电容充电时p>0,电容吸收功率; 电容放电时p<0,电容吸收功率
因此电容为储能元件
电容的储能:
电容储能只与当时电压值有关,电压不能跃变,反映了储能不能跃变。
电容储存的能量一定大于或等于零。
积分勿忘初值
5-2 电感元件
电感元件:储存磁能的两端元件。任何时刻,磁通链和流过的电流i的关系可用平面上的一条曲线来描述。
串并联:等同于电阻
线性时不变电感元件任何时刻,通过电感元件的电流i与其磁链成正比。
L称为电感元件的电感,且
单位:H(亨利)
电感的电压电流关系:称为电感元件VCR的微分形式,其中u、i取关联方向。
某一时刻u的大小取决于i的变化率,而与该时刻电流i的大小无关。
电感是动态元件
当i为常数(直流)时,u=0。
电感相当于短路。
实际电路中通过电感的u为有限值,i必定为时间的连续函数。
某一时刻的i(t)值与-∞到该时刻的所有电压值有关
电感元件有记忆电压的作用,称电感元件为记忆元件。
研究某一以后的i(t),需要知道时刻开始的电压u(t)和时刻电流i()
注意:
- 当电感的u,i为非关联参考方向时,电容元件VCR表达式前要加负号:
- 上式中称为电感电流的初始值,也称为初始状态。
电感的功率: 电流增大时p>0,电感吸收功率; 电流减小时p<0,电感吸收功率
因此电感为储能元件,也是无源元件
电感的储能:
电感储能只与当时电流值有关,电流不能跃变,反映了储能不能跃变。
电感储存的能量一定大于或等于零。
5-3 动态电路的方程
动态电路:含有动态元件电容和电感的电路称为动态电路
特点:当动态电路状态发生改变时,需经历一个变化过程才能达到新的稳定状态,这个变化过程称为过渡过程。
换路:电路结构、状态发生变化
- 支路接入或断开
- 电路参数变化
过渡过程产生的原因:
- 电路含有储能元件L、C
- 电路在换路时能量发生变化,而能量的储存和释放都需要一定的时间来完成。
动态电路的方程
- RC电路:
- RL电路:
含有一个动态元件的线性电路,其方程为一阶线性常微分方程,称为一阶电路;
含有两个动态元件的线性电路,其方程为二阶线性常微分方程,称为二阶电路。
结论:
- 描述动态电路的电路方程为微分方程(而非代数方程)
- 动态电路方程的阶数通常等于电路中动态元件的个数,但例如电容串联时(等效于一个电容)或电阻与电压源串联时(一阶)不等
动态电路的分析方法:
- 根据KVL、KCL和VCR建立微分方程
- 求解微分方程,一般使用时域分析法中的经典法
5-4 动态电路的初始条件
初始条件:电容的初始电压或电感的初始电流,即电路变量的初始值
0+:t=0动作后一瞬间 0-:t=0动作前一瞬间
确定动态电路的初始条件:动态电路的初始时间点为0+
- 电容在等效反向电压源
- 电感在等效反向电流源
电容电压在开关动作前后保持不变,因为充放电需要一段时间
电感电流在开关动作前后保持不变,因为充放磁需要一段时间
5-5 一阶电路的零输入响应
含电容一阶电路的零输入响应是一个电容放电的过程,电容电压随时间呈指数函数衰减,最终趋于0。
含电感一阶电路的零输入响应是一个电感释放磁能的过程,电感电流随时间呈指数函数衰减,最终趋于0。
5-6 一阶电路的零状态响应
含电容一阶电路的动态行为是一个电源向电容充电的过程,电容电压随时间呈指数函数增大,最终充满电,电容电压等于电源电压。
含电感一阶电路的动态行为是一个电源向电感充磁能的过程,电感电流随时间呈指数函数增大,最终充满磁能,电感电流等于电源电流。
5-7 一阶电路的全响应
全响应:初始电压不为零,且有独立的电压源
全响应=(稳态分量)+(暂态分量)=(零输入响应)+(零状态响应)
叠加定理
5-8 一阶电路分析的三要素法
电容:
- :要素一(初始值)
- :要素二(稳态值)
- RC:要素三(时间常数),常记作
电感:
- :要素一(初始值)
- :要素二(稳态值)
- :要素三(时间常数),常记作
三要素公式:
三要素法应用步骤
- 求初始值,根据0+状态与0-状态相同
- 求稳态值,根据戴维宁等效或诺顿等效
- 求时间常数,根据等效电阻(将电源置零,从电容/电感看去)
- 将三要素代入三要素公式
5-9 二阶电路
二阶电路的方程:为二阶线性常微分方程
- 当时,二阶电路方程为齐次方程
- 当时,二阶电路方程为齐次方程
二阶电路的零输入响应: 这是一个齐次方程,由于输入激励项为0,所以以及其他电路变量称为零输入响应
零输入响应的三种情况
- 即特征根为相异负实根,又称过阻尼,非振荡放电,
- 即特征根为相等负实根,又称临界阻尼,非振荡放电,
- 即特征根为共轭负实根,又称欠阻尼,振荡放电,
由初始条件确定常数
二阶电路零状态响应和全响应
- 微分方程:
- 特征方程:
- 特解:
- 解答形式:
- ,过阻尼非振荡充放电
- ,临界阻尼非振荡充放电
- ,欠阻尼振荡充放电
- 由初始条件确定常数
- 当和均为0时,为零状态响应
- 当和不全为0时,为全状态响应
6 相量法
6-1 为什么引入相量法
相量法利用正弦量和复数的关系,将微分方程变为代数方程,从而将求微分方程的特解转变为求代数方程的解,使正弦稳态电路的求解也像直流电路的求解一样。
6-2 复数
- 加减法:常用图解法
- 乘除法:常用极坐标式,模相乘/除,辐角相加/减
- 旋转因子:模为1,辐角为θ的复数;一个复数与之相乘将会逆时针旋转θ
6-3 正弦量
瞬时值表达式:
三要素:
- 幅值
- 角频率ω
- 初相位Ф(-180°~180°)
同频率正弦量相位差:等于初相位之差(-180°~180°)
正弦电流、电压有效值:将正弦电流、电压在一个周期内产生的平均效应换算为等效的直流量,称为正弦量的有效值。
测量中交流测量仪表指示的一般为有效值
瞬时值:小写;最大值:下标m;有效值:大写
6-4 相量法的引入
对任意一个正弦量,都可以转化为复数的实部
将称为电感电流的相量形式,为电感电流的有效值,为初相角。
将称为电压源电压的相量形式。
只要求出相量,即可获得正弦量三要素中的两个要素。ω与正弦激励角频率相同,不需要求解。(可能会故意设定ω与激励角频率不同)
每求导一次就增加一个jω
j即逆时针转90°
将分母上复数的幅角取相反数即可
答案须化为标准形式
一般是已知各支路电流间夹角,画图求出有效值
6-5 电路定律的相量形式
电流、电压的相量形式都满足KCL、KVL方程,可以直接列写。
在相量域中受控域支路(包括电阻)的控制关系不变
电感:相量域中,,类似于欧姆定律,只不过系数为纯虚数,故将jωL称为感抗。
相量域实质是将时域的微分关系转变为比例关系
电容:相量域中,,类似于欧姆定律,只不过系数为纯虚数,故将称为容抗。
6-6 阻抗和导纳
阻抗:包含电阻、感抗和阻抗,记为Z
Z的通用表达式为Z=R+jX,R为电阻,X为电抗
X>0时,阻抗Z呈感性 X<0时,阻抗Z呈容性
导纳:阻抗的倒数,记为Y
阻抗于导纳的串并联:分别等效于电阻和电导
7 正弦稳态电路的分析
相量一般表示为复数的极坐标形式
复数运算经常需要在代数形式和极坐标形式间转换
7-1 相量图
相量图:用几何方法表示相量
绘制依据:KCL和KVL中,电流或电压符号相同,则首尾相连;若符号相反,则碰头或碰脚
绘制步骤:模值无需精确,仅需定性,角度必须定量绘制
- 确定参考相量,即角度为零的相量。一般串联电路以电流为参考相量,并联电路以电压为参考相量;
- 根据支路的VCR确定支路电压或电流相量的角度;
- 根据KCL、KVL构成封闭图形。
多j就超前90°,故电感电压超前电流90°,电容电压滞后电流90°(超前即逆时针转)
电压源相量使电压相量图封闭,或作为电流相量图的参考相量
7-2 正弦稳态电路的瞬时功率
p(t)=u(t)i(t)
周期为电压电流的一半,频率为两倍
电阻总是吸收功率,电容、电感一周期内发出功率等于吸收功率
7-3 有功功率和无功功率
P=UIcosφ为有功功率(W)
Q=UIsinφ为无功功率(var,乏)
有功功率表征了电阻、电源等平均吸收或发出功率的能力。有功功率又称平均功率。
无功功率表征了电容、电感等中转(吞吐)功率的能力。认为电容发出无功功率,电感吸收无功功率。
| 元件 | 有功功率 | 无功功率 | |
|---|---|---|---|
| 电阻 | 0 | UI | 0 |
| 电容 | -90° | 0 | -UI |
| 电感 | 90° | 0 | UI |
7-4 视在功率和功率因数
视在功率:S=UI
功率因数:,即有功功率占视在功率的比例
7-5 复功率
复功率:(相量),单位V·A
当负载表示为阻抗Z=R+jX或导纳Y=G+jB时,也可表示为或
- 是复数而非相量,没有对应的正弦量;
- 把P、Q、S联系在一起,其实部为平均功率,虚部为无功功率,模为视在功率;
- 复功率满足守恒定理:
复功率守恒,视在功率不守恒
串联电路:
7-6 正弦稳态电路的最大功率传输
有功功率:
- 若可取任意值,则P取得最大值时,,即最佳匹配条件:,此时
- 若,为纯电阻,则P取得最大值时,,即模匹配,
8 含有耦合电感的电路
8-1 互感的定义
,M称为互感
耦合系数,k=1为全耦合
互感最典型的应用是变压器,通过互感实现变压。互感还有电隔离和阻抗变换器的作用
电感电压=自感电压+互感电压,互感电压=相邻电路电流*互感
有互感的电路只能用回路电流进行分析,无法使用结点电压。
8-2 同名端和互感电压方向
磁场增强还是消弱取决于线圈的绕制方向和电流方向
同名端:一组端子同时流入电流时会使得产生的磁场相互增强,则称为同名端
互感电压的方向:磁场相互增强时,互感电压项前取正号,反之取负号
互感电压方向的判断:若两端子为同名端,且都流入电流,则产生的磁场相互增强,此时互感电压在同名端上取正号
8-3 互感的去耦等效
电感同名端相接的连接方式称为反接,非同名端相接的连接方式称为顺接
互感同向串联(顺接)可去耦等效为一个等效电感,其自感系数为
互感反向串联(反接)可去耦等效为一个等效电感,其自感系数为
T型接法:在串联电感之间引出一个接线端,有两种情况:同名端位于新接线端同侧(即都靠近或远离新接线端),或位于新接线端异侧
T型异侧可等效为串联,新接线端处替换为-M的电感
T型同侧可等效为串联,新接线端处替换为M的电感
类似变压器的对置电感,可将两电感的一侧相连,则形成T型接法,但不如置源后使用网孔电流法。等效电感即电压除以电流的微分。等效电感为0时,置电流源为妥。
互感并联只是T型接法的特殊情况
8-4 含有耦合电感电路的计算
- 在正弦稳态情况下,含有耦合电感电路的计算仍应用相量分析法
- 互感线圈上的电压除自感电压外,还包含互感电压
- 一般采用支路法和回路法计算
- 若已使用去耦等效获得无耦合电感的电路,则直接使用相量法的任何方法
8-5 变压器
空气变压器:两个线圈在空气中绕制且互相耦合
铁芯变压器:两个线圈在铁芯上绕制且互相耦合
理想变压器:
- 全耦合:
- 无穷大,
- 无损耗
铁芯变压器磁导率μ很大,可近似为理想变压器
1代表原边,2代表副边
理想变压器与阻抗变换:,阻抗变换后两边复功率相同
9 电路的频率响应
9-1 网络函数
网络函数:,A(jω)称为激励,B(jω)称为响应,两者既可以是电压相量,也可以是电流相量
此处响应和激励只是一种称呼
- 幅频特性——幅值随角频率变化的规律
- 相频特性——相位随角频率变化的规律
9-2 谐振定义和谐振条件
谐振:电路相量在特定频率(固有频率)激励下,比其他频率激励时振幅(幅值)更大的情形
串联谐振的条件:阻抗虚部为0,电压电流同相位,z最小,串联LC可用于短路(选频)
并联谐振的条件:导纳虚部为0,电压电流同相位,y最小,并联LC可用于隔断(选频)
谐振须用傅里叶计算
9-3 RLC串联谐振的特点
- RLC串联等效阻抗为纯电阻
- 最小,因此最大
- 若仅为纯电抗,即R=0,则Z=0,相当于短路
- 可能过电压,这一风暴是外部激发,内部配合
品质因数Q:则,同理,
9-4 RLC串联谐振的频率响应
频率响应写出相频特性和即可
在谐振角频率时最大,最大
半功率点:处
带宽:两个半功率点的角频率差,又称通频带。品质因数越高,带宽越窄。条件是
9-5 RLC并联谐振的特点
- RLC并联等效导纳为纯电导
- 最小,因此最大
- 若仅为纯电抗,即,则Y=0,相当于开路
- 可能过电流
品质因数Q:则,同理,
Q无单位
RLC并联谐振和串联谐振的特点是一一对偶的关系
10 三相电路
10-1 三相电路
三相电路由三相电源、三相负载、三相输电线组成,可以产生、传输、利用更多功率
三相电路的连接方式:Y型接法和Δ型接法,而电源和负载的组合便形成了更多接法,如YY接法,ΔΔ接法,三相四线制接法等
10-2 线电压/电流与相电压/流关系
相电压:三相电源或三相负载每一相的电压
线电压:输电线之间的电压
三角形接法中线电压=相电压
相电流:三相电源或三相负载每一相的电流
线电流:输电线上的电流
星型接法中线电流=相电流
10-3 对称三相电路的计算
对称三相电路:三相电源对称且三相负载对称的电路
对于对称三相电路,可将其化为单相电路:
- 分别取星型电路的电源和负载的中心结点N、N',称为中性点
- 以N为参考结点,列写N'的结点电压方程
- 知N与N'等电位,可用一条虚拟导线连接
对称三相电路拆为单相电路的方法:
- 顺藤摸瓜:从A相电源出发,顺着支路到达
- 花开两朵,各表一枝:继续抵达各阻抗
- 水到渠成:将等电位的中性点相连,获得单相电路
电压须除以以等效为单相电压
求单相电路时与中性线无关
算出某相后用α(120°旋转向量)乘之得其余两相
遇到三角形接法,则等效为星形接法(将三个三角形相接的3Z阻抗等效为三个星型相接的Z阻抗)
10-4 不对称三相电路的概念
主要讨论电源对称,负载不对称的三相电路,采用相量法
中性点位移:负载中性点与电源中性点在相量图上不重合
当中性点位移较大时,负载相电压严重不对称,使负载的工作状态不正常
- 负载不对称,电源中性点和负载中性点不等位,中性线中有电流,各相电压、电流不对称
- 中性线不装保险,且较粗,保证负载的各相电压接近对称
- 减少中性点位移,减少中性线阻抗
10-5 对称三相电路功率的计算
平均功率:
无功功率:
视在功率:
瞬时功率:
注意:
- φ为各相电压与相电流的相位差(阻抗角),不对称时无意义
- cosφ为各相的功率因数,也可定义为
- 公式计算的使负载吸收的功率,即电源发出的功率
- P、Q、S都是指三相总和
10-6 三相功率的测量
- 三表法:AN、BN、CN各用一功率表,仅适用于三相四线制
- 二表法:AC、BC各用一功率表,仅适用于三相三线制,两表代数和为三相总功率
11 非正弦周期电流电路
11-1 非正弦周期信号
将非正弦周期信号进行傅里叶级数展开:,其中的第二项称为基波分量,第三项称为二次谐波分量
阻抗写成:,其中均由替代
要使输出中不含某频率的分量,一般用并联谐振(阻抗为)阻断或用串联谐振(阻抗为0)短路。
11-2 非正弦周期电流电路的有效值和平均功率
电流的有效值:
电压的有效值:
平均功率:
纯电阻电路平均功率:
11-3 非正弦周期电流的计算
- 对非正弦周期信号进行傅里叶级数分解
- 将各分量分别单独作用
- 将各时域求得的分量叠加
12 二端口网络
二端口网络:有两个端口,且仅含线性阻抗和线性受控源,并满足,
12-2 二端口的方程和参数
二端口网络有两个电压和两个电流
Z参数:用二端口电流表示二端口电压,又称开路阻抗参数
Y参数:用二端口电压表示二端口电流,又称短路路导纳参数
H参数:用表示,又称混合参数
T参数:用端口2的电压电流表示端口1的电源电流,又称传输参数
二端口网络参数的求解方法:先列写电压电流方程,再整理方程为所求参数对应的方程
13 运算放大器
理想运算放大器:倒向输入端与非倒向输入端等电位,输入电流均为0
特性:
- 虚短:等电位
- 虚断:输入电流为0
多半使用结点电压法或回路电流法
14 线性动态电路的复频域分析
F(s)称为f(t)的象函数,f(t)称为F(s)的原函数
电感的运算电路:电感sL和电压源串联 或 电感和电流源并联
电容的运算电路:电容和电压源串联 或 电容sC和电流源并联